

Key takeaways
- It means we need lots of very good, balanced, and varied data.
- Predictions with low confidence will automatically request additional images of this type to be labeled, and predictions with high confidence won’t need additional data.
- Then, it’s easy, the data to be annotated is simply the ones our models most disagree on, which means it is complicated to understand.
We now deal with immense amounts of data thanks to the superpowers of large models, including the famous ChatGPT but also vision models and all other types you may be working with right now.
Indeed, the secret behind those models is not only the large amount of data they are being trained on but also the quality of that data. What does this mean? It means we need lots of very good, balanced, and varied data. And, as data scientists, we all know how complicated and painful it can be to build such a good dataset fast, at large scale and maybe with a limited budget. What if we could have help build that or even have automated help? Well, that is where active learning comes in.
In one sentence, the goal of active learning is to use the least amount of training data to optimize the annotation of your whole dataset and train the best possible model.
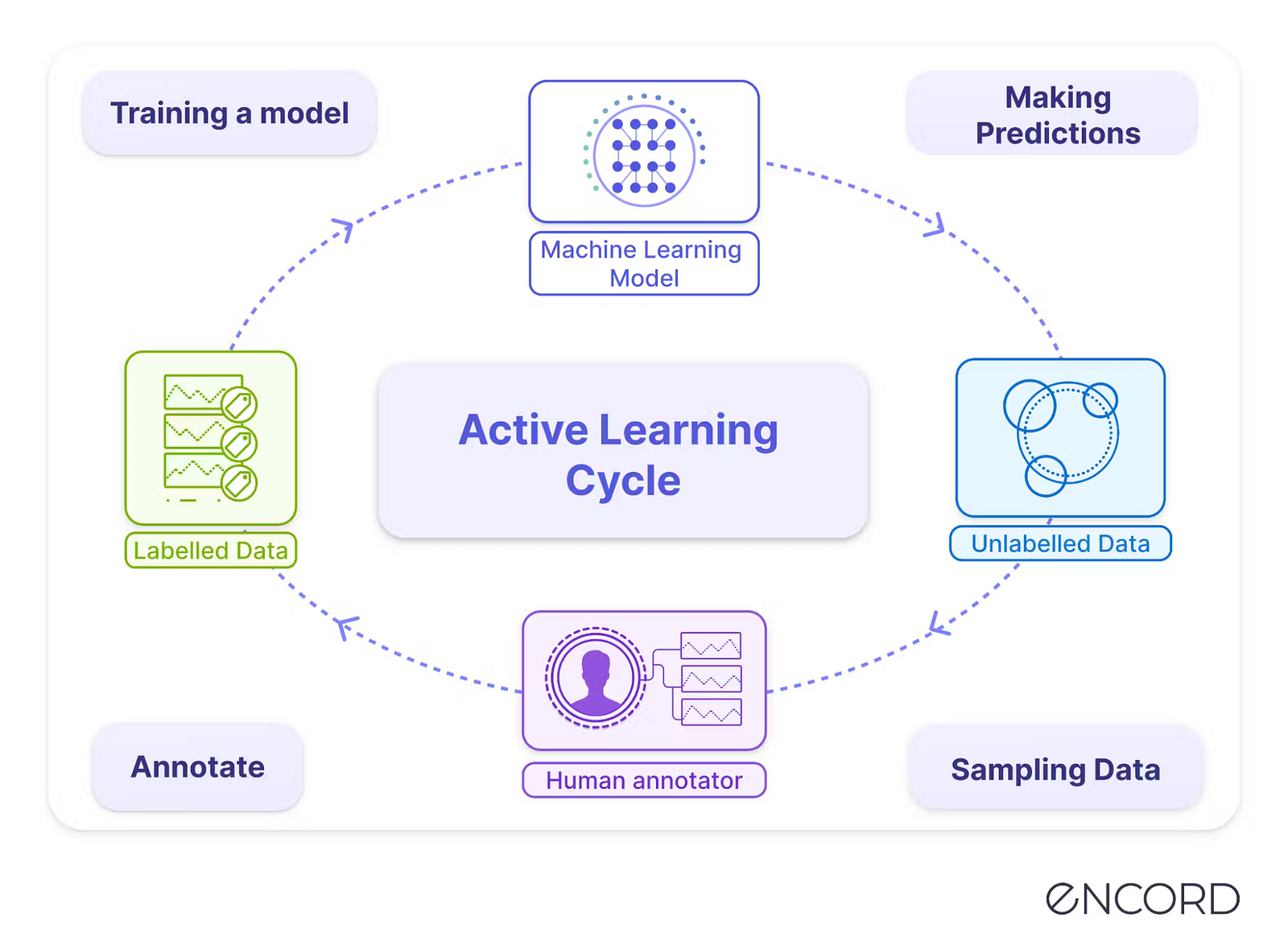
It’s a supervised learning approach that will go back and forth between your model’s predictions and your data. What I mean here is that you may start with a small batch of curated annotated data and train your model with it. You don’t have to wait for your whole millions-of-images dataset to be ready. Just push it out there. Then, using active learning, you can use your model on unseen data and get human annotators to label it. But that is not only it. We can also evaluate how accurate the predictions are and, using a variety of acquisition functions, which are functions used to select the next unseen data to annotate, we can quantify the impact of labeling a larger dataset volume or improving the accuracy of the labels generated, to improve the model’s performance.
