

Watch the video:
We can adapt large language models to do whatever we want. It can become your personal assistant, answering all your emails, or your future lawyer. You can make them do whatever you want. But how can you do that? Fine-tuning! Let’s dive into what it is, how it works, and most importantly, how to do it super easily with a great company I’ve worked with: Gradient, an amazing platform for individuals like you and me who want to build and deploy AI models.
Fine-tuning is extremely important when it comes to almost all AIs, but especially large language models. It’s basically the process of taking a very powerful general model, like GPT-4 and making it an expert in a specific task. In a way, it is just like going to high school and then to university, doing a master’s degree and a Ph.D. You start with very general knowledge, build a good base, and iteratively refine it on a more narrow and narrow use case where you end up THE expert.
I don’t have to sell you how powerful GPT-4 and other large language models already are, but it is far from perfect for specialized tasks, and one of the best ways to make it such an expert is to fine-tune it with expert knowledge. This means re-training parts of the model on the exact task we want it to achieve, which is much less costly than training the model from scratch.
For example, GPT-4 has itself somewhat of a good medical knowledge thanks to the internet, but it is far from perfect. It’s just like asking a question about a weird pimple you have and clicking on the first link that appears. No, it’s probably not cancer, as it says.
Instead, you could gather tons of medical books and dictionaries and give that to GPT-4, so it learns from them and only them, transitioning from a generalist to a specialist. It will lose some generalist capabilities, just like any genius or expert in a field. The large amount of time invested in a specific field surely compensates elsewhere. Still, if you want the best at something, this is a necessary sacrifice.
Some other clear examples of using fine-tuning would be to create a financial assistant. In this case, you’d like to train it on lots of financial documents, news, trends, the stock market, etc. Asking GPT-4 right away would be like asking a friend who understands the concept but was living under a rock and hasn’t kept up with the latest developments. Imagine, he doesn’t even know that ChatGPT came out or hasn’t even looked at stocks and the market for the past two years. How could he help you invest?!
A last example that you’ve certainly already interacted with is customer support chatbots.
Imagine you have a large customer support team and want to enhance efficiency and response times. You can fine-tune a language model with historical customer inquiries and support agent responses. This transforms the model into a chatbot capable of handling common customer queries. Now, when customers reach out for help, the chatbot can instantly provide accurate information or escalate more complex issues to human agents. Fine-tuning improves customer satisfaction and streamlines support operations.
In short, fine-tuning can be used if you need any kind of domain-specific experts. You take the best model possible, like GPT-4, or an open-source one like Llama 2, and fine-tune it to become a history teacher, a financial expert, a medical expert, or even your personal nutrition and fitness coach only by feeding it more examples or documentation.
[
The What’s AI Weekly by Louis-François Bouchard | Substack
You also certainly know about hallucinations, which happen when a model gives you false information because it assumes it knows, but in fact, it is just creating facts out of thin air. This happens because the model was trained to give an answer and not enough trained to say, “I don’t know.” Well, fine-tuning helps with that as well since it literally has more knowledge! But, unfortunately, it does not completely fix hallucinations. If it is your main problem, you may want to look into complementing your fine-tuned model with retrieval augmented generation, which will be the subject of a future article, so follow and stay tuned for it! I’m excited to share a very cool project I’ve been working on with our team at Towards AI using this system.
It’s still the best way to make your AI high school graduate an expert in a new field, whatever this field is. It will adapt the model to any new challenging context if you give it sufficient information. Plus, it is super easy to do, especially when using products like Gradient, instead of coding everything yourself. Let’s dive into the moment you were waiting for. Here’s a practical example showing how to fine-tune any open-source model, in this case, the powerful Llama-2 model, to change its current knowledge base and adapt it to your needs.
Small demo with Gradient
Once you’ve signed up for the Gradient platform, it’s super easy to start fine-tuning.
Here, I’m going to use the Command-Line Interface to see the fine-tuning process live, but Gradient also has Python and JavaScript SDKs you can use instead if you don’t like this typical coder terminal.
