What is data-centric AI?
The beginning of data-centric AI with data programming


What makes GPT-3 and Dalle powerful is exactly the same thing: Data.
Data is crucial in our field, and our models are extremely data-hungry. These large models, either language models for GPT or image models for Dalle, all require the same thing: way too much data.
Unfortunately, the more data you have, the better it is. So you need to scale up those models, especially for real-world applications. Bigger models can use bigger datasets to improve only if the data is of high quality. Feeding images that do not represent the real world will be of no use and even worsen the model’s ability to generalize. This is where data-centric AI comes into play.
Data-centric AI, also referred to as Software 2.0, is just a fancy way of saying that we optimize our data to maximize the model’s performances instead of model-centric, where you would just tweak the model’s parameters on a fixed dataset. Of course, both need to be done to have the best results possible, but data is by far the bigger player here.
In this article, in partnership with Snorkel, I will cover what data-centric AI is and review some big advancements in the field. You will quickly understand why data is so important in machine learning, which is Snorkel’s mission. Taking a quote from their blog post linked below:
“Teams would often spend time writing new models instead of understanding their problem—and its expression in data—more deeply. [...] Writing a new model [is] a beautiful refuge to hide from the mess of understanding the real problems.”
And this is what this article aims to combat. In one sentence: the goal of data-centric AI is to encode knowledge from our data into the model by maximizing the data’s quality and model’s performance.
Introducing the Idea of Data Programming
It all started in 2016 at Stanford with a paper called “Data Programming: Creating Large Training Sets, Quickly” introducing a paradigm for labeling training datasets programmatically rather than by hand. This was an eternity ago in terms of AI research age.
As you know, the best approaches to date use supervised learning, a process in which models train on data and labels and learn to reproduce the labels when given the data. For example, you’d feed a model many images of dogs and cats, with the respective labels, and ask the model to find out what is in the picture, then use backpropagation to train the model based on how well it succeeds. If you are unfamiliar with backpropagation, I’d invite you to take a small break to watch my 1-minute explanation and return where you left off.

As datasets are getting bigger and bigger, it becomes increasingly difficult to curate them and remove hurtful data to allow for the model to focus on only relevant data. You don’t want to train your model to detect a cat when it’s a skunk, it could end badly. When I refer to data, keep in mind that it can be any sort of data: tabular, images, text, videos, etc.
Now that we can easily download a model for any task: the shift to data improvement and optimization is inevitable. Model availability, the scale of recent datasets, and the data dependency these models have are why such a paradigm for labeling training datasets programmatically becomes essential.
The main problem comes with having labels for our data. It’s easy to have thousands of images of cats and dogs, but it is much harder to know which images have a dog and which have a cat, and even harder to have their exact locations in the image for segmentation tasks.

