
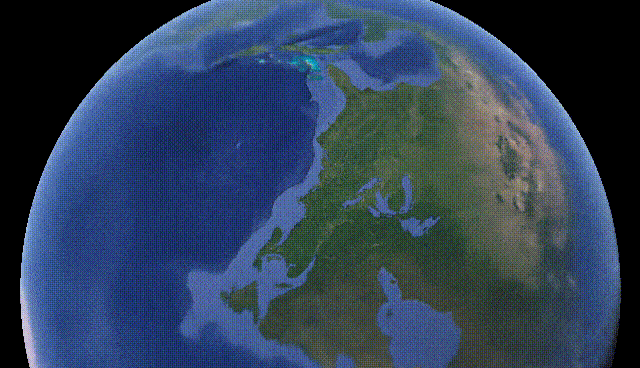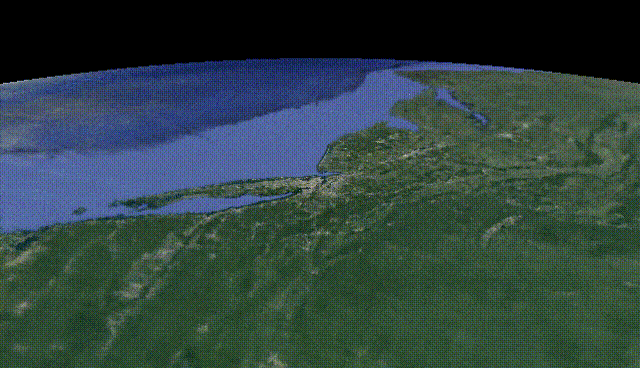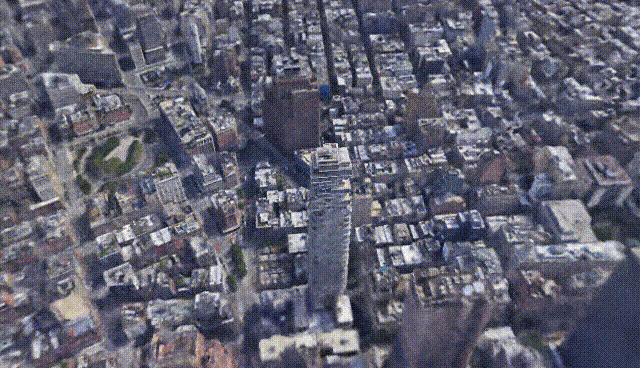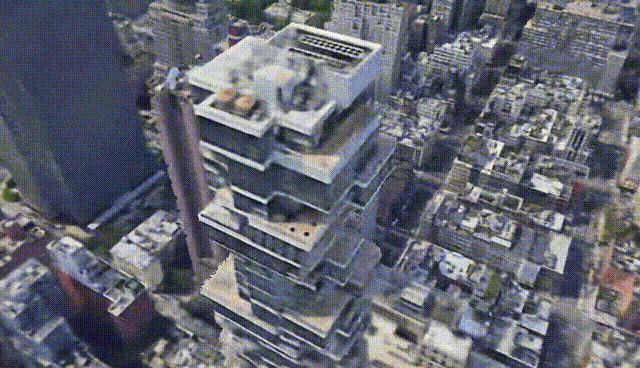
Last year we saw NeRF, NeRV, and other networks able to create 3D models and small scenes from images using artificial intelligence. Now, we are taking a small step and generating a bit more complex models: whole cities. Yes, you’ve heard that right, this week’s paper is about generating city-scale 3D scenes with high-quality details at any scale. It works from satellite view to ground-level with a single model. How amazing is that?! We went from one object that looked okay to a whole city in a year! What’s next!? I can’t even imagine.
The model is called CityNeRF and grows from NeRF, which I previously covered on my channel. NeRF is one of the first models using radiance fields and machine learning to construct 3D models out of images. But NeRF is not that efficient and works for a single scale. Here, CityNeRF is applied to satellite and ground-level images at the same time to produce various 3D model scales for any viewpoint. In simple words, they bring NeRF to city-scale. But how?
I won’t be covering how NeRF works since I have already done this in an article if you haven’t heard of this model yet. Instead, I’ll mainly cover the differences and what CityNeRF brings to the initial NeRF approach to make it multi-scale.