So, let’s check out the available models we can fine-tune here. You can see bloom-560m, llama2–7b, and nous-hermes-2, which is an uncensored version of llama2.
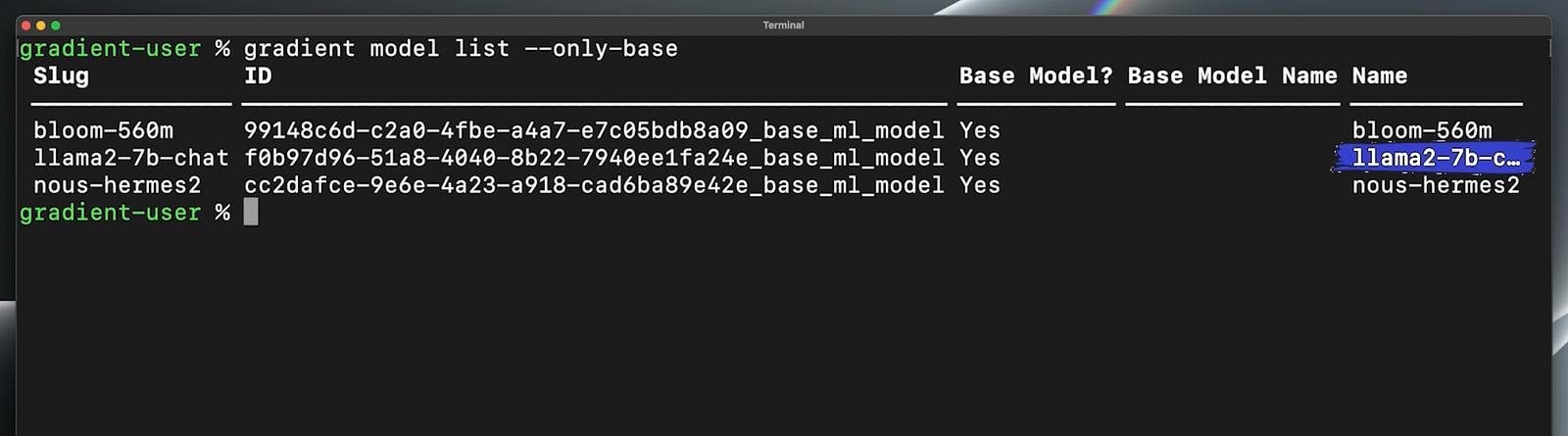
Let’s use llama2. As I said, it’s pretty much the best open-source LLM to date.
We just need to create a new private instance of llama2 with the command “gradient model create” and then copy in the llama2 model ID you see here.
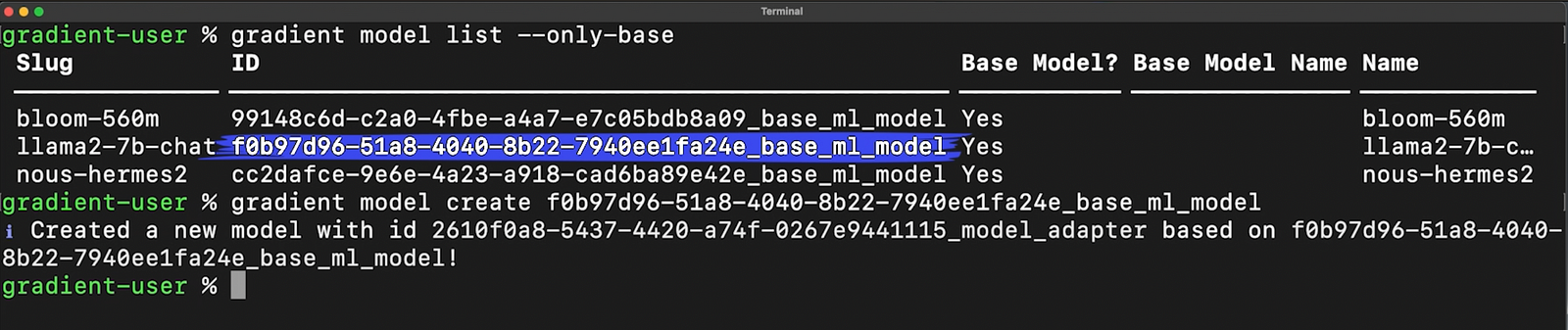
To demonstrate what fine-tuning does, let’s ask the model the same question before and after fine-tuning.
