

The short version
Adaptive Discriminator Augmentation reduces GAN overfitting on limited datasets by applying random transformations to both real and generated images before the discriminator sees them. It adjusts augmentation strength during training from an overfitting signal, while keeping transformations from leaking into generated outputs. In the 2020 StyleGAN2 experiments, this matched earlier quality with roughly an order of magnitude fewer images; results still depend on the dataset and architecture.
This new paper covers a technique for training a GAN architecture. They are used in many applications related to computer vision, where we want to generate a realistic transformation of an image following a specific style. If you are not familiar with how GANs work, I definitely recommend you to watch the video I made explaining it before continuing this one.
As you know, GANs architecture trains in an adversarial way. Meaning that there are two networks training at the same time, one training to generate a transformed image from the input, the generator, and the other one training to differentiate the generated images from the training images’ ground truths. These training images’ ground truths are just the transformation result we would like to achieve for each input image. Then, we try to optimize both networks at the same time, thus making the generator better and better at generating images that look real. But, in order to produce these great and realistic results, we need two things. A training dataset composed of thousands and thousands of images, and stopping the training before overfitting.
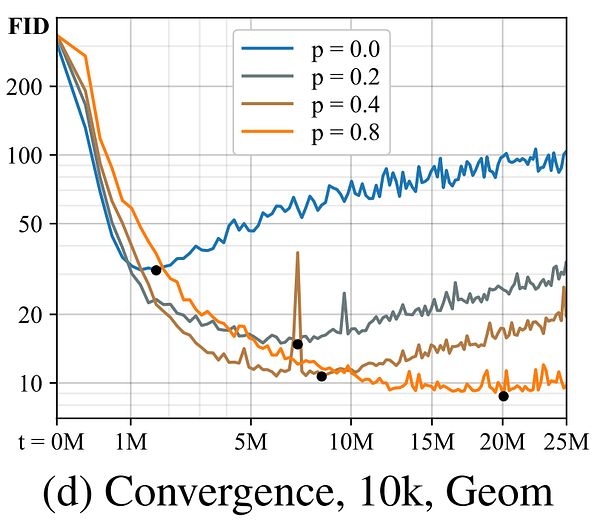
Image via: Training Generative Adversarial Networks with Limited Data by NVIDIA
Overfitting during a GAN training would mean that our discriminator’s feedback would become meaningless and the images generated will only get worse. It happens past a certain point when you train your network too much for your amount of data, and the quality only gets worse, as you can see happening here after the black dots.
These are the problems NVIDIA tackled with this paper. They realized that this is basically the same problem, and could be solved by one solution. They proposed a method they called an adaptative discriminator augmentation. Their approach is quite simple in theory, and you can apply it to any GAN architecture you already have without changing anything.
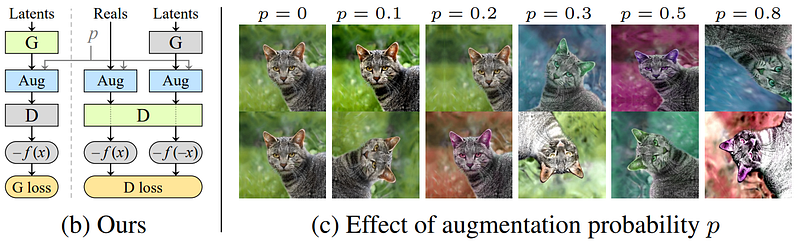
Image via: Training Generative Adversarial Networks with Limited Data by NVIDIA
As you may know, in most areas of deep learning, we perform what we call data augmentation to fight against overfitting. In computer vision, it often takes the form of applying transformations to the image during the training phase to multiply our quantity of training data. These transformations can be anything from applying a rotation, adding noise, changing the colors, etc. to modify our input image and create a unique version of it. Making our network train on a way more diverse dataset without having to create or find more images. Unfortunately, this cannot be easily applied to a GAN architecture since the generator will learn to generate images following these same augmentations. This is what NVIDIA’s team has done. They found a way to use these augmentations to prevent the model from overfitting while ensuring that none of these augmentations are leaked onto the generated images. They basically apply this set of image augmentations to all images shown to the discriminator with a chosen probability of each transformation to randomly occur and evaluate the discriminator’s performance using these modified images. This high number of transformations all applied randomly makes it very unlikely that the discriminator sees even one unchanged image. Of course, the generator is trained and guided to generate only clean images without any transformations. They’ve concluded that this method of training a GAN architecture with augmented data shown to the discriminator works only if each transformation’s occurrence probability is below 80%. The higher it is, the more augmentations will be applied and thus a more diverse training dataset you will have.
