

Key takeaways
- Computer vision is useful when the model solves a clear perception task, not only when the demo image looks impressive.
- Data quality, labels, camera conditions, and edge cases usually decide whether a vision system works in the real world.
- The practical test is simple: check the model on messy inputs, not only on the clean examples shown in papers and demos.
Watch the video and support me on YouTube!
If you clicked on this article, you are certainly interested in computer vision applications like image classification, image segmentation,
object detection, and more complex tasks like face recognition, image generation, or even style transfer application. As you may already know, with the growing power of our computers, most of these applications are now being realized using similar deep neural networks, what we often refer to as “artificial intelligence models”. There are some differences between the deep nets used in these different vision applications, but as of now, they use the same basis of convolutions introduced in 1989 by Yann LeCun. The major difference is our computation power coming from the recent advancements of GPUs.
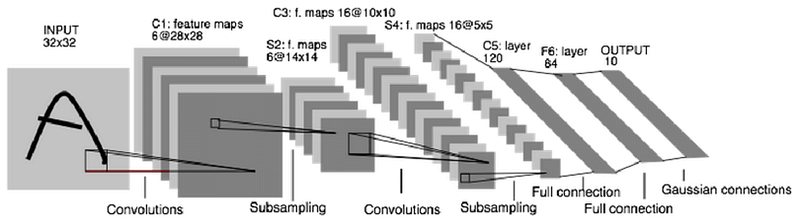
LeNet, (LeCun et al., 1989)
A Quick Introduction to Convolutional Neural Networks
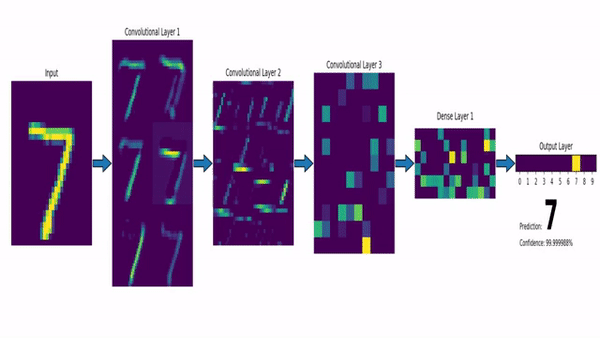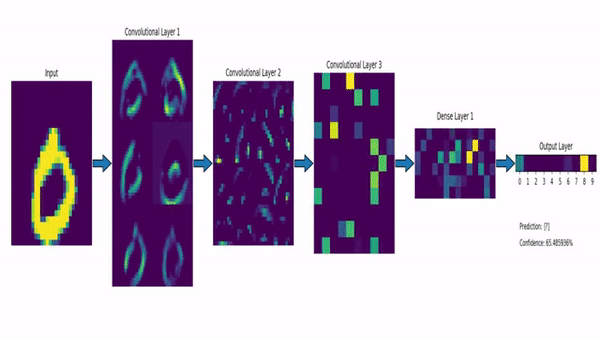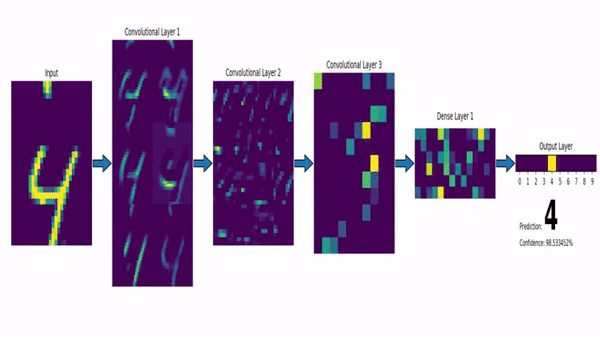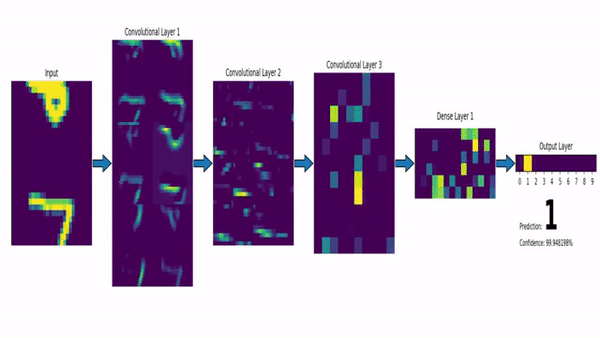
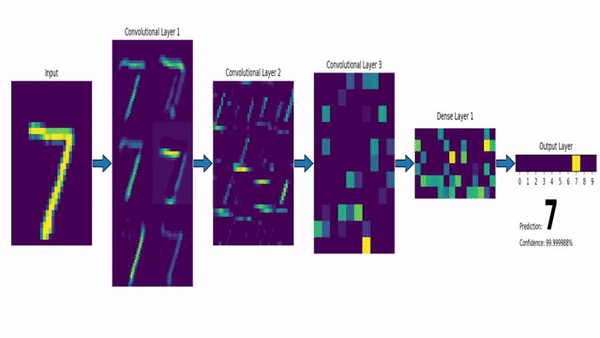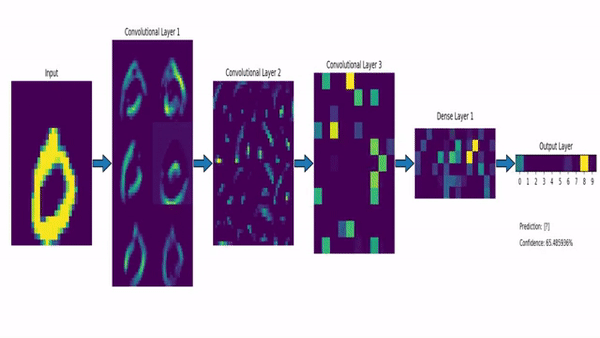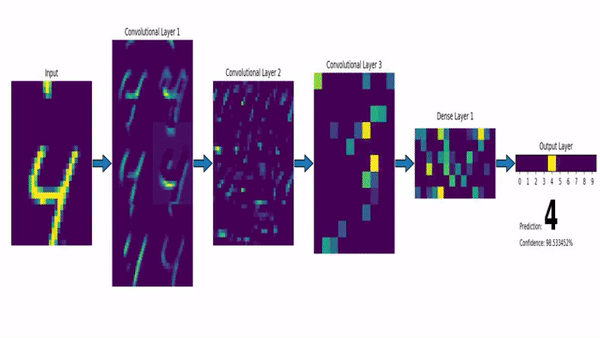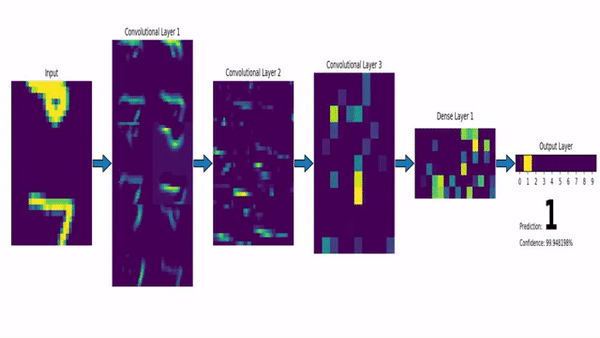
Convolutional Neural Network on the MNIST dataset. Image via msvanjie.
To quickly go over the architecture, as the name says, convolution is a process where an original image, or video frame, which is our input in a computer vision application, is convolved using filters that detect important small features of an image such as edges. The network will autonomously learn filter values that detect important features to match the output we want to have, such as the object’s name in a specific image sent as input for a classification task.
