
The short version
A CNN processes an image by learning filters that turn pixels into increasingly compressed, task-specific features. During training, labeled examples adjust those filters so the network can assign a confidence to a category such as smoke, fire, a cat, or a person. That is statistical pattern recognition, not human vision, and it works only as well as the examples and conditions represented during training.
- AI understands images by turning pixels into useful features, patterns, and representations for a task.
- The system does not see like a human. It learns statistical signals that can work well and still fail in strange ways.
- The practical question is whether the representation holds up on the real images, cameras, lighting, and edge cases you care about.
Watch the video and support me on YouTube
This article aims to explain one of the most used artificial intelligence models in the world. I will try to make it very simple, so anyone can understand how it works. AI surrounds our daily lives, and it will only become more present, so you need to understand how it works, where we are at, and what’s to come. The more you learn about AI, the more you will realize that it is not as advanced as most think due to its narrow intelligence, yet it has powerful applications for individuals and companies. Knowing how it works will help you better understand the possible applications, limitations and communicate better with your tech employees.
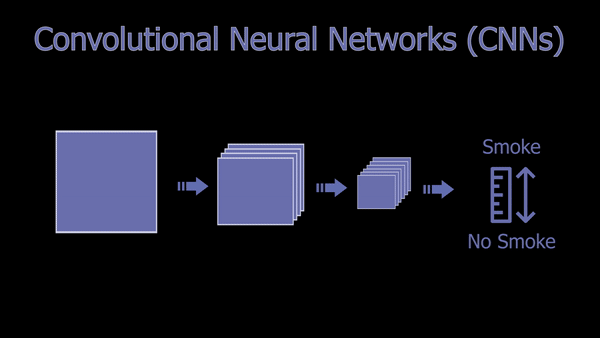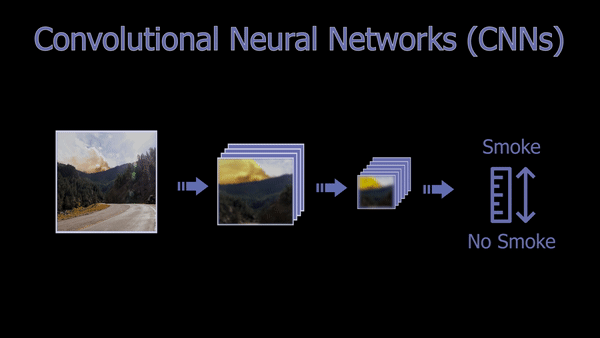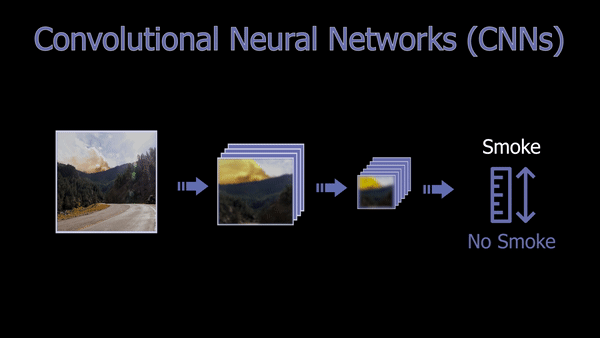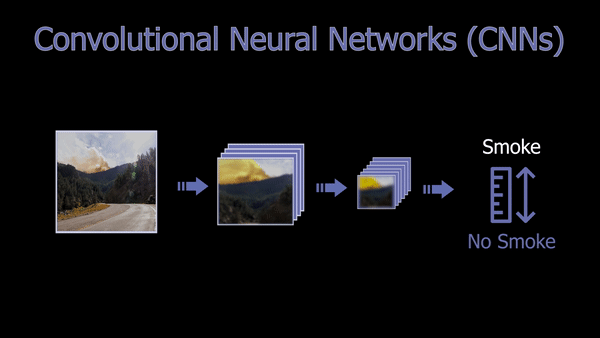
One of the most powerful deep neural network architectures in computer vision, which is any vision-based application involving images, is the Convolutional Neural Networks (CNNs). CNNs are a powerful and widely used deep learning architecture for vision-based applications. Simply put, the way it works is that the image is iteratively compressed. The network focuses on the information we need about the image while removing redundant and non-general spatial features. We end up with a confidence rate informing us whether the image contains what we were looking for or not. This focus can be on anything, from detecting cats, humans, objects, to detecting smoke in this case. It all depends on the data it is trained on, but the overall architecture and working will stay the same. By training, I mean the process of iteratively feeding all the images we have to the model to try and improve its performance, as we will explore in this article.
You can see CNNs as compressing the image, focusing on a specific feature of the image at every step, getting more compressed and relevant to what we want the deeper we get in the network.
This article will focus on an exciting application where AI is used for helping to spot wildfires in images to help reduce the average detection time and damage caused by the fires. As you may expect, our filters will focus on smoke and fire features.

