


Image from Perfusion’s project page.
Watch the video…
If DALLE or MidJourney doesn’t ring any bell, then I don’t really know what to do with you. You are already familiar with text-to-image models, for sure. But you may also know that they are not really good when conditioned with images. Meaning that if you’d like to generate an image of yourself or include a specific object like this teddy bear in specific conditions, it might not work that well.
Those AI usually understand what you want and tries to generate new images, including something similar that you sent, but it’s far from perfect, and you can often clearly see it is not the same object. Well, that’s about to change with a new model from NVIDIA: Perfusion.
Perfusion is much better than all previous approaches at matching the generated results with the original image. So it is basically a stable diffusion with even more control over the output! Maintaining fidelity is extremely challenging for those generative models while also allowing you to create new images in different contexts.

Image from Perfusion’s project page.
So how did they do that? And what’s the state of the art for finally generating tons of amazing new images of yourself for your Instagram page without needing to go out and actually take pictures!
Oh, and how can we do that without having an immense model that only OpenAI can use? Because, in their case, Perfusion is five orders of magnitude smaller than current state-of-the-art generative models.
Which means its size is around 100KB! Seems like magic, right? Well, let’s dive into that!
This is what Perfusion is. When we say more control, we actually mean that the model is able to learn the “concept” of an object, animal, or person and then generate these concepts in new scenarios.
And for this article, I will assume you read my articles on DALLE and stable diffusion and will focus on the innovation of this approach rather than covering how it works from scratch. What’s different here is they add a new mechanism to allow the model to be able to lock concepts like our teddy bear.
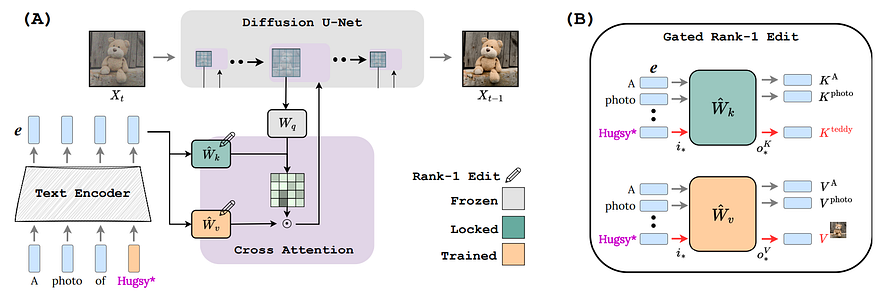
Model overview. Image from Perfusion’s project page.
They also add a way to give multiple concepts that can all be locked so that we can generate an image including multiple items we want, which can be quite cool for advertisement creation and many industries! Leading to much better results both quantitatively and qualitatively than ever before when it comes to text-to-image generation with attached concepts. This is a rather complicated task since they need to optimize for two objectives, representing the concept accurately while also not overfitting to the image examples of the concept and allowing for personalization of the generated image. So basically, focusing the model’s attention on only the concept and not the whole images sent.
And how can we do that?
Well, it is obviously by using a very similar diffusion architecture but adding a few cool tricks to allow for concepts to be locked efficiently and reduce the model size with a technique called Rank-1 Model editing. So as we always see in current text-to-image models based on diffusion, which look like this, there’s always a text prompt that is encoded to extract relevant information.
Then this information is added one way or the other, usually through the cross-attention mechanism to our image generation process, which is an iterative process, as I explained in my diffusion article if you are not familiar with the model architecture!
It is in this space with the cross-attention step that they worked. This Rank-1 edit, or gated rank-1 edit here, will help the model understand where the images are located in the final image as well as control what appears in the final image. So we have two objectives, the “where” and the “what”, respectively represented by k and v. They are also using super categories instead of relying on the words themselves, so here, for example, they will edit the word to the super concept “teddy” however we refer to it in the prompt. Like when we use its name Hugsy in this case or any other synonym to say a teddy bear, the model will transform the encodings of the prompt to fit the encoding of teddy so that the model always knows we are referring to it.
Remember, it is called gated rank-q edit. This gated part comes from the fact that, during training, weight updates of the model are only applied to the encoding components that match the concept. This gate is the reason why we can send it multiple concepts, and it still works quite well! It also allows us to regulate the strength of learned concepts, providing much more control than other approaches.
And those are the only modifications they’ve done! Otherwise, it is just the stable diffusion architecture and the same principles, tweaking the encoded prompts to better control the results!

Model limitation and duality between overfitting and generalization. Image from Perfusion’s project page.
It is still not perfect, but a great step forward for text-to-image models with full control on the generation! Here, it still struggles with keeping the identity of the object we send it because of this step we covered where we refer to the object as a “super category”, which sometimes leads to over-generalization since some super categories are too broad and include many different objects or specific styles that we don’t necessarily want. They also mention that combining concepts require lots of prompt engineering work, another reason to learn how to do better prompting!
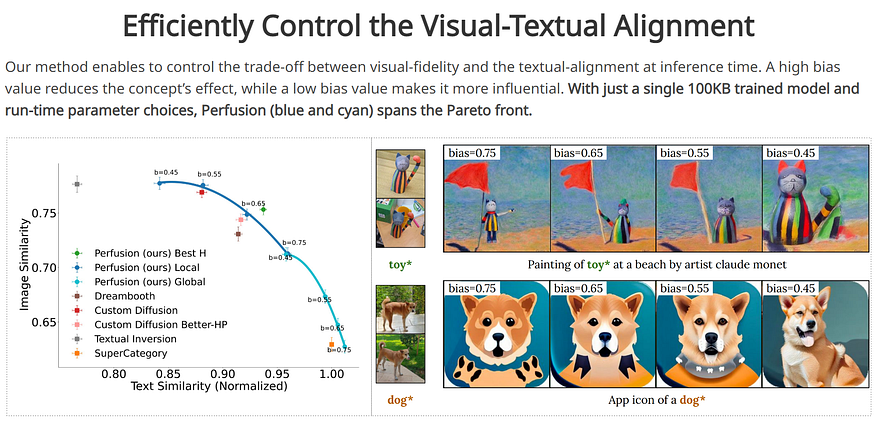
In green, the Perfusion model optimizing for image and prompt similarity. Image from Perfusion’s project page.
Still, the results are super impressive and the code will be available shortly.
I’m excited to see how it will be used! I hope you’ve enjoyed this overview of the new Perfusion paper and I invite you to read it for more details on the implementation and quantitative details. It’s an amazing and super clear paper. All the links are in the description below.
Thank you for reading and I will see you next time with another amazing paper!
References
- Tewel et al., 2023: NVIDIA. https://arxiv.org/abs/2305.01644
- Project link: https://research.nvidia.com/labs/par/Perfusion/