


Example results of input text and style (left), baseline comparisons (middle two columns), and StyleCLIPDraw results (right). Image from StyleCLIPDraw paper.
Watch the video!
Have you ever dreamed of taking the style of a picture, like this cool TikTok drawing style, and applying it to a new picture of your choice? Well, I did, and it has never been easier to do. In fact, you can even achieve that from only text and can try it right now with this new method and their Google Colab notebook available for everyone. Simply take a picture of the style you want to copy, enter the text you want to generate, and this algorithm will generate a new picture out of it! Just look back at the results above, such a big step forward! The results are extremely impressive, especially if you consider that they were made from a single line of text! To be honest, sometimes it may look a bit all over the place if you select a more complicated or messy drawing style like this one.
As we said, this new model by Peter Schaldenbrand et al., called StyleCLIPDraw, which is an improvement upon CLIPDraw by Kevin Frans et al., takes an image and text as inputs and can generate a new image based on your text and following the style in the image. I will quickly show how you can use it and play with their code easily, but first, let’s see how they achieved that. So the model has to understand what’s in the text and the image to correctly copy its style. As you may suspect, this is incredibly challenging, but we are fortunate enough to have a lot of researchers working on so many different challenges, like trying to link text with images, which is what CLIP can do.
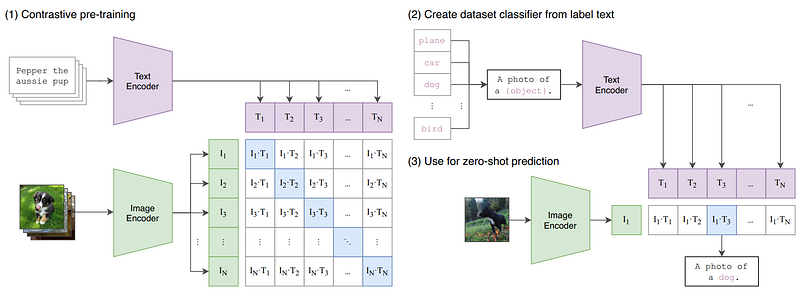
CLIP encoding system to compare text inputs with images. Image from CLIP’s blog post.
Quickly, CLIP is a model developed by OpenAI that can basically associate a line of text with an image. Both the text and images will be encoded similarly so that they will be very close to each other in the new space they are encoded in if they mean the same thing. Using CLIP, the researchers could understand the text from the user input and generate an image out of it. If you are not familiar with CLIP yet, I would recommend reading the article I wrote on Toward’s AI about it together with DALL-E earlier this year.
But then, how did they apply a new style to it? CLIP is just linking existing images to texts. It cannot create a new image…
Indeed, we also need something else to capture the style of the image sent in both textures and shapes. Well, the image generation process is quite unique. It won’t simply generate an image right away. Rather, it will simply draw on a canvas and get better and better over time. It will just draw random lines at first and create an initial image, as shown below before converging into a final picture.

CLIPDraw synthesizes novel drawings from text. Play with the codebase yourself. Image credits to the great CLIPDraw author’s blog post.
This new image is then sent back to the algorithm and compared with both the style image and the text, which will generate another version. This is one iteration. At each iteration, which are shown above in the gif, we draw random curves again oriented by the two losses we will see in a second. This random process is quite cool since it will also allow each new test to look different. So using the same image and same text as inputs, you will end up with different results that may look even better!
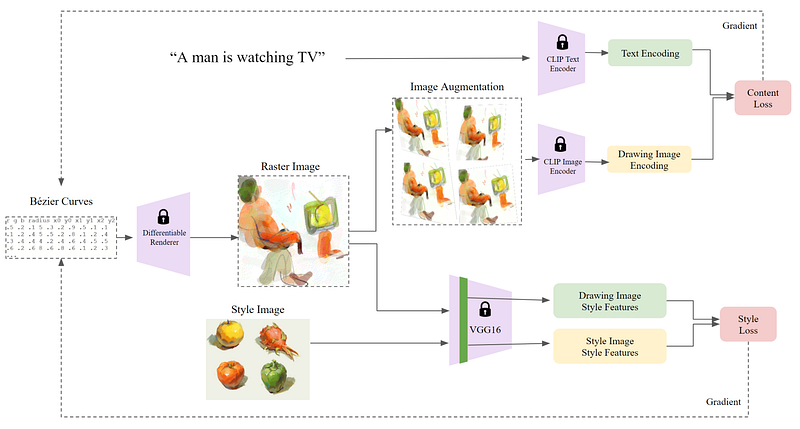
StyleCLIPDraw’s model architecture. First, we generate an image with random lines. Then, we compare its encodings with the image’s style and the text. We utilize this information to orient the next generation and repeat the process until satisfying results. Image from StyleCLIPDraw paper.
Here you can see a very important step called image augmentation. It will basically create multiple variations of the image and allow the model to converge on results that look right to humans and not simply on the right numerical values for the machine. This simple process is repeated until we are satisfied with the results!

