

The short version
BANMo reconstructs an animatable 3D model of a deforming subject from a few casually recorded videos. A NeRF-like network learns color, density, and canonical embeddings while using camera viewpoints and frames to combine shape, appearance, and articulation in a shared canonical space. That representation can then apply a requested pose while keeping learned correspondences coherent across the different observations.
Watch the video and see more results!
If you are in VFX, game development, or creating 3D scenes, this new AI model is for you. I wouldn’t be surprised to see this model or similar approaches in your creation pipeline very shortly, allowing you to spend much less time, money, and effort on making 3D models. Just look at that…

Left: Input videos; Right: Reconstruction at each time instance. Correspondences are shown as the same colors. Image from the authors’ project page.
Of course, it’s not perfect, but that was done instantly with a casual video taken from a phone. It didn’t need an expensive multi-camera setup or complex depth sensors. One of the beauties behind AI: making complex and costly technologies available for startups or single individuals to create projects with professional quality results. Just film an object and transform it into a model you can import right away. You can then fine-tune the details if you are not satisfied, but the whole model will be there within a few seconds!
What you see above are the results from an AI model called BANMo, recently shared at the CVPR event I attended. I’ll be honest, they got my attention because of the cats, too. Still, it wasn’t completely clickbait. The paper and approach are actually pretty awesome. It isn’t like any NeRF approach to reconstructing objects in 3D models. BANMo tackles a task we call articulated 3D shape reconstruction, which means it works with videos and pictures to model deformable objects, and what is more deformable than a cat? And what’s even cooler than seeing the results is understanding how it works…
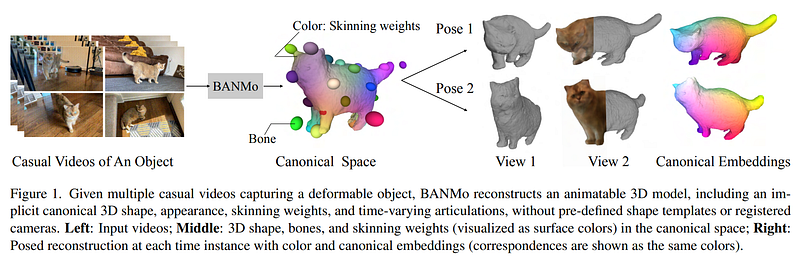
Image from the paper.
The model starts with a few casually taken videos of the object you want to capture, showing how it moves and deforms itself. That’s where you want to send the video of your cat slurping into a vase!
BANMo takes those videos to create then what they refer to as a canonical space. This initial result will give you information about the object’s shape, appearance, and articulations. It is the model’s understanding of your object’s shape, how it moves through space and where it belongs between a brick and a blob, described from those big balls and various colors.
It then takes this 3D representation and applies any pose you want, simulating the cat’s behavior and articulations as close to reality as possible.
Seems like magic, doesn’t it? That’s because we’re not done here. We quickly went from a video to the model, but this is where it becomes interesting.
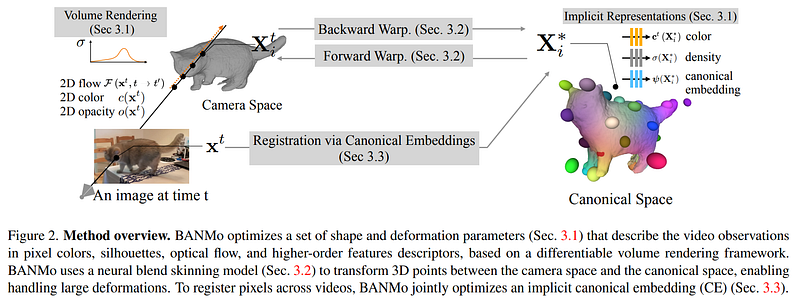
Image from the paper.
So what do they use to go from images of a video to such a representation in this canonical space? You guessed it: a NeRF-like model!
