

The short version
ClipCap generates an image caption by translating CLIP’s visual encoding into prefix vectors that GPT-2 can understand. CLIP supplies a semantic representation of the picture, a learned mapping network reshapes it into word-embedding-sized vectors, and GPT-2 writes the description. The researchers tested an MLP and a Transformer for the mapping, with the Transformer better suited to the pretrained language model.
We’ve seen AI generate images from other images using GANs. Then, there were models able to generate questionable images using text. In early 2021, DALL-E was published, beating all previous attempts to generate images from text input using CLIP, a model that links images with text as a guide. A very similar task called image captioning may sound really simple but is, in fact, just as complex. It is the ability of a machine to generate a natural description of an image. Indeed, it is almost as difficult as the machine needs to understand the image and the text it generates, just like in text-to-image synthesis.

Caption generated: A bunch of bananas sitting on top of a table
It’s easy to simply tag the objects you see in the image. This can be done using a classic classifier model. But it is quite another challenge to understand what’s happening in a single 2-dimensional picture. Humans can do it quite easily since we can interpolate from our past experience, and we can even put ourselves in the place of the person in the picture and quickly get what’s going on. This is a whole other challenge for a machine that only sees pixels. Yet, the researchers published an amazing new model that does this extremely well.
As the researchers explicitly said, “image captioning is a fundamental task in vision-language understanding”, and I entirely agree. The results are fantastic, but what’s even cooler is how it works, so let dive into the model and its inner workings a little…

Caption generated: Students enjoing the cherry blossoms
In this case, the researchers used CLIP to achieve this task. If you are not familiar with how CLIP works or why it is so fantastic, I’d strongly invite you to read one of the many articles I made covering it. In short, CLIP links images to text by encoding both types of data into one similar representation where they can be compared. This is just like comparing movies with books using a short summary of the piece. Given only such a summary, you can tell what it’s about and compare both, but you have no idea whether it’s about a movie or a book. In this case, the movies are images, and the books are text descriptions.
Then, CLIP creates its own summary to allow simple comparisons between both pieces using distance calculation on bits differences. You can already see how CLIP seems perfect for this task, but it requires a bit more work to fit our needs here.
Here CLIP will simply be used as a tool to compare text inputs with images inputs, so we still need to generate such a text that could potentially describe the image. Instead of comparing the text to images with CLIP’s encodings,
they will simply encode the image using CLIP’s network and use this generated encoded information as a way to guide a future text generation process using another model.
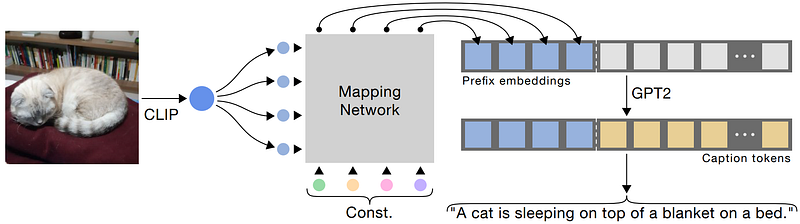
The ClipCap Model. Image from the paper.
Such a task can be performed by any language model like GPT-3, which could improve the results but the researchers opted for its predecessor, GPT-2, a smaller and more intuitive version of the powerful OpenAI model. They are basically conditioning the text generation from GPT-2 using CLIP’s encodings. So CLIP’s model is already trained, and they used a pre-trained version of GPT-2 that they will further train using the CLIP’s encodings as a guide to orient the text generation. It is not that simple since they still need to adapt the CLIP’s encoding to a representation that GPT-2 can understand, but it isn’t that complicated either. It will simply learn to transfer the CLIP’s encoding into multiple vectors with the same dimension as a typical word embedding.
This step of learning how to match CLIP’s outputs to GPT-2’s inputs is the step that will be taught during training as both GPT-2 and CLIP are already trained and powerful models to do their respective tasks. So you can see this as a third model learning, called a mapping network, with the sole responsibility of translating one’s language into the other, which is still a challenging task. If you are curious about the actual architecture of such a mapping network, they tried with both a simple Multi-Layer Perceptron or MLP and a transformer architecture, confirming that the latter is more powerful to learn a meticulous set of embeddings that will be more appropriate for the task when using powerful pre-trained language models. If you are not familiar with transformers, you should take 5 minutes to read the article I made covering them, as you will only more often stumble upon this type of network in the near future.
This model is very simple and extremely powerful. Just imagine having CLIP merged with GPT-3 in such a way. We could use such a model to describe movies automatically or create better applications for blind and visually impaired people. That’s extremely exciting for real-world applications! Of course, this was just a simple overview of this new model, and you can find more detail about the implementation in the paper linked in the description below. I hope you enjoyed the article, and if so, please take a second to share it with a friend that could find this interesting.
Thank you for reading, and stay tuned for my next article, the last one of the year and quite an exciting one!

If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribing to my channel on YouTube if you like the video format.
- Follow me here or on medium
- Want to get into AI or improve your skills, read this!
References
- Mokady, R., Hertz, A. and Bermano, A.H., 2021. ClipCap: CLIP Prefix for Image Captioning. https://arxiv.org/abs/2111.09734
- Code: https://github.com/rmokady/CLIP_prefix_caption
- Colab Demo: https://colab.research.google.com/drive/1tuoAC5F4sC7qid56Z0ap-stR3rwdk0ZV?usp=sharing
FAQ
What does ClipCap do?
ClipCap generates a natural-language description for an input image by connecting CLIP features to a language model.
What role does CLIP play?
CLIP encodes the image into features aligned with language, providing a semantic signal for caption generation.
Why is a language model still required?
CLIP can compare text and images, but it does not by itself compose a complete, fluent description.
Why is image captioning a difficult task?
A caption must select important objects, actions, and relationships rather than merely recognize isolated visual labels.
Where could automatic captions be useful?
They can improve accessibility, describe media libraries, support search, and help summarize visual scenes.