

The short version
RAD-NeRF turns new audio into a real-time talking-head video after learning one speaker from about five minutes of video. This 2022 research system separates compact audio and spatial features, renders the moving head with a grid-based NeRF, and handles the mostly rigid torso with a simpler 2D module. That design improved speed, quality, and control in the paper's comparisons, while also making impersonation risks harder to ignore.
Watch the video
We’ve heard of deepfakes, we’ve heard of NeRFs, and we’ve seen these kinds of applications allowing you to recreate someone’s face and pretty much make him say whatever you want.
What you might not know is how inefficient those methods are and how much computing and time they require. Plus, we only see the best results. Keep in mind that what we see online is the results associated with the faces we could find most examples of, so basically, internet personalities and the models producing those results are trained using lots of computing, meaning expensive resources like many graphics cards. Still, the results are really impressive and only getting better.
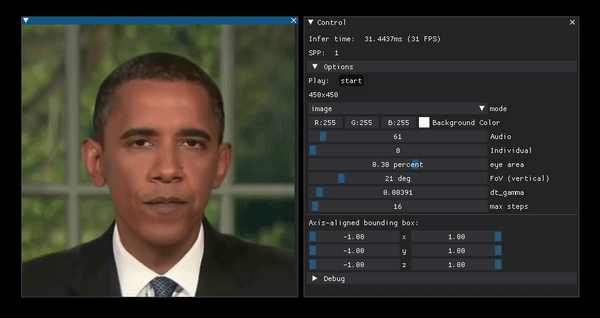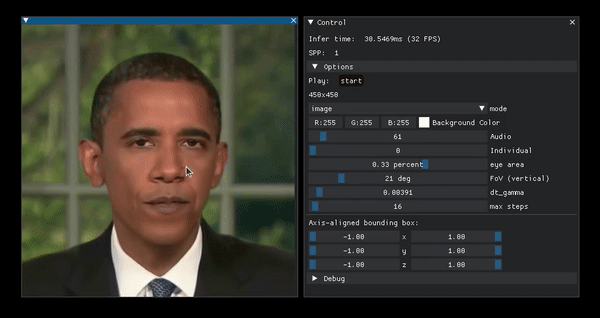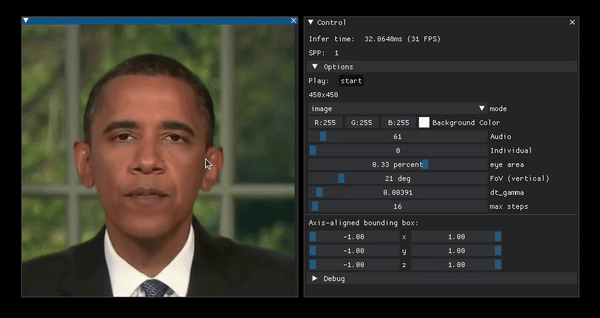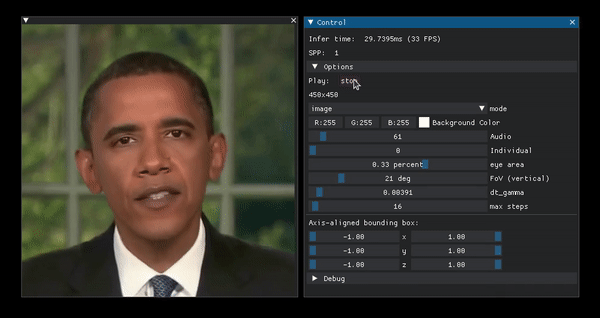
Portrait manipulation example from the project page.
Fortunately, some people like Jiaxian Tang and colleagues are working on making those methods more available and effective with a new model called RAD-NeRF.
From a single video, they can synthesize the person talking for pretty much any word or sentence in real time with better quality. You can animate a talking head following any audio track in real-time. This is both so cool and so scary at the same time.

Quality comparison with different approaches, their method being the last column. Image from the paper.
Just imagine what could be done if we could make you say anything. At least, they still need access to a video of you speaking in front of the camera for five minutes, so it’s hard to achieve that without you knowing. Still, as soon as you appear online, anyone will be able to use such a model and create infinite videos of you talking about anything they want. They can even host live streams with this method, which is even more dangerous and makes it even harder to say what’s true or not. Anyways, even though this is interesting, and I’d love to hear your thoughts in the comments and keep the discussion going, here I wanted to cover something that is only positive and exciting: science. More precisely, how did they achieve to animate talking heads in real-time from any audio using only a video of the face…
As they state, their RAD-NeRF model can run 500 times faster than the previous works with better rendering quality and more control. You may ask how is that possible? We usually trade quality for efficiency, yet they achieve to improve both incredibly.