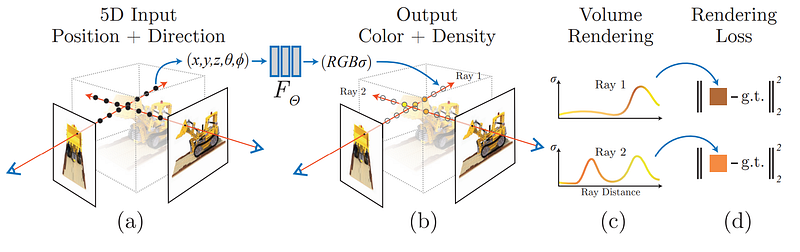
An overview of NeRF. Image from the paper.
Here, instead of having different pictures a few centimeters apart, they have pictures from thousands of kilometers apart, ranging from satellites to pictures taken on the road. As you can see, NeRF alone fails to use such drastically different pictures to reconstruct the scenes. In short, using the weights of a multilayer perceptron, a basic neural network, NeRF will process all images knowing their viewpoint positions in advance. NeRF will find each pixel’s colors and density using a ray from the camera. So it knows the cameras’ orientations and can understand depths and corresponding colors using all the arrays together. Then, this process is optimized for the convergence of the neural network using a loss function that will get us closer to the ground truth while training, which is the real 3D model that we are aiming to achieve.
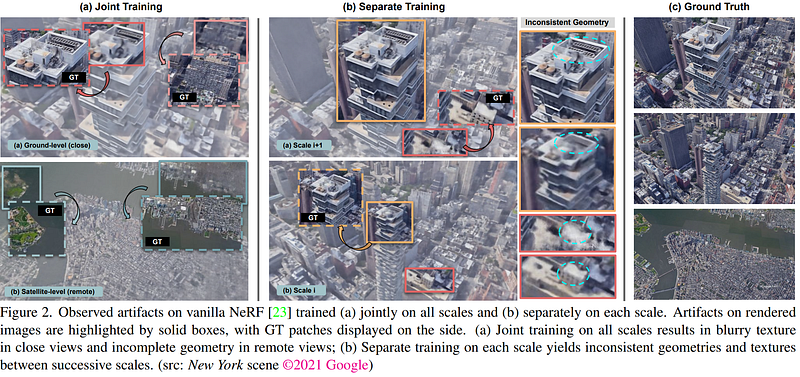
Image from CityNeRF’s paper.
As you can see above, the problem is that the quality of the rendered scene is averaged at the most represented distances and makes specific viewpoints look blurry. Especially because we typically have access to much more satellite imagery than close views. We can try to fix this by training the algorithm with different scales independently, but as they explain, it causes significant discrepancies between successive scales. So you wouldn’t be able to zoom in and have a fluid, nice-looking 3D scene at all times.
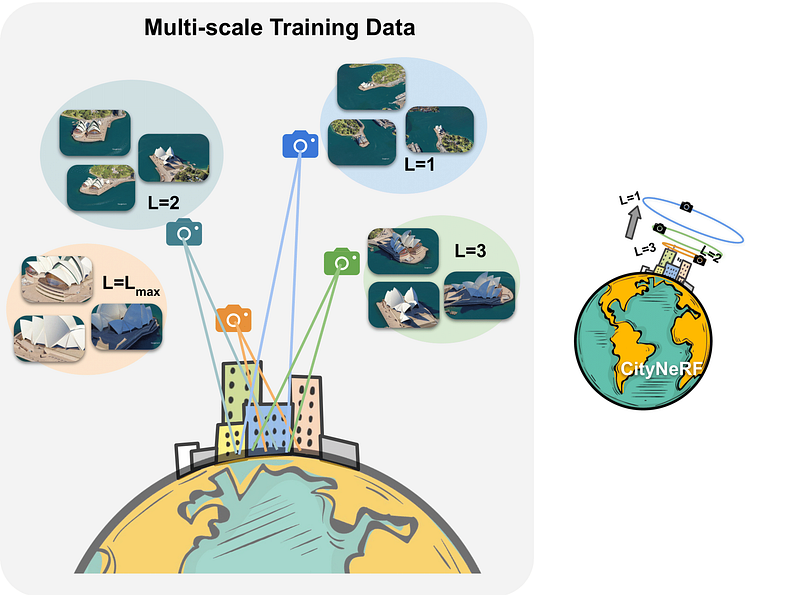
The difference with scales using L variable. Image from CityNeRF’s paper.
Instead, they train their model in a progressive manner. Meaning that they are training their model in multiple steps independently, where each new step starts from the learned parameters of the previous step. These steps are for specific resolutions based on the camera distance from the object of interest, here demonstrated with L.
So each step will have its preprocessed pack of images to be trained on and further improved by the following steps. Starting from far satellite images to more and more zoomed in, the model can add details and make a better foundation over time.
