

Key takeaways
- The goal of MetaGPT is simple: replace each with a fictive human being: a GPT model.
- Since we trained the AI model to provide an answer to all questions, it does so even if it does not have the right answer to your question.
- You can see how it can become a problem for one AI model, but imagine what happens if you connect many of them together without human supervision.
Watch the video!
Thanks to GPT and the recent large language models, we’ve seen the popularization of a new type of AI-based system… agents. An agent is basically an AI model like ChatGPT that can access and interact with one or more applications. Imagine asking ChatGPT to create a PowerPoint for you. But the whole thing, not just the text on each slide. The layout and images too. It is kind of trying to imitate a human being for a specific task instead of being restricted to text. In order to do that, the agent needs to understand the software and interact with it in some way, either through its text commands, if possible, or with code generation.
An agent can become quite powerful when you combine it correctly with a software or application, but even more powerful is combining a number of such agents, allowing you to complete much more complex tasks like coding a whole video game, from brainstorming the idea to designing the different levels, difficulty, code and QA testing, where one agent would be responsible for each of these tasks. Many of such systems that only require an initial prompt like “build me a flappy bird-like game” already exist, like Auto-GPT, BabyAGI, or AgentGPT, but have a shared problem.
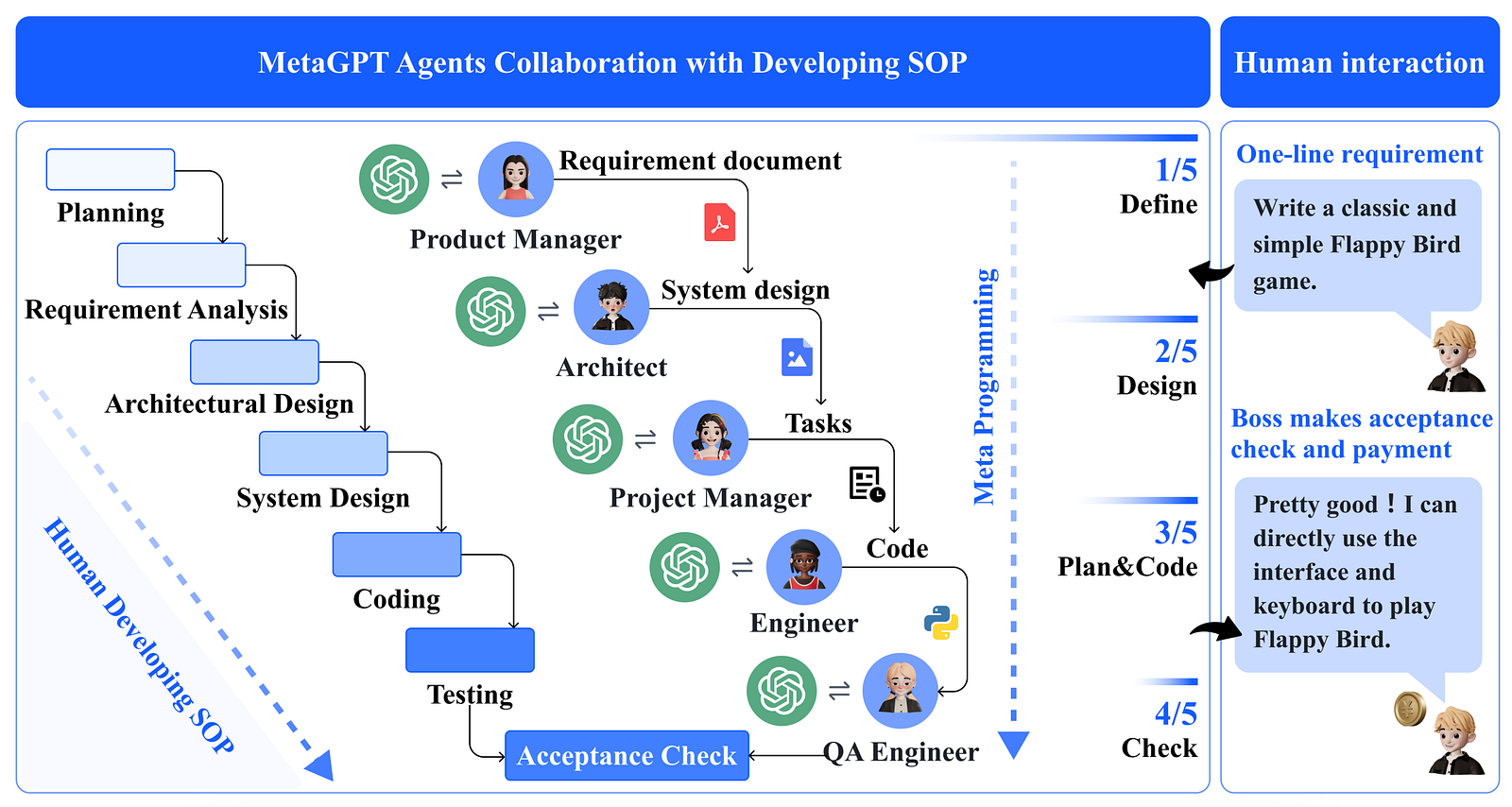
Figure 1: A comparative depiction of the software development SOP between MetaGPT and real-world human team. Image from the paper.