So this whole model learns on the fly over many iterations, optimizing two losses we see here. One for aligning the content of the image with the text sent, and the other for the style. Here you can see the first loss is based on how close the CLIP encodings are, as we said earlier, where CLIP is basically judging the results, and its decision will orient the next generation. The second one is also very simple. We send both images into a pre-trained convolutional neural network like VGG, which will encode the images similarly to CLIP. We then compare these encodings to measure how close they are to each other. This will be our second judge that will orient the next generation as well. This way, using both judges, we can get closer to the text and the wanted style at the same time in the next generation. If you are not familiar with convolutional neural networks and encodings, I would strongly recommend watching the short video I made explaining them in simple terms! This iterative process makes the model a bit slow to generate a beautiful image, but after a few hundred iterations, or in other words, after a few minutes, you have your new image! And I promise it is worth the wait!
Now the interesting part you’ve been waiting for… Indeed, you can use it right now, for free or at least pretty cheaply, using the Colab notebook linked in the references below. I had some problems running it, and I would recommend buying the pro version if you’d like to play with it without any issues. Otherwise, feel free to ask me any questions in the comments if you encounter any problems. Just message me on LinkedIn, Twitter, or directly here! I pretty much went through all of them myself.
To use it, you simply run all cells (as shown in the video at the top of this article), and that’s it. You can enter a new text for the generation or send a new image for the style from a link and voilà! Now tweak the parameters here and see what you can do! If you play with it, please send me your results on Twitter and tag me. I’d love to see them!
As they state in the paper, the results will have the same biases as the models they use, such as CLIP which you should consider if you play with it. Of course, this was a simple overview of the paper, and I strongly invite you to read both CLIPDraw and StyleCLIPDraw for more technical details and try their Colab notebook. Both are linked in the references below.
Thanks to Weights & Biases for sponsoring this week’s video and article, and huge thanks to you for watching until the end. I hope you enjoyed this week’s video! Let me know what you think and how you would use this new model!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
Thanks to Weights & Biases for sponsoring this issue! Build better models faster with experiment tracking, dataset versioning, and model management.
To support me:
- The best way to support me is by being a member of this website or subscribing to my channel on YouTube if you like the video format.
- Follow me here or on medium
- Want to get into AI or improve your skills, read this!
References
- CLIPDraw: Frans, K., Soros, L.B. and Witkowski, O., 2021. CLIPDraw: exploring text-to-drawing synthesis through language-image encoders. https://arxiv.org/abs/2106.14843
- CLIPDraw code: https://colab.research.google.com/github/kvfrans/clipdraw/blob/main/clipdraw.ipynb
- StyleCLIPDraw: Schaldenbrand, P., Liu, Z. and Oh, J., 2021. StyleCLIPDraw: Coupling Content and Style in Text-to-Drawing Synthesis. https://arxiv.org/abs/2111.03133
- StyleCLIPDraw code: https://github.com/pschaldenbrand/StyleCLIPDraw
- StyleCLIPDraw Colab: https://colab.research.google.com/github/pschaldenbrand/StyleCLIPDraw/blob/master/Style_ClipDraw.ipynb