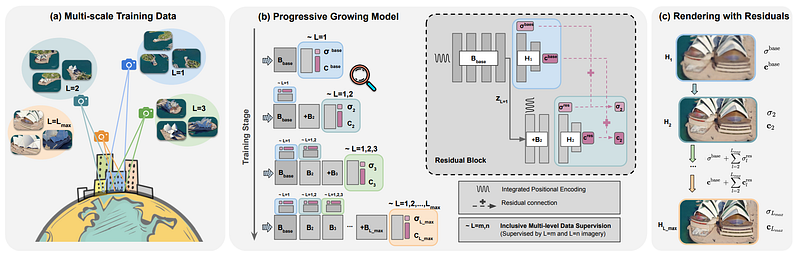
Progressive multi-scale training overview. Image from CityNeRF’s paper.
As shown here, they start by training the model on L1, the farthest view, and end up with the ground-level images, always adding to the network and fine-tuning the model from the learned parameters step to different scales. So this simple variable L controls the level-of-detail, and the rest of the model stays the same for each stage compared to having a pyramid-like architecture for each scale as we typically see. The rest of the model is basically an improved and adapted version of NeRF to this task.
You can learn more about all the details of the implementations and differences with NeRF in their great paper linked in the description below! And the code will be available soon for you to try it out if interested.
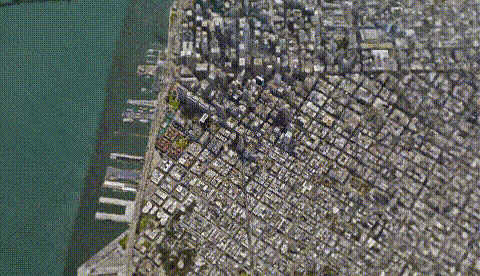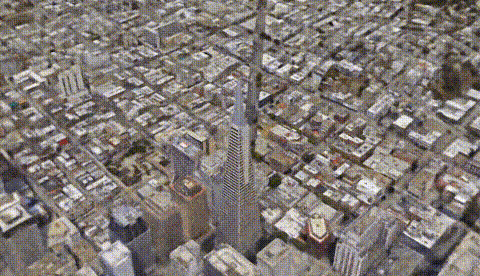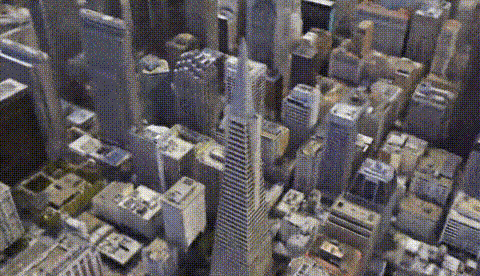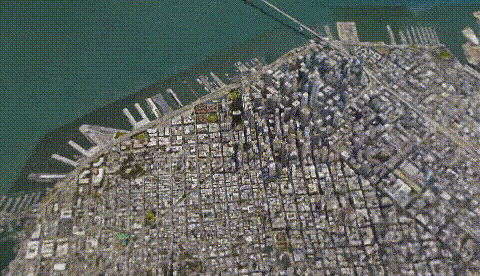
Los Angeles. Image from CityNeRF’s website.
And voilà! This is how they enabled NeRF to be applied to city-scale scenes with amazing results! It has incredible industrial potential, and I hope to see more work in this field soon! Thank you for reading, and if you’re not following me yet, please consider clicking on the little button. It’s free, and you’ll learn a lot! I promise ;p
And I will be sharing a couple of special articles for the end of the year.
Stay tuned!

If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribing to my channel on YouTube if you like the video format.
- Follow me here or on medium
- Want to get into AI or improve your skills, read this!
References
- Xiangli, Y., Xu, L., Pan, X., Zhao, N., Rao, A., Theobalt, C., Dai, B. and Lin, D., 2021. CityNeRF: Building NeRF at City Scale. https://arxiv.org/pdf/2112.05504.pdf
- Project link: https://city-super.github.io/citynerf/
- Code (coming soon): https://city-super.github.io/citynerf/
FAQ
What problem does CityNeRF solve?
CityNeRF represents large urban scenes in 3D while preserving useful detail across very different viewing distances.
How large is the supported viewing range?
The same model can render views ranging from satellite scale down to ground level.
What controls the level of detail?
A level variable selects the appropriate stage of detail without requiring a separate model for every scale.
How is this different from a typical image pyramid?
The model changes its level setting while keeping a shared structure instead of maintaining an independent architecture per scale.
What should readers understand before CityNeRF?
A basic understanding of neural radiance fields helps explain how images and camera viewpoints become a rendered 3D scene.