These immense improvements are possible thanks to three main points.
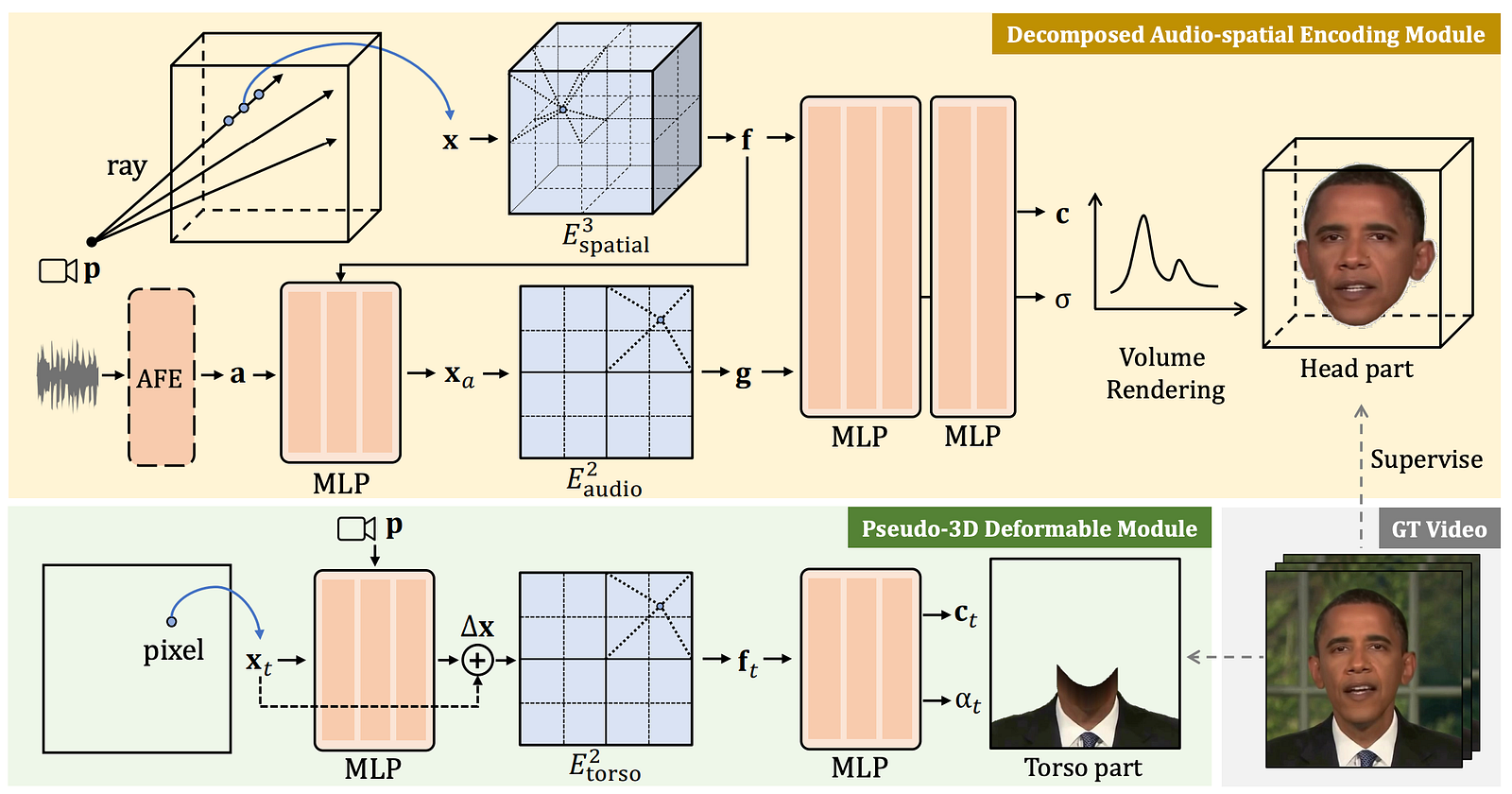
Overview of RAD-NeRF. Image from the paper.
The first step is to make NeRFs more efficient (yellow rectangle in the overview of the model). I won’t dive into how NeRFs work since we covered it numerous times. Basically, it is an approach based on neural networks to reconstruct 3D volumetric scenes from a bunch of 2D images, which means regular images. This is why they will take a video as input, as it basically gives you a lot of images of a person from many different angles.