Thanks to how you train the models, you can analyze the confidence they have in their predictions. Predictions with low confidence will automatically request additional images of this type to be labeled, and predictions with high confidence won’t need additional data.
So you will basically save time and money by having to annotate fewer images in the end and have the most optimized model possible. How cool is that! Active learning is the most promising approach to working with large-scale datasets.
Representation of active learning. Image from Kumar et al.
There are a few important key notions to remember with active learning. The most important is that it uses humans, which you can clearly see here in the middle of this great representation. It will still require humans to annotate data, which gives you full control over the quality of your model’s prediction; it’s not a complete black box trained with millions of images anymore. You iteratively followed its development and helped it get better when it fails. I believe this feature is what makes it the most important and interesting. Of course, it does have the downside of increasing costs versus unsupervised approaches where you don’t need anyone, but it allows you to limit those costs by only training where the models need it, instead of feeding it as much data as possible and hoping for the best. Moreover, the reduction in time taken to train the model and put it into production often outweighs these costs. And you can use some automatic annotation tools and manually correct it after, again reducing the costs.
Then, obviously, you will have your labeled set of data, which we all know what it is. This labeled set of data is what your current model is being trained on, and the unlabelled set is the data you could potentially use but hasn’t been annotated yet.
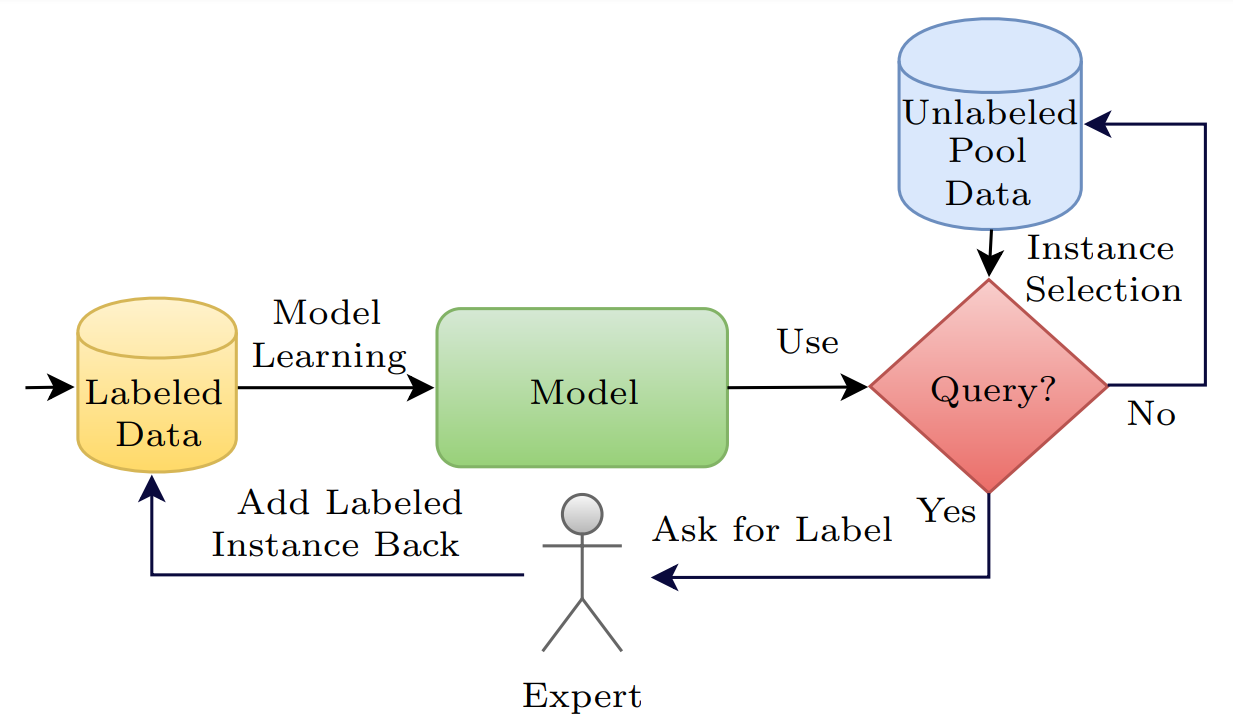
Another key notion is actually the answer to the most important question you may already have in mind: how do you find the bad data to annotate and add to the training? The solution here is called query strategies, and they are essential to any active learning algorithm, deciding which data to label and which not to. There are multiple possible approaches to finding the most informative subsets in our large pool of unlabeled data that will most help our model by being annotated like uncertainty sampling, where you test your current model on your unlabeled data and draw the least confident classified examples to annotate.
