

The short version
ADOP synthesizes new camera views from photos, camera parameters, and a sparse point cloud rather than recording a conventional video. A rasterizer creates incomplete views at several resolutions, a U-Net renderer fills them into HDR images, and a tone mapper produces displayable LDR output. Results depend heavily on point-cloud quality, and generated views containing people also raise consent, authenticity, and misuse concerns.
Watch the video!
Believe it or not, what you see is actually not a video.
It was made from a simple collection of photos and transformed into a 3-dimensional model! The best thing is that it didn’t even need a thousand pictures, only a few, and could create the missing information afterward! As you can see, the results are amazing, but they aren’t easy to generate and requires a bit more than only the images as inputs. Let’s rewind a little….
Imagine you want to generate a 3D model out of a bunch of pictures you took. Instead of only using these pictures, you will also need to feed it a point cloud.

A point cloud image of a torus. Image from Wikipedia.
A point cloud is basically the simplest form of a 3D model. You can see it as a draft version of your 3D model represented by sparse points in 3D space that looks just like this. These points also have the appropriate colors and luminance from the images you took. A point cloud is easily made using multiple photos triangulating the corresponding points to understand their position in 3D space.
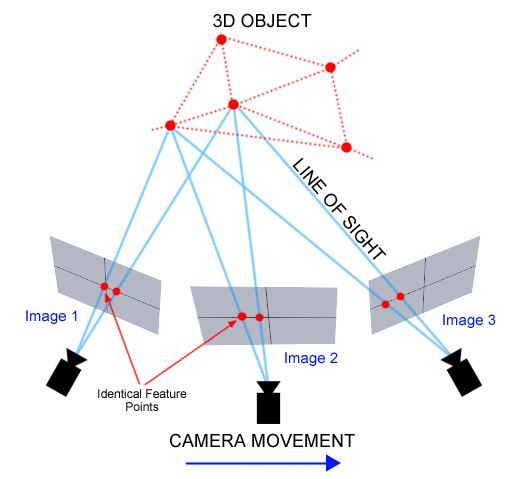
Point cloud generation from multiple camera views. Image from The Haskins Society.
By the way, if you find this interesting, I invite you to follow the blog for free and share the knowledge by sending this article to a friend. I’m sure they will love it, and they will be grateful to learn something new because of you! And if you don’t, no worries, thank you for watching!

The 3 modules. Image from Rückert, D. et al., (2021), ADOP.
First, you will take your images and point cloud and send it to the first module, the rasterizer. Remember, the point cloud is basically our initial 3D reconstruction, our first draft. The rasterizer will produce the first low-quality version of your 3D image using the camera parameters from your pictures and the point cloud. It will basically try to fill in the holes in your initial point cloud representation approximating colors and understanding depth.
This is a very challenging task as it has to understand the images that do not cover all the angles and the sparse point cloud 3D representation. It might not be able to fill in the whole 3D image intelligently due to this lack of information, which is why it looks like this.

First rendering quality. Image from Rückert, D. et al., (2021), ADOP.
The still unknown pixels are replaced by the background, and this is all still very low resolution containing many artifacts. Since it is far from perfect, this step is made on multiple resolutions to help the next module with more information.
The second module is the Neural renderer. This neural renderer is just a U-net like we covered numerous times on my channel to take an image as input and generate a new version of it as output. It will take the incomplete renderings of various resolutions as images, understand them, and produce a new version of each image in higher definition filling the holes. This will create high-resolution images for all missing viewpoints of the scene. Of course, when I say to understand them, it means that the two modules are trained together to achieve this. This neural renderer will produce HDR novel images of the rendering, or High Dynamic Range images, which are basically more realistic, high-resolution images of the 3D scene with better lighting. The HDR results basically look like images of the scene in the real world. This is because the HDR images will have a much broader range of brightness than traditional jpeg encoded images where the brightness can only be encoded on 8 bit with a 255:1 range, so it won’t look great if encoded in a similar format.
A third and final module, the Tonemapper, is introduced to take this broader range and learn an intelligent transformation to fit the 8-bit encoding better. This third module aims to take these HDR novel images and transform them into LDR images covering the whole scene, our final outputs. The LDR images are low Dynamic Range images and will look much better with traditional image encodings. This module basically learns to mimic digital cameras’ physical lens and sensor properties to produce similar outputs from our previous real-world-like images.
The 3 modules. Image from Rückert, D. et al., (2021), ADOP.
There are basically four steps in this algorithm:
1. Create a point cloud from your images to have a first 3D rendering of the scene.
2. Fill in the missing holes of this first rendering as best as possible using the images and camera information. And do this for various image resolutions.
3. Use these various image resolutions of the 3D rendering in a U-Net to create high-quality HDR images of this rendering for any viewpoint.
4. Transform the HDR images into LDR images for better visualization.
And voilà! You have your amazing-looking videos of the scene just like we saw at the beginning of the video linked above. As they mention, there are some limitations. One of which is the fact that they are highly dependent on the quality of the point cloud given for obvious reasons. Also, if the camera is very close to an object or the point cloud too sparse, it may cause holes like this one in the final rendering. Still, the results are pretty incredible, considering the complexity of the task! We’ve made immense progress in the past year! You can take a look at the videos I made covering other neural rendering techniques less than a year ago and compare the quality of the results. It’s crazy!