So it usually uses a network to predict all pixels colors and densities from the camera viewpoint you are visualizing and does that for all viewpoints you want to show when rotating around the subject, which is extremely computation hungry as you are predicting multiple parameters for each coordinate in the image every time learning to predict all of them. Plus, in their case, it isn’t only a NeRF producing a 3D scene. It also has to match an audio input and fit the lips, mouth, eyes, and movements with what the person says.
Instead of predicting all pixels’ densities and colors matching the audio for a specific frame, they will work with two separate new and condensed spaces called grid spaces, or grid-based NeRF. They will translate their coordinates into a smaller 3D grid space, translate their audio into a smaller 2D grid space, and then send them to render the head. This means they never merge the audio data with the spatial data, which would increase the size exponentially, adding 2-dimensional inputs to each coordinate. So reducing the size of the audio features along with keeping the audio and spatial features separate is what makes the approach so much more efficient.
But how can the results be better if they use condensed spaces that have less information? Adding a few controllable features like an eye blinking control to our grid NeRF, the model will learn more realistic behaviors for the eyes compared to previous approaches. Something really important for realism.
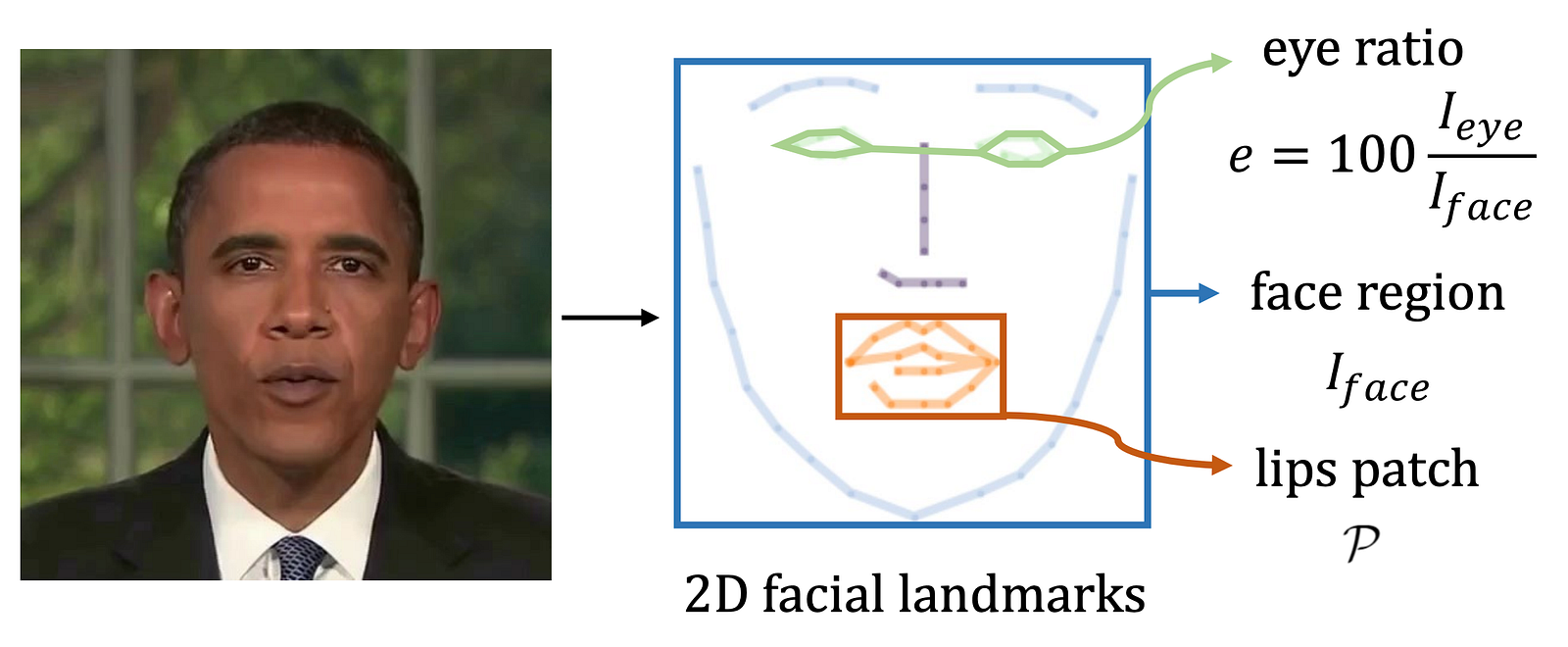
Facial landmarks used. Image from the paper.