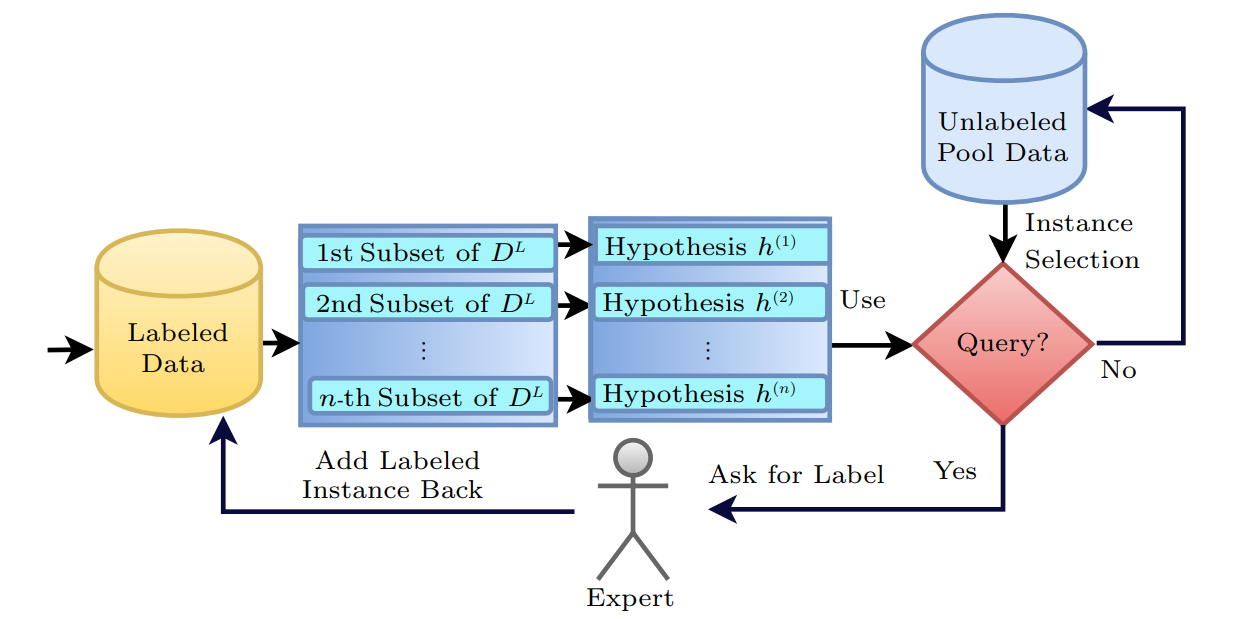
Representation of active learning with the Query by Committee approach. Image from Kumar et al.
Another technique shown here is the Query by Committee or QBC approach. Here, we have multiple models, our committee models.
They will all be trained on a different subset of our labeled data and thus have a different understanding of our problem.

Image by the author.
These models will each have a hypothesis on the classification of our unlabeled data that should be somewhat similar but still different because they basically see the world differently just like us that have different life experiences and have seen different animals in our lives but still have the same concepts of a cat and a dog. Then, it’s easy, the data to be annotated is simply the ones our models most disagree on, which means it is complicated to understand. And we start over by feeding the selected data to our experts and annotating them continuously! This is, of course, a basic explanation of active learning with one example of a query strategy, which is surely the most exciting part. Let me know if you’d like more videos on other machine learning strategies like this! A clear example of the active learning process is when you answer captchas on Google. It helps them identify complex images and build datasets using you and many other people as a committee jury for annotation, building cheap and great datasets while ensuring you are a human, serving two purposes. So next time you are annoyed by a captcha, just think that you are helping AI models progress!
Tune in to the video to learn more with a practical example using a great tool developed by my friends at Encord:
Resources
https://link.springer.com/article/10.1007/s11390-020-9487-4
https://encord.com/blog/active-learning-computer-vision-guide/
https://encord.com/blog/active-learning-the-ml-team-of-the-future/
FAQ
What is Active Learning in AI??
Active learning explained in 5 minutes. It means we need lots of very good, balanced, and varied data.
How should you practice active Learning in AI??
Predictions with low confidence will automatically request additional images of this type to be labeled, and predictions with high confidence won’t need additional data.
What should you avoid while learning active Learning in AI??
You iteratively followed its development and helped it get better when it fails.
How should builders use active Learning in AI??
Then, it’s easy, the data to be annotated is simply the ones our models most disagree on, which means it is complicated to understand.
When does active Learning in AI? become useful in practice?
And, as data scientists, we all know how complicated and painful it can be to build such a good dataset fast, at large scale and maybe with a limited budget.
What should beginners understand about active Learning in AI??
What I mean here is that you may start with a small batch of curated annotated data and train your model with it.
What is the common mistake with active Learning in AI??
You iteratively followed its development and helped it get better when it fails.