What, why, how: Filters in a convolutional neural network.
This is done using filters that will go through the whole image, putting its focus on specific features like edges with specific orientations. This process is repeated with multiple filters making one convolution, and those filters are what is learned during training. After the first convolution, we get a new smaller image for each filter, which we call a feature map, each of them focusing on specific edges or features. So they will all look like a weird and blurry zoomed version of the image giving an accent on specific features. And we can use as many filters as needed to optimize our task.
Then, each of these new images is sent to the same process repeated over and over until the image is so compressed that we have a lot of these tiny feature maps optimized on the information we need, adapted for the many different images our dataset contains. Each convolution added is a layer added to the “depth” of our network, making it a deep neural network when it has multiple layers in between the image and the classification results. Put simply, the more filters we have, the more different images we can cover for our task, considering we have all the variations within our data used for training it. What’s important here is to find the sweet spot with the number of filters used per layer and the depth of our network to the complexity of the task that needs to be achieved.
Lastly, these tiny feature maps are sent into what we call “fully connected layers” to extract the relevant information using weights.

The fully connected layers for classification at the end of our CNN.
These last few layers contain all connected weights that will learn which feature the model should focus on based on the images fed and pass the information forward for our final classification. This process will further compress the information and finally tell us if there is smoke or not with a confidence level. So assuming the model is well trained, the final results would be a model focusing its compression on smoke features in the image, which is why it is so appropriate to this task or any task involving images. Good training means that the model has correctly adapted its weights (or filters) to identify the feature it needs to identify. In this example, the network would base its results on the smoke and fire while giving low to no response when neither appears in the image. This weight/filter adaptation is made iteratively by feeding examples to the network and updating the values of the weights based on the difference between what the network said and what we wanted it to say. Initially, the network will behave quite randomly, so the network will update its weight regularly. Over time, it will get closer and closer to the truth, and we will end our training.
Of course, there are more technical details regarding the training process, but this is well enough to understand how a deep network is able to give a classification when receiving an image.


(left) high filter responses from an image with smoke and (right) low filter responses from an image without smoke.
If there is smoke, the filters will produce high responses, and we will end up with a network telling us that there is smoke in the image with high confidence. If there is no smoke, these compression results will produce low responses, letting us know that nothing is going on in the picture regarding what we are trying to detect, which is a fire in this case. It will also produce results with a confidence rate anywhere in between no smoke and evident smoke. And voilà, you have your wildfire detector!
Thank you for reading,
— Louis
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
FAQ
How does AI understand images?
An AI vision model turns pixels into features and representations, then uses those representations for tasks like recognition, detection, or segmentation.
Does computer vision understand images like humans do?
No. It can learn useful visual patterns, but it does not share human context, common sense, or lived experience around the image.
What are image features in AI?
Image features are learned signals such as edges, textures, shapes, parts, objects, or higher-level patterns that help solve a visual task.
Why do vision models fail on simple-looking images?
They can fail when the image distribution changes, labels are weak, the scene has rare details, or the model relies on the wrong shortcut.
How can builders evaluate image understanding?
Test the model on real examples, edge cases, different conditions, underrepresented groups, and errors that would matter in the product.