The second improvement (green rectangle in the overview of the model) they’ve done is to model the torso with another NeRF using the same approach instead of trying to model it with the same NeRF used for the head, which will require much fewer parameters and different needs as the goal here is to animate moving heads and not whole bodies. Since the torso is pretty much static in these cases, they use a much simpler and more efficient NeRF-based module that only works in 2D, working in the image space directly instead of using camera rays as we usually do with NeRF to generate many different angles, which aren’t needed for the torso. So it is basically much more efficient because they modified the approach for this very specific use case of the rigid torso and moving head videos. They then recompose the head with the torso to produce the final video.
And voilà! This is how you produce talking head videos over any audio input efficiently!
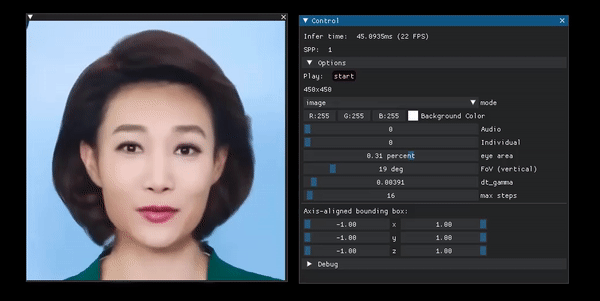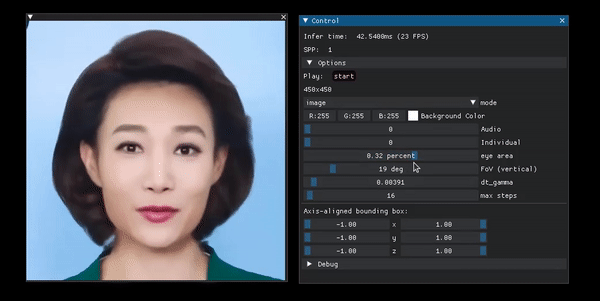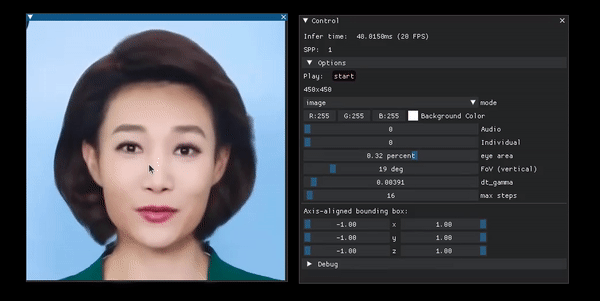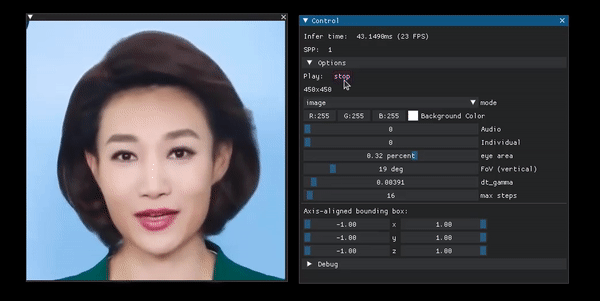
Portrait manipulation example from the project page.
Of course, this was just an overview of this new exciting research publication, and they do other modifications during the training of their algorithm to make it more efficient, which is the third point I mentioned at the beginning of the article. I invite you to read their paper for more information. The link is in the references below.
Before you leave, I just wanted to thank the people who recently supported this channel through Patreon. This is not necessary and strictly to support the work I do here.
Huge thanks to Artem Vladykin, Leopoldo Altamirano, Jay Cole, Michael Carychao, Daniel Gimness, and a few anonymous generous donors. It would be greatly appreciated if you also want and can afford to support my work financially on Patreon. But no worries if not. Sincere feedback on this article is all I need to be happier!
I hope you’ve enjoyed this article and I will see you next week with another amazing paper!
References
►Tang, J., Wang, K., Zhou, H., Chen, X., He, D., Hu, T., Liu, J., Zeng, G. and Wang, J., 2022. Real-time Neural Radiance Talking Portrait Synthesis via Audio-spatial Decomposition. arXiv preprint arXiv:2211.12368.
►Results/project page: https://me.kiui.moe/radnerf/
FAQ
What does RAD-NeRF generate?
RAD-NeRF creates a real-time talking-head video driven by new audio after learning one person's face and speech motion.
What training input does it require?
The system needs roughly five minutes of video showing the target person speaking toward the camera.
How can audio animate a face?
The model maps speech features to facial motion and renders the corresponding neural 3D head over time.
Why is real-time rendering important?
Fast inference supports interactive avatars, live communication, localization, and responsive digital assistants.
What misuse risk comes with talking-head synthesis?
A convincing avatar can impersonate someone, so consent, disclosure, provenance, and access controls are essential.