

Watch the video and support me on YouTube!
Wildfires are more and more present in modern society, mainly caused by heat waves, lightning, droughts, climate change, or even human actions like car fires and cigarette butts. We’ve seen it everywhere recently Brazil, Australia, United States, Canada, etc., destroying plant, human, and animal life, property damage, and contributing to global warming through the high amount of CO2 produced. These countries all have walls of videos like the one below in the county’s fire emergency to see if something is going on.

Syntecsys surveillance camera wall.
The most common problem is that they are spotted too late and already widely spread out. This is because you cannot have somebody staring at that wall all day, waiting to spot smoke or fire. And now you see where this is going; that’s where artificial intelligence comes into play. Using a good enough AI, you can have something even better: it will be staring at all of these cameras simultaneously all day. It will automatically ping the authorities as soon as it detects something weird within a split second. The best thing is that it can save the video frames with the suspicious smoke and send it with this ping along with recommended fighting action, making the process much more efficient. The worst case is a false alert that authorities decide to ignore. It’s such a cool and practical application of AI, and it has already been deployed in the real world!
Indeed, such an AI-based system has been running in Brazil for the past three years, and it reduced fire detection time from an average of 40 minutes to less than five [3]. This system, built by a Brazilian company called Sintecsys [1], started using cameras installed on top of 50 towers distributed in Brazil. With the help of Omdena’s AI community, where many teams were assembled to attack this task, they managed to build the best AI model for this use case.
The problems to attack
The main problems they had to face are that 1. the images sent to the model came from different times of the day. Meaning that not only the luminosity will be different between day and night, which is a massive factor for a model since it affects and changes the whole image giving it a hard time to understand what’s going on, but also that day fires are easily detected through the smoke. In contrast, night fires are much more easily detected through live fire, due to obvious reasons. To attack this issue, teams either could build two separate models, one for the night and one for the day or build one larger model and assume that the smoke is also detectable during nighttime.

Two possible approaches to attack this problem with deep learning.
The latter could work with sufficient training data and parameters to learn from this data. Of course, the first way is problematic since there is still the sunset and dawn problem where both live fire and smoke could be detected. They do not mention how they decided to build the final model, but both were tested by different teams from Omdena’s AI community.
In your opinion, what would you say could be the best solution for this situation? I would assume a large enough model would be their best shot to fix the dawn and sunset boundary problem without training a model for each sub-case. They had to face a second problem: differentiate real smoke and smoke-like anomalies such as camera glare, fog, clouds, and smoke released from boilers that appear in the images.
The final problem was the low definition of the images they received from the cameras. This model initially received heavily compressed images sent from the cameras, so they had to upscale it before sending it to their model.
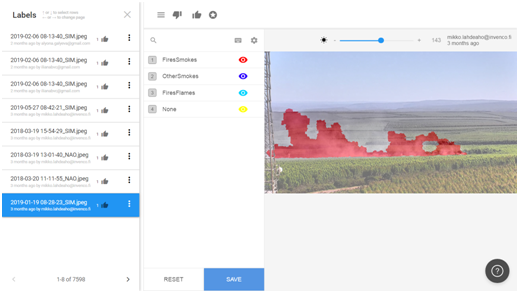
Labelbox interface for labeling, managing, and reviewing labels.
As you know by now, AI is hugely data dependant, so they had to have the best training data possible in terms of quality and quantity to solve these problems successfully. Such a model can only be as good as the data it is given during its training, so it had to be very broad and contain all possible artifacts that may appear in the real world, like clouds, fog, and camera glare we just discussed. To start, they had 20 people manually labeling 9’000 images as precisely as possible. This means that they manually went through all the images painting over the smoke to help the model understand what smoke looks like. This is undoubtedly the most expensive and tedious task, but it’s crucial to build most deep learning-based models used in real-world applications. If you are not familiar with data annotation, I invite you to watch this short video I made last year explaining it:
How does an AI model able to detect wildfire work
After doing so, they could start diving into how to attack the smoke detection, which means finding the best way to detect whether there is smoke or not in the picture. We do not have the details on the exact chosen model. Still, they shared that they ended up using a convolutional neural network (CNN) approach with some modifications to the images before they send them to the network.
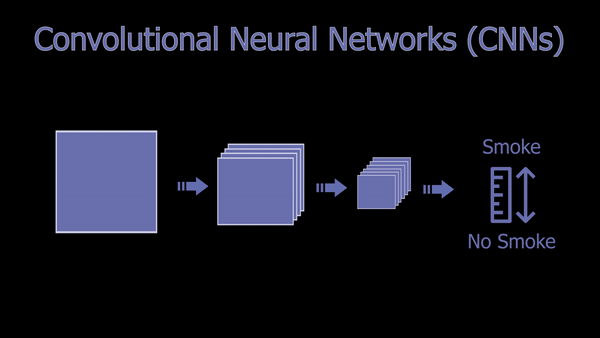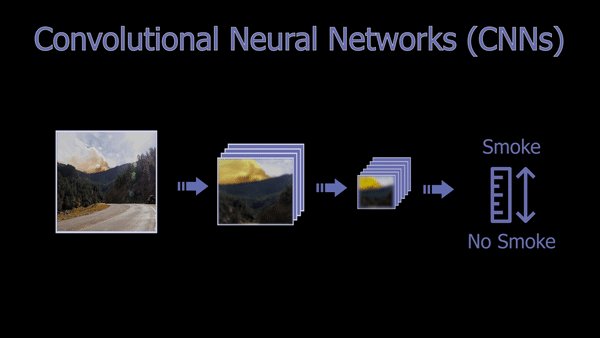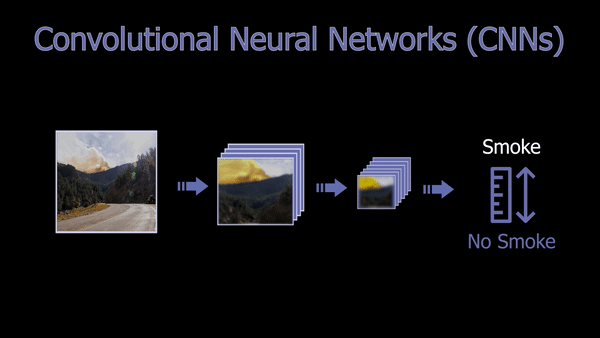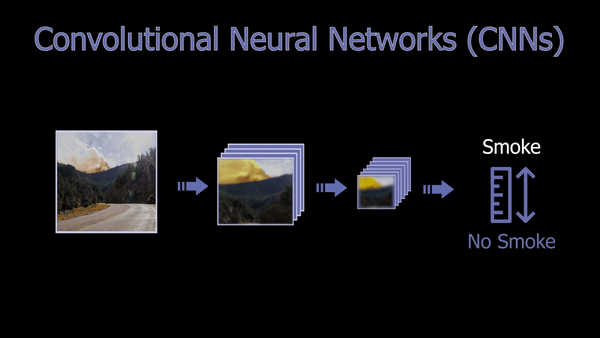
A Basic Convolutional Neural Network Architecture (CNN).
As you may be aware, CNNs are a powerful deep learning architecture for vision-based applications in which, simply said, the image is iteratively compressed, focusing on the information we need about the image while removing redundant and uninformative spatial features, ending up with a confidence rate informing us whether the image contains what we were looking for or not. This focus can be on anything, from detecting cats, humans, objects, to detecting smoke in this case. It all depends on the data it is trained on, but the overall architecture and working will stay the same. You can see CNNs as compressing the image, focusing on a specific feature of the image at every step, getting more compressed and relevant to what we want the deeper we get in the network.