Of course, this was just an overview of this new paper attacking this super interesting task in a novel way. I invite you to read their excellent paper for more technical detail about their implementation and check their Github repository with pre-trained models. Both are linked in the references below. Thank you very much for reading the whole article!
Directly from my newsletter: The AI Ethics’ Perspective by Frédérique Godin

An important question which typically acts as the starting point of an ethical reflection is ‘’should we?’’ Should we do x,y,z? Obviously, it depends.
The first thing that came to mind while I watched this video was: ‘’What if there were humans involved?’’ Indeed, in this case, there are no high stakes in generating images of boats or parks… unless there are people in it.
I want to emphasize on something here. Not every model is suitable for every situation. A rather seemingly sound model can lead to grave ethical implications, and the important task to foresee these possibilities is sometimes complex and requires imagination (and humility, but we’ll talk about that another time perhaps).
Ethical and technical are intrinsically intertwined. Indeed, part of the ethicality of a model or software lies in its technicality. A relevant technical component here is data. Is the data diverse enough? Where does the data come from? How many data points do we have? Now, with these questions in mind (and there are more), let’s try to think about what could happen should this model be used to generate images with humans in them.
A poorly diverse dataset could lead to the generation of homogenous images in which only a certain portion of the population is represented. This would trigger the notion of biases, which we are all becoming acquainted with, but it would also potentially alter our capacity to reliably represent reality.
What I mean by that is this: the model can’t generate things it has not been trained on, things it doesn’t know. Now the reality is filled with diversity, and a lot of it. Should we have a very restricted amount of poorly diverse data from which to extrapolate and generate images, chances are the deep net would ‘’fill the hole’’ quite clumsily, which could lead to harmful and discriminatory representations of people, or no representation of minorities at all. Now we can’t erase people from reality because the tech is not there yet, that’s highly invalidating for the unrepresented and unethical.
On a more personal note, I believe we ought to be careful with the tech we deploy and the place it occupies in our lives. This might sound far-fetched, but I am wary of living in a digitalized environment produced by algorithms. This is because prediction is not the truth, and I am afraid that this is about to change.
So, in this case, do we think this kind of model could be used in ways that are detrimental for individuals? Clearly, yes.
And thus, should we use this kind of model when humans are involved? Maybe not.
- AI Ethics segment by Frédérique Godin, M. Sc.
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
- Follow me here or on medium
- Want to get into AI or improve your skills, read this!
References
- Rückert, D., Franke, L. and Stamminger, M., 2021. ADOP: Approximate Differentiable One-Pixel Point Rendering. https://arxiv.org/pdf/2110.06635.pdf.
- Code: https://github.com/darglein/ADOP
FAQ
How can a model create a smooth view from only a few photos?
It uses the available images to infer a three-dimensional scene, then renders new viewpoints that connect the original camera positions.
Is the result a conventionally recorded video?
No. The apparent camera movement is synthesized from a 3D representation built from a collection of still photographs.
Why does image encoding matter for the result?
Different dynamic ranges preserve visual information differently, so the representation must fit the source images and the rendering pipeline.
What ethical concern appears when generated scenes include people?
A technically convincing system can create views that were never recorded, raising consent, authenticity, and misuse questions when people are represented.
How should teams assess a model like this before deploying it?
Evaluate both reconstruction quality and plausible misuse, especially whether generated human imagery could be mistaken for a real recording.
What does the point cloud contribute to the reconstruction?
It provides a sparse first draft of the scene's 3D geometry, colors, and camera relationships. If that draft is poor or too sparse, the final rendering can leave visible holes.