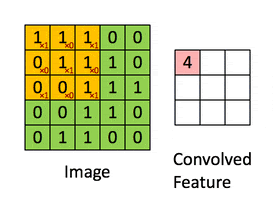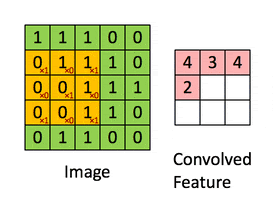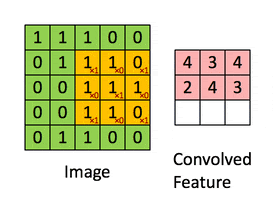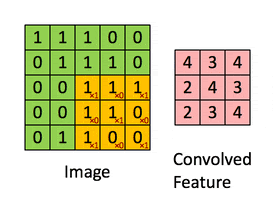
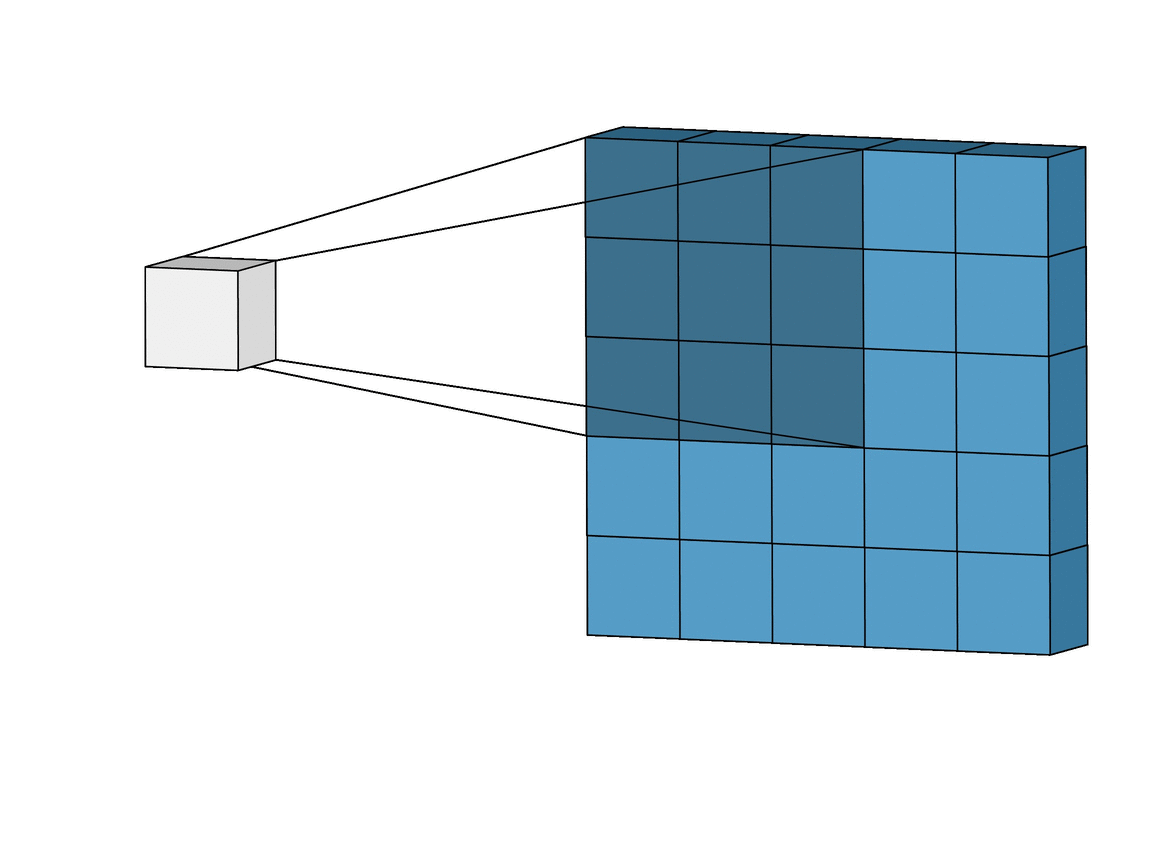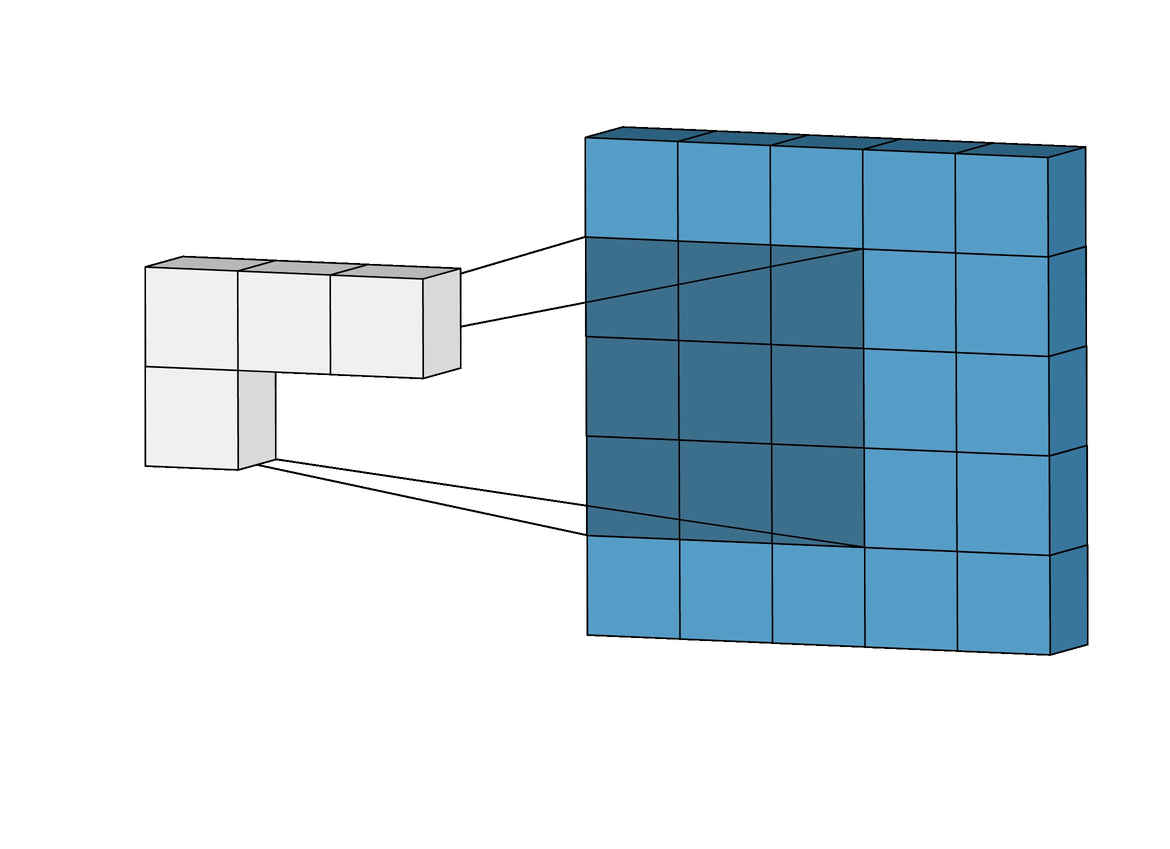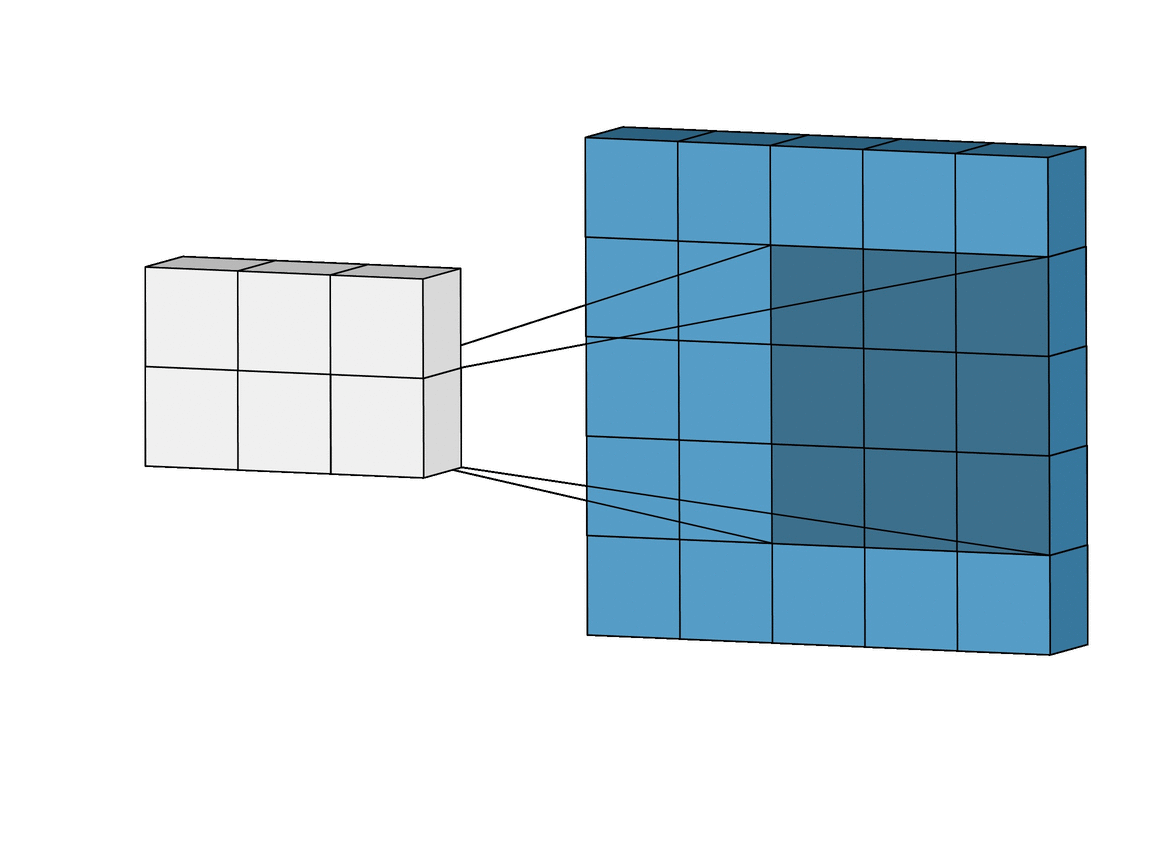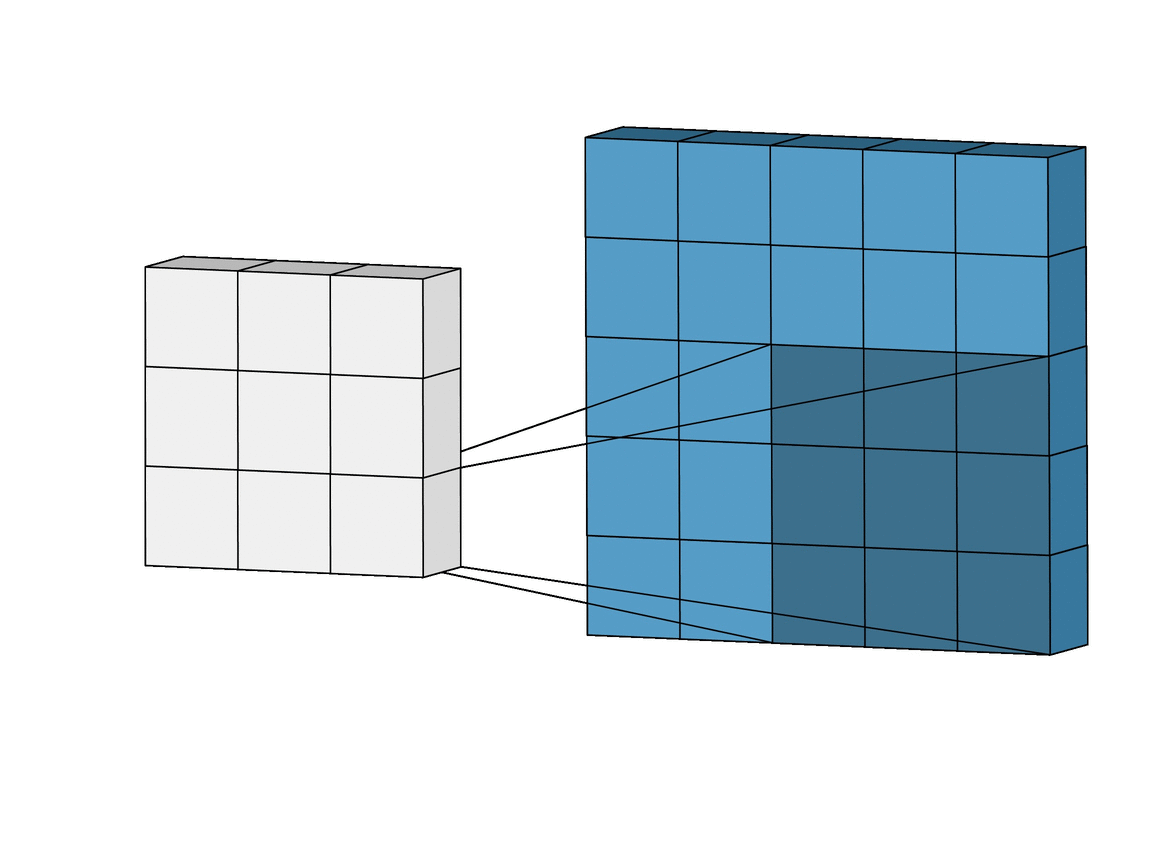
A convolution. Image via Irhum Shafkat
These filters are usually of size 3-by-3 or 5-by-5 pixels squares allowing them to detect the direction of the edge: left, right, up, or down. Just like you can see in this image, the process of convolution makes a dot product between the filter and the pixels it faces. It is basically just a sum of all the filter pixels multiplicated with the values of the image’s pixels at the corresponding positions. Then, it goes to the right and does it again, convolving the whole image. Once it’s done, these convolved features give us the output of the first convolution layer. We call this output a feature map. We repeat the process with many other filters, giving us multiple feature maps—one for each filter used in the convolution process. Having more than one feature map gives us more information about the image. And especially more information that we can learn during training since these filters are what we aim to learn for our task. These feature maps are all sent into the next layer as input to produce many other smaller-sized feature maps again. The deeper we get into the network, the smaller these feature maps get because of the nature of convolutions, and the more general the information of these feature maps becomes. Until it reaches the end of the network with extremely general information about what the image contains disposed over many feature maps, which is used for classification or to build a latent code to represent the information present in the image in the case of a GAN architecture to generate a new image based on this code which we refer to as the encoded information.