Building such an advanced system based on large language models is both very difficult and unsafe. One of the main issues is that a large language model like ChatGPT is susceptible to hallucinations, which happen when the model spits out facts or information that is completely nonsensical. Since we trained the AI model to provide an answer to all questions, it does so even if it does not have the right answer to your question. And the main issue is that it believes it to be true, it doesn’t have the concept of lying or hiding the truth, it just doesn’t know. You can see how it can become a problem for one AI model, but imagine what happens if you connect many of them together without human supervision. Things can escalate quickly.
For example, if we wanted to build a Flappy Bird game, our first agent could be responsible for defining the game. What if it doesn’t know about the original flappy bird game because it wasn’t in its knowledge and just hallucinates a whole other game involving birds? All of the other agents would build upon the wrong game idea, and your final results will be drastically different from what you expected even if your agents act perfectly…
So the question is, how can we mitigate those hallucinations from happening and compound? Well, that’s the goal of MetaGPT by Sirui Hong et al.. MetaGPT is a new paper and open-source work that is making a lot of noise on GitHub!
The researchers developed a new framework for combining or chaining large language models and mitigating hallucination risks by integrating human standardized operating procedures (SOPs) into the chaining process. This new design scheme allows the system to better understand the user goal and mitigate the hallucinations by dividing a complex task into multiple easier ones. For comparison, we’ve seen that ChatGPT is pretty bad at math, but asking it to answer step-by-step has been proven to improve the results. And that’s kind of obvious. It’s the same for us. It’s much more easy to divide a complex problem into a few clear small problems that you solve individually and combine the answers. What is easier between building a car or building all small pieces like the wheels, motor, suspensions, seats, etc… and then having an assembling step.
But what are SOPs, and why are they useful to the LLMs exactly? SOPs are used by many companies to define specific job roles or workflows, like the hiring process of an employee, for example. We use them to ensure fairness for all processes of the same task and easy collaboration between employees by having clear tasks for each person, also maximizing the parallelism of the work and thus efficiency. Another benefit of having good SOPs is that new employees can quickly get to the level of the current experts since the task has clear and simple subtasks to follow, which makes it perfect for most humans to follow or for relatively dumb language models! Here, we have 5 people with different roles in building the Flappy Bird video game. In a real scenario, they would have very clear steps and goals designed by the whole team. The goal of MetaGPT is simple: replace each with a fictive human being: a GPT model. So instead of talking to each other, the different GPT models will generate standardized documents for the following GPT model, which will limit possible hallucinations when conversations flow freely, just like when meetings diverge to talk about the last soccer game. So instead of requiring advanced human managing skills and communication skills, the models only require the ability to generate clear and simple standardized steps, which they are pretty good at.
Figure 1: A comparative depiction of the software development SOP between MetaGPT and real-world human team. Image from the paper.
MetaGPT also has a foundational layer where the different models can exchange together, and their discussions are saved into memory for efficiency and allow them to look back and access all information. Just like meeting notes. So we have each agent with a personality and a role. Each has its goal and constraints for the project that are defined by the user. This may be the most important step to reduce hallucination risks along with SOPs since we include humans in the process to define clear objectives and constraints the language models have to follow. Then, each agent sequentially follows this five-step process to produce the SOP or work for the next agent to use and build upon. Starting by defining what they need to do based on their specific role, description, and objectives. Then they observe what the previous agents did or said and start acting from there. They finally update their to-do list based on the generated SOP and update its status on what it is doing for the other agents to know. Finally, it can also broadcast messages about its results and actions to share with the other agents.