As a basic example, let’s ask it: “What is Gradient?” This is just Llama2 out of the box, so it obviously answers, “Gradient is a term used in machine learning and neural networks to describe the rate of change of a function with respect to one of its inputs.” Something you already know if you follow the channel assiduously.
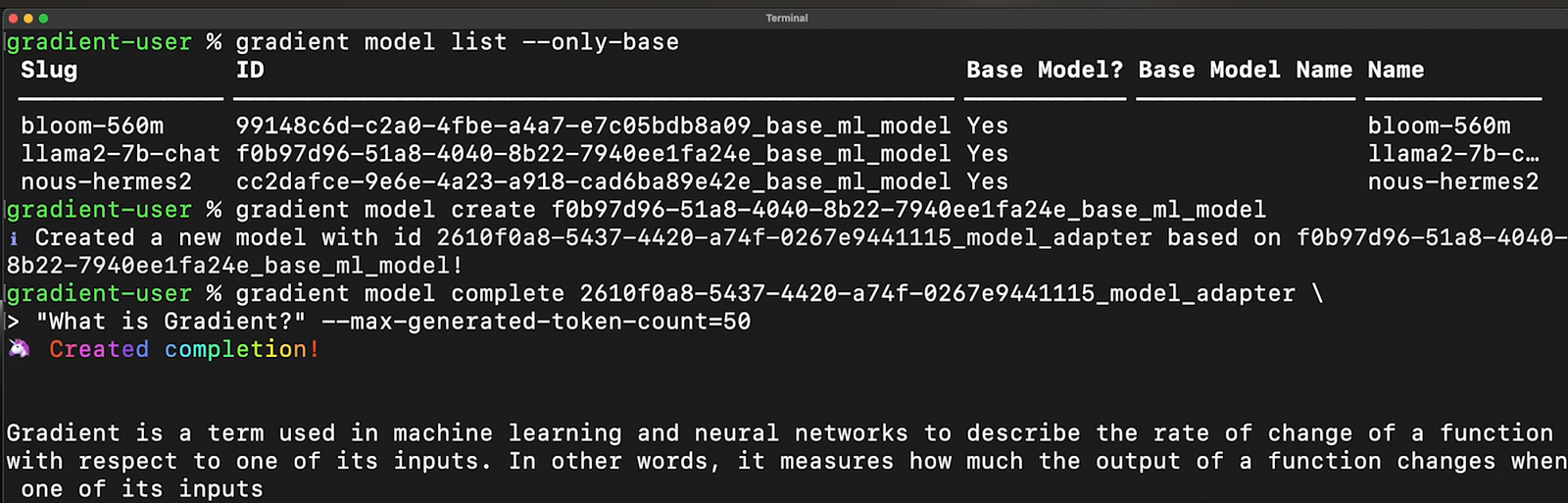
So this is true based on general knowledge. But let’s say we want it to learn about the Gradient that is the platform I’m using right now. We need to give it more domain-specific knowledge. Make it become an expert in this platform. To do that, we need to fine-tune it with, for example, Gradient’s documentation.
We can easily do that using one command, “gradient model fine-tune” and give it the model ID for the private instance of the model we just created.

The JSONL file we are giving it is stored locally on my laptop and contains excerpts from Gradient’s documentation.
Now that it’s finished fine-tuning, let’s try again and ask it the same question “What is Gradient?”… and voilà! It has learned a new definition of what Gradient is!

Of course, this is a super simple example with the Gradient.ai platform, but you can fine-tune a model on any type of data, and it will learn about different concepts, and your model will become better at completing tasks about that specific domain. You can also obviously code it yourself, and I will have a video coming soon doing that on my channel!
I hope you’ve enjoyed this article about fine-tuning. If you did so, please let me know if you’d like me to cover any other techniques or terms in the field in a similar format.
Thank you for watching!