This first paper introduces a data programming framework where the user, or ML engineer/data scientist, expresses weak supervision strategies as labeling functions using a generative model that labels subsets of the data and found that “data programming may be an easier way for non-experts to create machine learning models when training data is limited or unavailable.”
In short: they show how improving data without much additional work while keeping the model the same improves results, which is a now evident but essential stepping stone. It is a really interesting foundation paper in this field and worth the read!
The Snorkel Open-Source Framework
The second paper we cover here is called “Snorkel: Rapid Training Data Creation with Weak Supervision”. This paper, published a year later also from Stanford University, presents a flexible interface layer to write labeling functions based on experience. Continuing on the idea that training data is increasingly large and difficult to label, causing a bottleneck in models’ performances, they introduce Snorkel, a system that implements the previous paper in an end-to-end system. This system allowed knowledge experts, the people that best understand the data, to easily define labeling functions to automatically label data, instead of doing hand annotation, building models 2.8 times faster while also increasing predictive performance by an average of 45.5%.
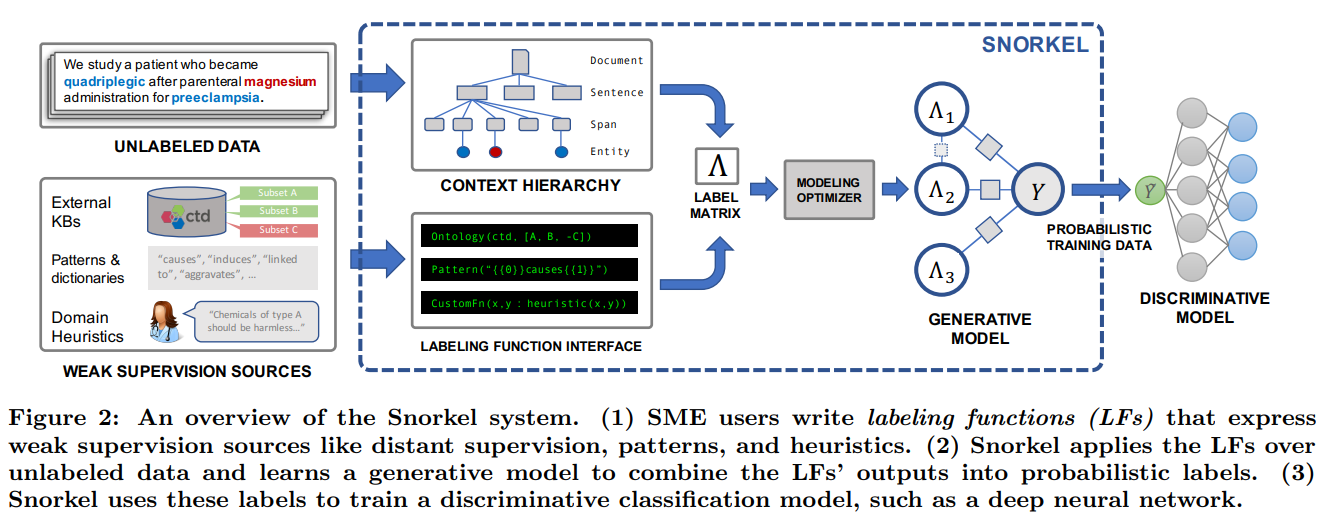
So again, instead of writing labels, the users, or knowledge experts, write labeling functions. These functions simply give insights to the models on patterns to look for or anything the expert would use to classify the data, helping the model follow the same process. Then, the system applies the newly written labeling functions over our unlabeled data and learns a generative model to combine the output labels into probabilistic labels which are then used to train our final deep neural network. Snorkel does all this by itself, facilitating this whole process for the first time.
Data-Centric AI - AKA Software 2.0
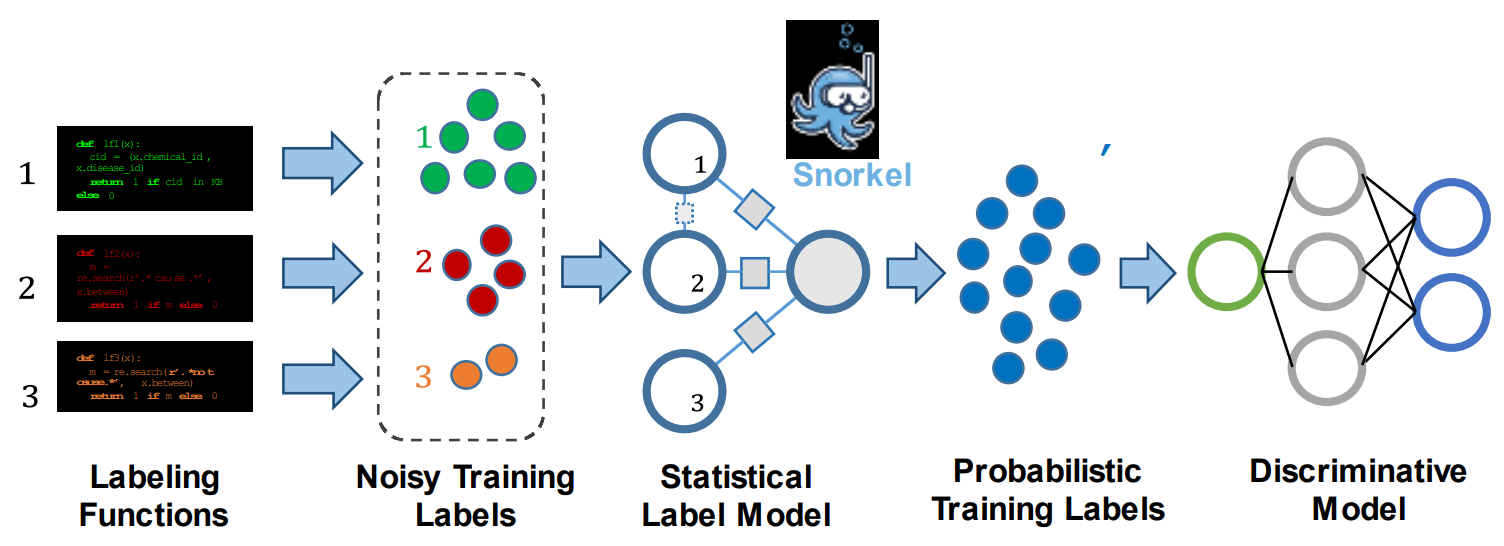
Our last paper also from Stanford, another year later, introduces Software 2.0. This one-page paper is once again pushing forward with the same deep learning data-centric approach using labeling functions to produce training labels for large unlabeled datasets and train our final model, which is particularly useful for huge internet-scraped datasets like the ones used in Google applications like YouTube, Google Ads, Gmail, etc., tackling the lack of hand-labeled data.
Of course, this is just an overview of the progress and direction of data-centric AI, and I strongly invite you to read the information in the description below to have a complete view of data-centric AI and where it comes from, and where it is heading.
I also want to thank Snorkel for sponsoring this article, and I invite you to check out their website for more information (all links below). If you haven’t heard of Snorkel before, you’ve still already used their approach in many products like YouTube, Google Ads, Gmail, etc.!
Thank you for reading,
Louis
References
Snorkel AI started with data-centric AI while working a the Stanford AI Lab in 2015, introducing the idea of data programming in 2016, followed by the Snorkel open-source framework in 2017, and in 2018 data-centric AI or software 2.0 was established as the new way to build AI applications.
►Data-centric AI: https://snorkel.ai/data-centric-ai
►Weak supervision: https://snorkel.ai/weak-supervision/
►Programmatic labeling: https://snorkel.ai/programmatic-labeling/
►Curated list of resources for Data-centric AI: https://github.com/hazyresearch/data-centric-ai
►Learn more about Snorkel: https://snorkel.ai/company/
►From Model-centric to Data-centric AI - Andrew Ng: https://youtu.be/06-AZXmwHjo
►Software 2.0: https://hazyresearch.stanford.edu/blog/2020-02-28-software2
►Paper 1: Ratner, A.J., De Sa, C.M., Wu, S., Selsam, D. and Ré, C., 2016. Data programming: Creating large training sets, quickly. Advances in neural information processing systems, 29.
►Paper 2: Ratner, A., Bach, S.H., Ehrenberg, H., Fries, J., Wu, S. and Ré, C., 2017, November. Snorkel: Rapid training data creation with weak supervision. In Proceedings of the VLDB Endowment. International Conference on Very Large Data Bases (Vol. 11, No. 3, p. 269). NIH Public Access.
►Paper 3: Ré, C. (2018). Software 2.0 and Snorkel: Beyond Hand-Labeled Data. Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/