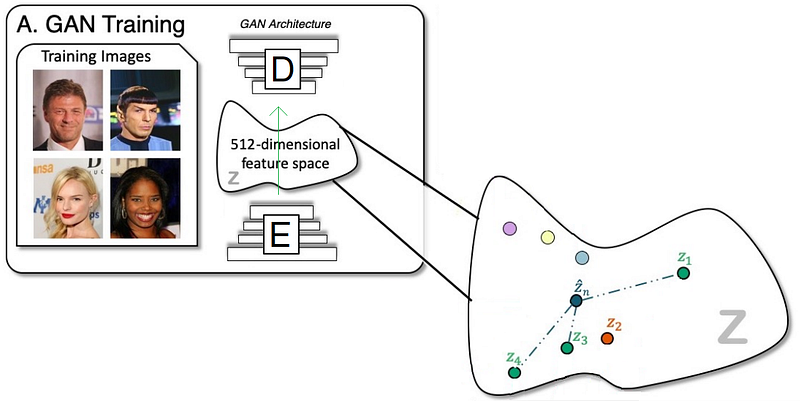
GAN training and latent space representation. Image by the author.
In the example of image classification, simply put, we can say that at the end of the network, these small feature maps contain the information about the presence of each possible class, telling you whether it’s a dog, a cat, a person etc. Of course, this is super-simplified, and there are other steps, but I feel like this is an accurate summary of what’s going on inside a deep convolutional neural network.
If you’ve been following my articles and posts, you know that deep neural networks proved to be extremely powerful again and again, but they also have weaknesses and weaknesses that we should not try to hide. As with all things in life, deep nets have strengths and weaknesses. While strengths are widely shared, the latter is often omitted or even discarded by companies and ultimately by some researchers.
Deep Nets — Strengths and Weaknesses
This paper by Alan L. Yuille and Chenxi Liu aims to openly share everything about deep nets for vision applications, their successes, and the limitations we have to address. Moreover, just like for our own brain, we still do not fully understand their inner workings, which makes the use of deep nets even more limited since we cannot maximize their strengths and limit weaknesses.
As stated by O. Hobert,
it is like a road map that tells you where cars can drive but does not tell you when or where cars are actually driving.
This is another point they discuss in their paper. Namely, what is the future of computer vision algorithms? As you may be thinking, one way to improve computer vision applications is to understand our own visual system better, starting with our brain, which is why neuroscience is such an important field for AI. Indeed, current deep nets are surprisingly different than our own vision system. Firstly, humans can learn from minimal numbers of examples by exploiting our memory and the knowledge we already acquired. We can also exploit our understanding of the world and its physical properties to make deductions, which a deep net cannot do. In 1999 Gopnik et al. explained that babies are more like tiny scientists who understand the world by performing experiments and seeking causal explanations for phenomena, rather than simply receiving stimulus from images like current deep nets.

We, humans, are much more robust as we can easily identify an object from any viewpoint, texture it has, occlusions we may encounter, and novel context. As a concrete example, you can just visualize the annoying Captcha you always have to fill in when logging into a website. This Captcha is used to detect bots since they are awful when there are occlusions like this.

As you can see here, the deep net got fooled by all the examples because of the jungle context and the fact that a monkey is not typically holding a guitar.
This happens because it was certainly not in the training dataset. Of course, this exact situation might not happen that often in real life, even if it’s not in the training dataset.

Yuille, A.L. and Liu, C., (2021).