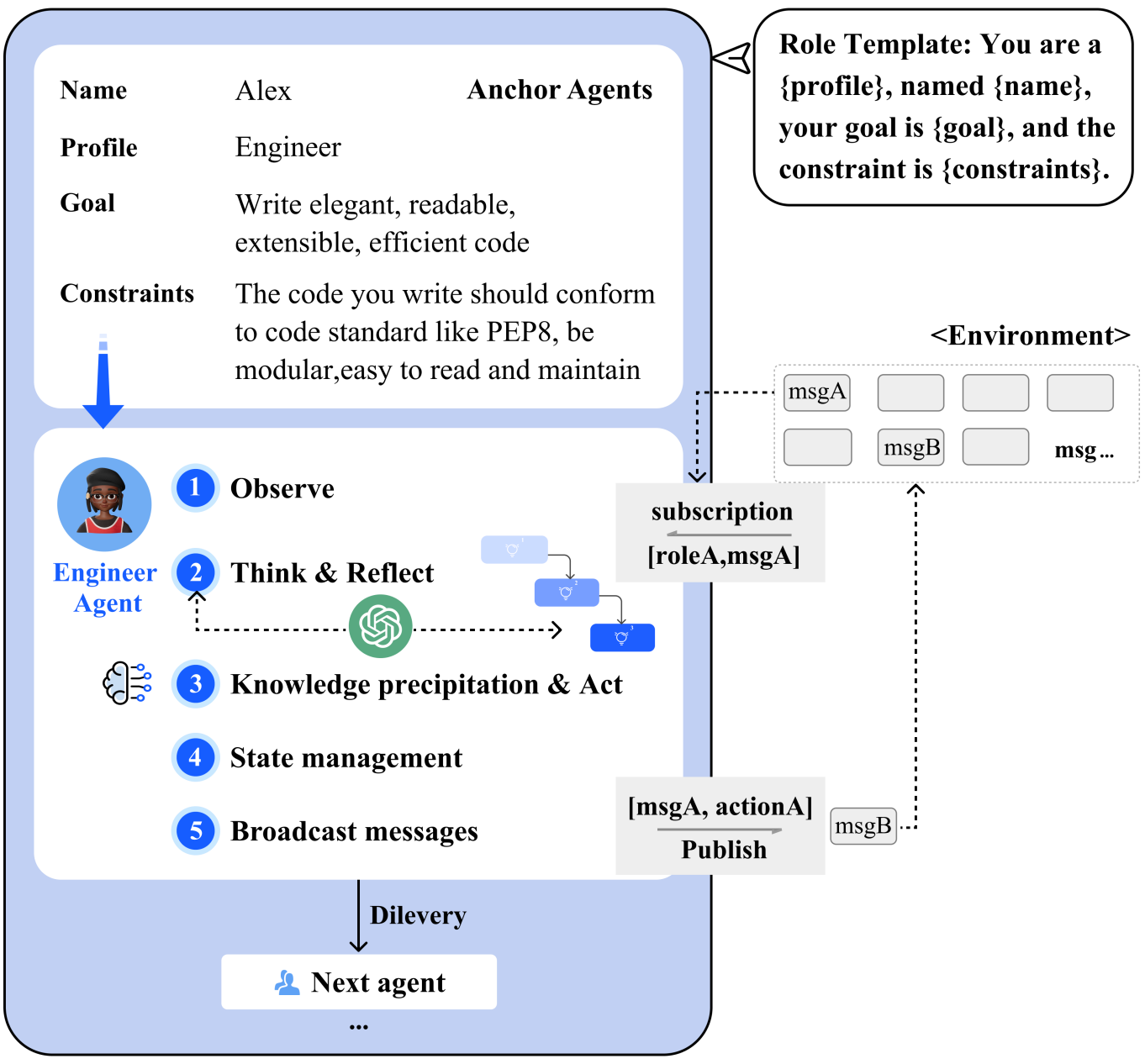
Figure 2: Overview of the MetaGPT framework. Image from the paper.
Here’s a concrete example with our same five agents building the 2048 game. Each agent has their own knowledge, tasks, and requirements based on their thinking step and the user inputs. They each accomplish their respective tasks and ask questions to other agents when needed. Of course, there are a lot of engineering challenges in combining those agents and different parts to work well together. It’s truly an impressive work from the researchers, and I want to congratulate them for it. This multi-agent process might be the most challenging but most interesting use-case of large language models, and I am super excited to see where it leads us.
