

Key takeaways
- It’s a much more complex problem than processing text as you also need to deal with background noises, different tones or pitch, and, obviously.
- So you only need audio examples to train this new distilled model.
- This is why Distil-Whisper works well with out-of-distribution data, meaning data outside of its training data (1% difference).
Watch the video:
As you know, we can already exchange with AIs in a written format extremely well and efficiently, mostly thanks to ChatGPT but also open-source alternatives. The next step is to talk with them fluently, using our voice. If you haven’t tried it yet, OpenAI has a pretty good AI for that called Whisper, which anyone can pay to use and transcribe voice or audio into text that can then be used by any model or downstream task. It is extremely powerful but definitely is not easy to blend in well in any real-time application due to its computational complexity and the time it takes to process the audio.
You know how annoying it is to wait a little before your message is understood. For example, with the assistants we have, like Siri or Google Assistant. The AI transcribers will need to be much more efficient before the voice in an AI-based app becomes a seamless nice-to-have rather than just a funny thing you try but don’t use in your day-to-day work. Fortunately, amazing researchers are working on this audio transcription problem and recently shared Distil-Whisper. A model that is 6 times faster than the original Whisper model, 49% smaller, and keeping 99% of the accuracy. And the best thing about it is that it is fully open-source, and you can use it right now.
Check out the video to see results examples live!
Distil-Whisper is an improvement from Whisper in both size and rapidity. It isn’t performing better, but it matches the results, which is already extremely good if you are familiar with Whisper: it’s pretty impressive, understanding human speech better than I can for most accents.
And yes, you heard it right. They made it almost six times faster, 5.8 times, to be exact. Not only that, but they also report the new model is less prone to hallucination errors on long-form audio! To be clear, hallucinations here are basically transcriptions that do not fit the recorded audio track, as we often see on automatic TV transcriptions. How? By using distillation and pseudo-labeling with the original Whisper model.
Let’s go through this step-by-step.
First, distillation or, rather, knowledge distillation. Knowledge distillation is a way to compress a bigger model into a smaller one. It’s basically like a teacher with a student: you share your knowledge with the student. Then, assuming you did a good job, the student should have absorbed the most relevant information you have about the topic. So we have two models here, a student, the new Distill-Whisper model, and a teacher, the original Whisper model.
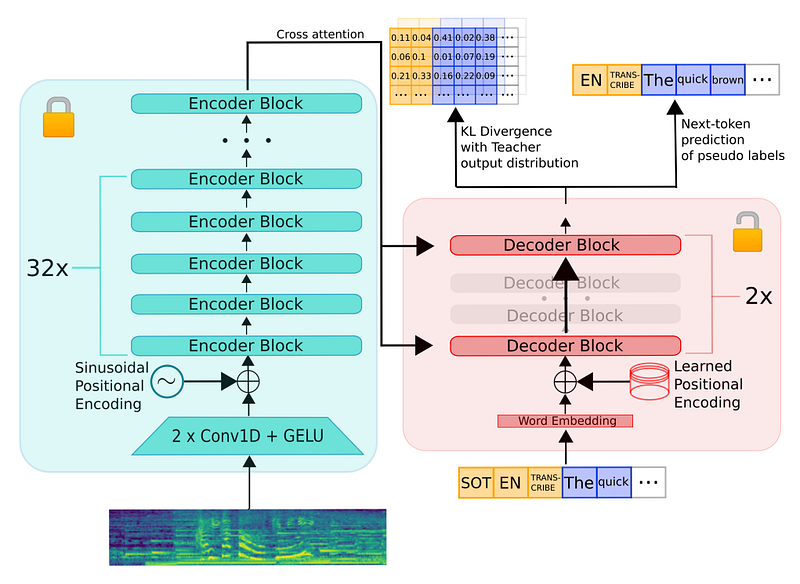
Figure 1: Architecture of the Distil-Whisper model. The encoder (shown in green) is entirely copied from the teacher to the student and frozen during training. The student’s decoder consists of only two decoder layers, which are initialised from the first and last decoder layer of the teacher (shown in red). All other decoder layers of the teacher are discarded. Image and caption from the paper.