If you are not familiar with this approach, I’d strongly invite you to watch one of the many videos I made covering them and come back for the rest.
In short, the NeRF-inspired method will have to predict three essential properties for each 3-dimensional pixel of the object, as you see here: color, density, and a canonical embedding using a neural network trained for that. To achieve a 3D model with realistic articulations and movement, BANMo uses the camera’s spacial location and multiple frames to understand the ray from which it is filming, allowing it to reconstruct and improve the 3D model iteratively through all frames of the video, similar to what we would do to understand an object, move it around and look at it in all directions.
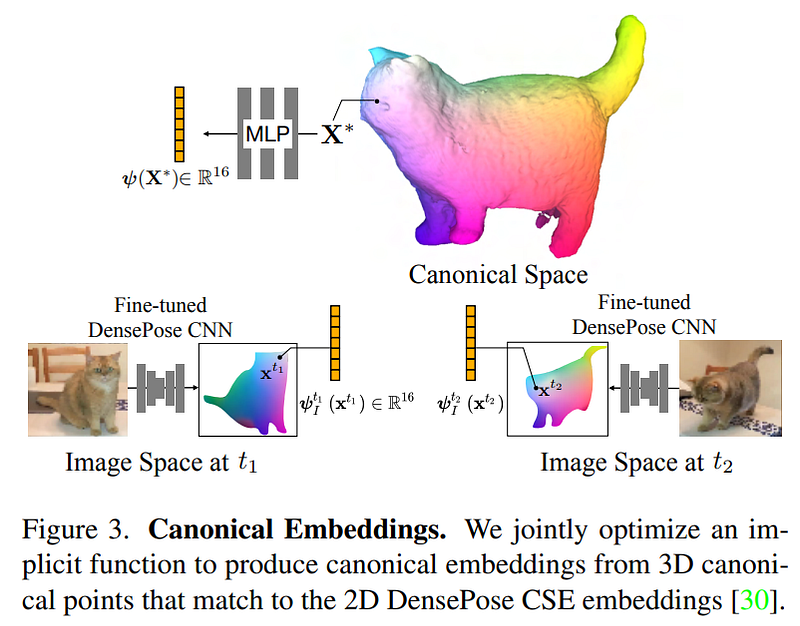
Image from the paper.
This part is done automatically by observing the videos, thanks to the canonical embedding we just mentioned. This embedding will contain all necessary features of each part of the object to allow you to query with a new desired position for the object enforcing a coherent reconstruction given observations. It will basically map the wanted position from the picture up to the 3D model with the correct viewpoints and lighting conditions and provide cues for the needed shape and articulations.
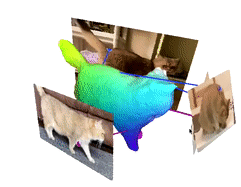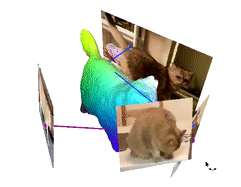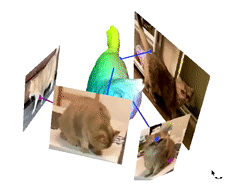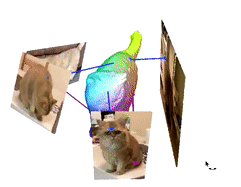
Image from the authors’ project page.
One last thing to mention is our colors. Those colors represent the cat’s body attributes shared in the different videos and images we used. This is the feature we will learn and look at to take valuable information from all videos and merge them into the same 3D model to improve our results.
And voilà!
You end up with this beautiful 3D deformable colory cat you can use in your applications!

Image from the authors’ project page.
Of course, this was just an overview of BANMo, and I invite you to read the paper for a deeper understanding of the model.
References
► Project page: https://banmo-www.github.io/
► Paper: Yang, G., Vo, M., Neverova, N., Ramanan, D., Vedaldi, A. and Joo, H., 2022. Banmo: Building animatable 3d neural models from many casual videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 2863–2873).
► Code: https://github.com/facebookresearch/banmo
FAQ
What does BANMo reconstruct?
BANMo builds an animatable 3D model of a deformable subject from ordinary photos and videos.
What does articulated 3D reconstruction mean?
It models both a subject's shape and how connected parts bend or move over time.
Why are animals difficult to reconstruct?
Their bodies deform, viewpoints change, and fur or fast motion can hide reliable visual correspondences.
Does BANMo require a professional capture rig?
No. The showcased results can start from casual footage, including video recorded with a phone.
Is the reconstructed model always perfect?
No. Casual footage makes the method accessible, but occlusion, blur, and missing views can still limit quality.