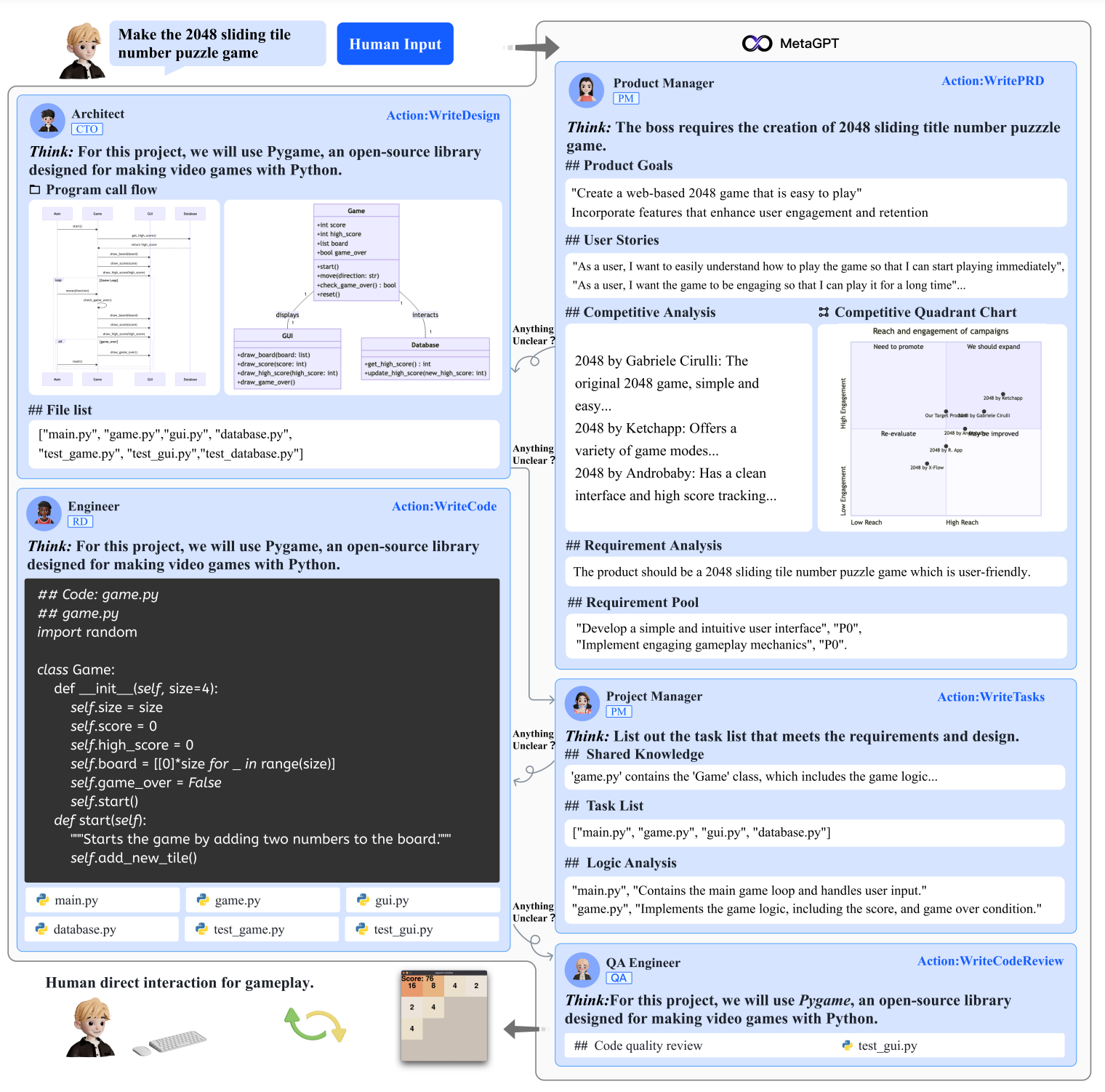
Figure 3: A schematic diagram of the software development process within the MetaGPT framework. Image from the paper.
I hope you’ve enjoyed this short overview of how MetaGPT is able to efficiently chain multiple agents to mitigate hallucinations and solve complex tasks with a single prompt and user directives. I omitted important engineering details that make this whole system work for simplicity, but if you are curious, I invite you to read the paper linked below for more information on how the framework was built and works. The code is also fully open-sourced if you’d like to try it for yourself. On my end, I will see you next time with another amazing paper!
References
- Hong et al., 2023: MetaGPT, https://arxiv.org/pdf/2308.00352.pdf
- Code: https://github.com/geekan/MetaGPT/blob/main/README.md
FAQ
What is the useful lesson from Mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
What is MetaGPT? LLM Agents Collaborating to Solve Complex Tasks. The goal of MetaGPT is simple: replace each with a fictive human being: a GPT model.
What should builders test before using mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
Since we trained the AI model to provide an answer to all questions, it does so even if it does not have the right answer to your question.
What is the main LLM risk with mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
Many of such systems that only require an initial prompt like “build me a flappy bird-like game” already exist, like Auto-GPT, BabyAGI, or AgentGPT, but have a shared problem.
How should builders use mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
You can see how it can become a problem for one AI model, but imagine what happens if you connect many of them together without human supervision.
When does mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework become useful in practice?
For example, if we wanted to build a Flappy Bird game, our first agent could be responsible for defining the game.
What should beginners understand about mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
It’s much more easy to divide a complex problem into a few clear small problems that you solve individually and combine the answers.
What is the common mistake with mitigating AI Hallucinations: Exploring MetaGPT's Collaborative Framework?
Many of such systems that only require an initial prompt like “build me a flappy bird-like game” already exist, like Auto-GPT, BabyAGI, or AgentGPT, but have a shared problem.