Whisper is one of the most powerful models for audio transcription. It is a sequence-to-sequence transformer model pre-trained on a massive dataset comprising 680,000 hours of noisy speech recognition data, which was web-scraped from the internet. Pretty much the GPT-4 of audio. It has very similar encoder and decoder transformer-based blocks, just like the GPT models. While both GPT and Whisper use the transformer model, the key difference is in their application and how they process input. Basically, sound vs. text. GPT is designed to understand and generate text, so it directly works with written words or characters. Whisper, on the other hand, first needs to interpret audio signals — it processes the sound waves from speech, breaking them down into features that its encoder can understand before converting them into text. It’s a much more complex problem than processing text as you also need to deal with background noises, different tones or pitch, and, obviously, identify the different speakers. This additional step of interpreting complex audio patterns is what sets Whisper apart and allows it to effectively handle speech recognition tasks. Just like following this blog sets you apart in the AI space, quickly understanding new approaches and staying up-to-date!
Then, instead of training a model as usual with labeled data, you first take the most important parts (we call weights) of the model and put them into the student model. This is also called the shrinking part. It’s like giving the student model a head start in learning, as you would have using a teacher to learn about a new topic instead of starting and researching by yourself.
Now, you will again use the teacher. Here, we can use what the teacher model (Whisper) generates from the input audio. This is the pseudo-labeling part. Instead of labels, we use the Whisper’s generated answer as labels. Our student doesn’t just learn to replicate correct answers, but it learns the reasoning behind the answers of the teacher model. What I mean here is that the student focuses on replicating the teacher’s understanding and not just predicting the correct next word to generate from the audio as we would do in a regular training format. In more scientific words, the student model learns from the teacher model’s predicted distribution and not just the final output. This predicted distribution is the whole space of the input, where you then draw from to guess the next word. This is why the smaller student model has such good performances compared to training a smaller model from scratch on guessing the next words in a more regular training scheme.
It also has the benefit of not requiring the annotated data as the original Whisper model gives it to your student. So you only need audio examples to train this new distilled model. Perfect when your task is expensive in data labeling or complicated to have!
Also, thanks to this pseudo-labeling knowledge distillation training scheme, the training of Distil-Whisper is notably more efficient, requiring only around 14 thousand hours of speech examples compared to 680,000 hours for training the original Whisper model. Yes, the student requires only 2% of training data to match the results!
And voilà! This is why Distil-Whisper works well with out-of-distribution data, meaning data outside of its training data (1% difference). Indeed, it doesn’t outperform the original Whisper in terms of accuracy, but it matches its performance with significantly reduced size and increased speed. To me, this is much cooler than a little improvement in accuracy!
Of course, there are technical details about the training scheme and model that I omitted in this overview for simplicity. I invite you to read the full paper for an in-depth understanding of this new model. I also strongly recommend you try it by yourself, especially if you are already using Whisper for your own applications or work. All the links are in the description below. On my end, I’m super excited to see audio models improving in efficiency and being able to use them seamlessly in any application soon. That will be super cool.
Thank you for reading the whole article. If you did, please don’t forget to leave a like, as it helps the channel a lot!
I will see you in the next one with more AI news explained! If you don’t want to miss it, don’t forget to subscribe to my newsletter, where I share all my projects!
Louis-François Bouchard
References
- Gandhi et al., HuggingFace, 2023: Distil-Whisper. https://arxiv.org/pdf/2311.00430.pdf
- Demo: https://huggingface.co/spaces/Xenova/distil-whisper-web
- Model: https://huggingface.co/distil-whisper/distil-large-v2
FAQ
What is the useful lesson from Understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
It’s a much more complex problem than processing text as you also need to deal with background noises, different tones or pitch, and, obviously.
What should builders test before using understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
So you only need audio examples to train this new distilled model.
What is the main LLM risk with understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
Fortunately, useful researchers are working on this audio transcription problem and recently shared Distil-Whisper.
How should builders use understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
This is why Distil-Whisper works well with out-of-distribution data, meaning data outside of its training data (1% difference).
When does understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription become useful in practice?
So we have two models here, a student, the new Distill-Whisper model, and a teacher, the original Whisper model.
What should beginners understand about understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
Then, instead of training a model as usual with labeled data, you first take the most important parts (we call weights) of the model and put them into the student model.
What is the common mistake with understanding Distil-Whisper: A Closer Look at AI's Role in Audio Transcription?
Fortunately, useful researchers are working on this audio transcription problem and recently shared Distil-Whisper.