What, why, how: Filters in a convolutional neural network.
This is done using filters that will go through the whole image, putting its focus on specific features like edges with specific orientations. This process is repeated with multiple filters making one convolution, and those filters are what is learned during training. After the first convolution, we get a new smaller image for each filter, which we call a feature map, each of them focusing on specific edges or features. So they will all look like a weird and blurry zoomed version of the image giving an accent on specific features. And we can use as many filters as needed to optimize our task.
Then, each of these new images is sent to the same process repeated over and over until the image is so compressed that we have a lot of these tiny feature maps optimized on the information we need, adapted for the many different images our dataset contains. Lastly, these tiny feature maps are sent into what we call “fully connected layers” to extract the relevant information using weights.

The fully connected layers for classification at the end of our CNN.
These last few layers contain all connected weights that will learn which feature the model should focus on based on the images fed and pass the information forward for our final classification. This process will further compress the information and finally tell us if there is smoke or not with a confidence level. So assuming the model is well trained, the final results would be a model focusing its compression on smoke features in the image, which is why it is so appropriate to this task or any task involving images.


(left) high filter responses from an image with smoke and (right) low filter responses from an image without smoke.
If there is smoke, the filters will produce high responses, and we will end up with a network telling us that there is smoke in the image with high confidence. If there is no smoke, these compression results will produce low responses, letting us know that nothing is going on in the picture regarding what we are trying to detect, which is a fire in this case. It will also produce results with a confidence rate anywhere in between no smoke and evident smoke. As they shared, the final model detected smoke in images with an impressive 95% to 97% accuracy [2]!
How to apply it to other countries
Of course, the model isn’t perfect yet, and as I said, it is very dependant on its training data like most deep learning-based approaches.
This means that it may not be as good when trying to use this same model on different types of environments, and we may need to use more data to adapt the model to the new environment. Fortunately, there are many ways to adapt a model with very little available data, which we call fine-tuning a model, and it’s done with new data different from the ones used in training. So, starting with this strong baseline they have, you won’t need to label 9’000 images for any new country you want to run your model on. For example, this model trained on Brazilian forest images may need to be trained again on a few hundred to a few thousand more images from Canadian forests if we would like to use it in Canada.
Conclusion
This is an amazing real-world application of machine learning with a great use case that will benefit everyone, especially these days with many wildfires around the world. Before leaving this article, I would like to ask you a question: Are there any environment-related applications where you would see AI help? Let me know in the comments, and I will look for it to cover any of them!
Thank you for reading,
— Louis
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References:
- Syntecsys, 2021: https://umgrauemeio.com/
- Odemna article “Artificial Intelligence For Wildfires: Scaling a Solution To Save Lives, Infrastructure, and The Environment”, December 2020: https://omdena.com/blog/artificial-intelligence-wildfires/
- Odemna’s article “Leveraging AI to fight wildfires”, 2021: https://omdena.com/projects/ai-wildfires