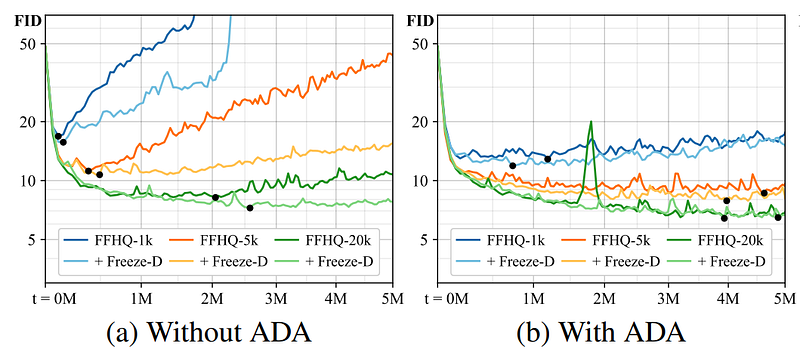
Image via: Training Generative Adversarial Networks with Limited Data by NVIDIA
They found that while this was solving the question of the limited amount of training images, there was still the overfitting issue that appeared at different times based on your initial dataset’s size. This is why they thought of an adaptative way of doing this augmentation. Instead of having another hyper-parameter to decide the ideal augmentation probability of appearance, they instead control the augmentation strength during the training. Starting at 0, and then adjust its value iteratively based on the difference between the training and validation sets. Indicating if overfitting is happening or not. This validation set is just a different set of the same type of images that the network is not trained on. The validation set just needs to be made of images that the discriminator hasn’t seen before. It is used to measure the quality of our results and quantify the degree of divergence of our network, quantifying overfitting at the same time.
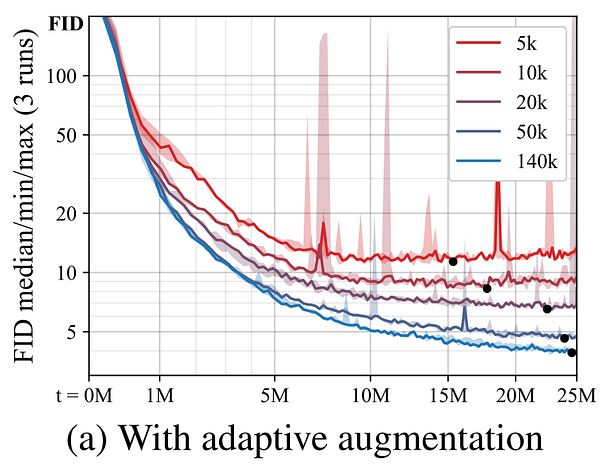
Image via: Training Generative Adversarial Networks with Limited Data by NVIDIA
Here, you can see the results of this adaptative discriminator augmentation for multiple training set sizes on the FFHQ dataset. Here, we use the FID measure, which you can see getting better and better over time and never reaching this overfitting problem where it starts to get only worse. The FID, or Fréchet inception distance, is basically a measure of the distance between the distributions for generated and real images. It measures the quality of the generated image samples. The lower it is, the better our results.

This FFHQ dataset contains 70 000 high-quality faces taken from Flickr. It was created as a benchmark for generative adversarial networks. And indeed, they successfully matched StyleGAN2 results with an order of magnitude fewer images used as you can see here.
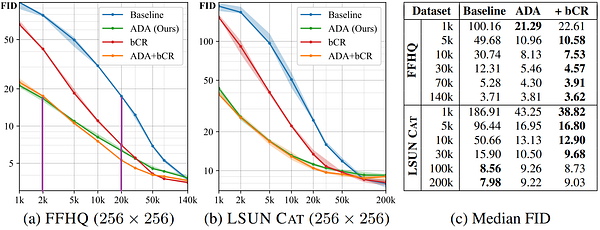
Image via: Training Generative Adversarial Networks with Limited Data by NVIDIA
Where the results are plotted for 1 000 to 140 000 training examples using again this same FID measure on the FFHQ dataset.
Watch the video for more examples of this new training method:
Conclusion
Of course, the code is also completely available and easy to implement to your GAN architecture using TensorFlow. Both the code and the paper are linked in the references below if you would like to implement this in your code or have a deeper understanding of the technique by reading the paper. This paper was just published in the NeurIPS 2020, as well as another announcement by NVIDIA. They announced a new program called the applied research accelerator program. Their goal here is to support research projects to make a real-world impact through deployment into GPU-accelerated applications adopted by commercial and government organizations. Granting hardware, funding, technical guidance, support, and more to students. You should definitely give it a look if that fits your current needs, I linked it in the description of the video as well!
If you like my work and want to support me, I’d greatly appreciate it if you follow me on my social media channels:
- The best way to support me becoming a free member of this blog and get notified on new articles.
- Subscribe to my YouTube channel.
- Follow my projects on LinkedIn
- Learn AI together, join our Discord community, share your projects, papers, best courses, find Kaggle teammates, and much more!
References
Training Generative Adversarial Networks with Limited Data by NVIDIA. Published in the NeurIPS 2020 conference. https://arxiv.org/abs/2006.06676
ADA — GitHub with code. https://github.com/NVlabs/stylegan2-ada
NVIDIA Research. https://www.nvidia.com/en-us/research/
FAQ
What is NVIDIA's adaptive discriminator augmentation?
ADA changes augmentation strength during GAN training to prevent the discriminator from memorizing a small dataset.
Why do GANs overfit with limited images?
The discriminator can memorize real examples, leaving the generator with an unhelpful training signal.
How does augmentation help the discriminator?
Transformations create varied views of training images while preserving the underlying content it should recognize.
Why keep transformation probability below a limit?
Excessive augmentation can leak into generated images or distort the task; the study found probabilities below 80 percent worked better.
How was generation quality monitored?
The researchers tracked FID over training to detect improvement and avoid the degradation associated with overfitting.