I will show some more concrete examples that are more relatable and already happened later on. Deep nets also have strengths that we must highlight. They can outperform us for face recognition tasks since humans are not used to, until recently, seeing more than a few thousand people in their whole lifetime. But this strength of deep nets also comes with a limitation where these faces need to be straight, centered, clear, without any occlusions, etc. Indeed, the algorithm could not recognize your best friend at the Halloween party disguised in harry potter, having only glasses and a lightning bolt on the forehead. Where you would instantly recognize him and say, “Wow, that is not very original. It looks like you just put glasses on”. Similarly, such algorithms are extremely precise radiologists… if all the settings are similar to what they have seen during their training, they will outperform any human. This is mainly because even the most expert radiologists have only seen a fairly small number of CT scans in their lives. As they suggest, this superiority of algorithms may also be because they are doing a low-priority task for humans. For example, a computer vision app on your phone can identify the hundreds of plants in your garden much better than most of us reading can, but a plant expert can surely outperform it (and all of us together). But again, this strength comes with a huge problem related to the data the algorithm needs to be this powerful. As they mention and as we often see on Twitter or article titles, there are biases due to the dataset these deep nets are trained on, since
an algorithm is only as good as the dataset it is evaluated on and the performance measures used.
Deep Nets vs. the Human Vision System
This dataset limitation comes with the price that these deep neural networks are much less general-purpose, flexible, and adaptive than our own visual system. They are less general-purpose and flexible in the way that, contrary to our visual system where we automatically perform edge detection, binocular stereo, semantic segmentation, object classification, scene classification, and 3D depth estimation, deep nets can only be trained to achieve one of these tasks. Indeed, simply by looking around, your vision system automatically achieves all these tasks with extreme precision where deep nets have difficulty achieving similar precision on one of them. But even if this seems effortless to us, half of our neurons are at work processing the information and analyzing what is going on.
We are still far from mimicking our vision system even with the current depth of our networks, but is that really the goal of our algorithms? Would it be better to use them as a tool to improve our weaknesses? I couldn’t say. But I am sure that we want to address the deep nets’ limitations that can cause serious consequences rather than omitting them. I will show some concrete examples of such consequences just after introducing these limitations. One of the biggest limitations of deep nets is that they are dependant on data. Indeed, the lack of precision we previously mentioned by deep nets arises mainly because of the disparity between the data we use to train our algorithm and what it sees in real life. As you know, an algorithm needs to see a lot of data to iteratively improve at the task it is trained for. This data is often referred to as a training dataset.
The data dependency problem

Photo by Franki Chamaki on Unsplash
This data disparity between the training dataset and the real world is a problem because the real world is too complicated to accurately be represented in a single dataset, which is why deep nets are less adaptive than our vision system. In the paper, they called this the combinatorial complexity explosion of natural images. The combinatorial complexity comes from the multitude of possible variations within a natural image like the camera pose, lighting, texture, material, background, the position of the objects, etc. Biases can appear at any of these levels of complexity the dataset is missing. You can see how these large datasets now seem very small due to all these factors, considering that having only, let’s say, 13 of these different parameters, and we allow only 1 000 different values for each of them, we quickly jump to this number of different images to represent only a single object: 10^39. The current datasets only cover a handful of these multitudes of possible variations for each object, thus missing most real-world situations that it will encounter in production.
It is also worth mentioning that since the variety of images is very limited, the network may find shortcuts to detecting some objects, as we saw previously with the monkey. It was detecting a human instead of a monkey because of the guitar in front of it. Similarly, you can see that it is detecting a bird here instead of a guitar, probably because the model has never seen a guitar with a jungle background. This is a case called “overfitting to the background context,” where the algorithm does not focus on the right thing and instead finds a pattern in the images themselves rather than on the object of interest. Also, these datasets are all built from images taken by photographs. Meaning that they only cover specific angles and poses that do not transfer to all orientation possibilities in the real world.
Benchmarks
Currently, we use benchmarks with the most complex datasets possible to compare the current algorithms and rate them, which, if you recall, are incomplete compared to the real world. Nonetheless, we are often happy with 99% accuracy for a task on such benchmarks. Firstly, the problem is that this 1% error is determined on a benchmark dataset, meaning that it is similar to our training dataset in the way that it does not represent the richness of natural images. It’s normal because it is impossible to represent the real world in just a bunch of images, it is too complicated, and there are too many situations possible. These benchmarks we use to test our dataset to determine whether or not they are ready to be deployed in the real-world application are not really accurate to determine how well it will *actually* perform, which leads to the second problem that is how it will actually perform in the real world.
Let’s say that the benchmark dataset is huge and most cases are covered, and we really have 99% accuracy. What are the consequences of the 1% of cases where the algorithm fails in the real world? This number will be represented in misdiagnosis, accidents, financial mistakes, or even worse, deaths.
Such cases could be a self-driving car during a heavy rainy day, heavily affecting the depth sensors used by the vehicle, causing it to fail many depth estimations. Would you trust your life to this partially-blind “robotaxi”?
I don’t think I would. Similarly, would you trust a self-driving car at night to avoid driving over pedestrians or cyclists where even yourself had difficulty seeing them? These kinds of life-threatening situations are so broad that it’s almost impossible that they are all represented in the training dataset.
And of course, here I used extreme examples of the most relatable application, but you can just imagine how harmful this could be when the “perfectly-trained and tested” algorithm misclassify your CT scan leading to misdiagnosis just because your hospital has different settings in their scanner, or you didn’t drink the regular amount of water or dye. Anything that would be different from your training data could lead to a major problem in real life, even if the benchmark used to test it says it is perfect. As it already happened, this can lead to people in under-represented demographics being unfairly treated by these algorithms, and even worse. This is why I argue that we must focus on the tasks where the algorithms help us and not where they replace us as long as they are that dependent on data.
The difference between the diversity in a training dataset vs. real-world images. Image by the author.
This brings us to the two questions they highlight,
(I) How can we efficiently test these algorithms to ensure that they work in these enormous datasets if we can only test them on a finite subset?
And
(II) How can we train algorithms on finite sized datasets so that they can perform well on the truly enormous datasets required to capture the combinatorial complexity of the real world?
In the paper, they suggest to “rethink our methods for benchmarking performance and evaluating vision algorithms.” And I agree entirely. Especially now, where most applications are made for real-life uses instead of only academic competitions, it is crucial to get out of these academia evaluation metrics and create more appropriate evaluation tools. We also have to accept that data bias exists and that it can cause real-world problems. Of course, we need to learn to reduce these biases but also to accept them. Biases are inevitable due to the combinatorial complexity of the real world that cannot be realistically represented in a single dataset of images yet. Thus, focusing our attention, without any play on words with transformers,
on better algorithms that can learn to be fair even when trained on such “incomplete” datasets rather than having bigger and bigger models trying to represent the most data possible.
Even if it may look like it, this paper was not a criticism of current approaches.
Instead, it is an opinion piece motivated by discussions with other researchers in several disciplines. As they state,
we stress that views expressed in the paper are our own and do not necessarily reflect those of the computer vision community.
But I must say, this was a very interesting read, and my views are quite similar.
They also discuss many important innovations that happened over the last 40 years in computer vision that is worth reading. As always, the link to the paper is in the references below, and you should definitely read it. I couldn’t stress it more!
To end on a more positive note, we are now nearly a decade into the revolution of deep neural networks that started in 2012 with AlexNet in the Imagenet competition. Since then, there has been immense progress on our computation power and the deep nets architectures like the use of batch normalization, residual connections, and, more recently, self-attention.
Researchers will undoubtedly improve the architecture of deep nets, but we shall not forget that there are other ways to achieve intelligent models than “Going Deeper…” and using more data. Of course, these ways are yet to be discovered. If this history of deep neural networks sounds interesting to you, I wrote an article on one of the most interesting architecture, along with a short historical review of deep nets. I’m sure you’ll enjoy it!
[
State of the Art Convolutional Neural Networks (CNNs) Explained — DenseNets
Convolutional neural networks also referred to as CNNs are the most used type of neural network and the best for any computer vision applications. Once you understand these, you are ready to dive…
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
Yuille, A.L., and Liu, C., 2021. Deep nets: What have they ever done for vision?. International Journal of Computer Vision, 129(3), pp.781–802, https://arxiv.org/abs/1805.04025.
FAQ
What is AI in computer vision?
AI in computer vision means using models to understand images or video, including classification, detection, segmentation, tracking, and generation.
Why does data matter so much in computer vision?
Vision models learn from visual patterns, so labels, lighting, camera angles, backgrounds, and rare edge cases can change the result more than a new architecture.
Where is computer vision useful in practice?
It can help with inspection, medical imaging support, robotics, autonomous systems, retail analytics, creative tools, and photo or video organization.
What should builders test before trusting a vision model?
Test bad lighting, occlusion, blur, unusual angles, underrepresented groups, changing environments, and the exact camera setup used in production.
How should beginners start learning computer vision?
Start with image classification and object detection, then move into segmentation, embeddings, multimodal models, and evaluation on your own images.
What does a convolutional filter learn to detect?
Early filters often respond to small patterns such as edges; deeper layers combine those feature maps into more useful visual representations.