How Smart Are Reasoning Models in 2025?
The Future of LLMs

Watch the video!
Imagine you open ChatGPT and ask the old strawberry question: “How many R’s are in the word strawberry?”
Two years ago, the model would shrug, hallucinate, or — if you were lucky — guess correctly half the time. Today, with the shiny new “reasoning” models, you press Enter and watch the system think. You actually see it spelling s-t-r-a-w-b-e-r-r-y, counting the letters, and then calmly replying “three”. It feels almost magical, as if the model suddenly discovered arithmetic. Spoiler: it didn’t. It has just learned to spend more tokens before it answers you. And it can afford that luxury because the raw capacity underneath has already ballooned from the 117 M-parameter GPT-2 (1.5 B in its largest flavour) that munched on eight billion WebText tokens to trillion-parameter giants trained on roughly 15 trillion tokens — essentially the entire readable web — spread across clusters of tens of thousands of H100 GPUs.
That tiny detour is the heart of the newest wave in large-language-model research. For years, we lived by one rule — scaling laws. Principles where the more we push them to their limit, the better the results are. More model parameters plus more data equals more skills. Bigger bucket, bigger pile of internet, better performance. But buckets don’t grow forever: we’re scraping the bottom of the web, and GPUs are melting data-centre walls. It seems like we are going into what many researchers call a “pre-training plateau.”
So, instead of tackling the consciousness issue, researchers turned around and asked, “What if we can’t scale the model any further? Could we scale the answer time instead?”
And here, reasoning models were born: same neural guts, same weights, but a new inference-time scaling law — more compute after the user clicks send with the hypothesis that if the results are good enough, we, the users, will be fine with waiting a few seconds, minutes or even more.
Here’s how it works in practice:
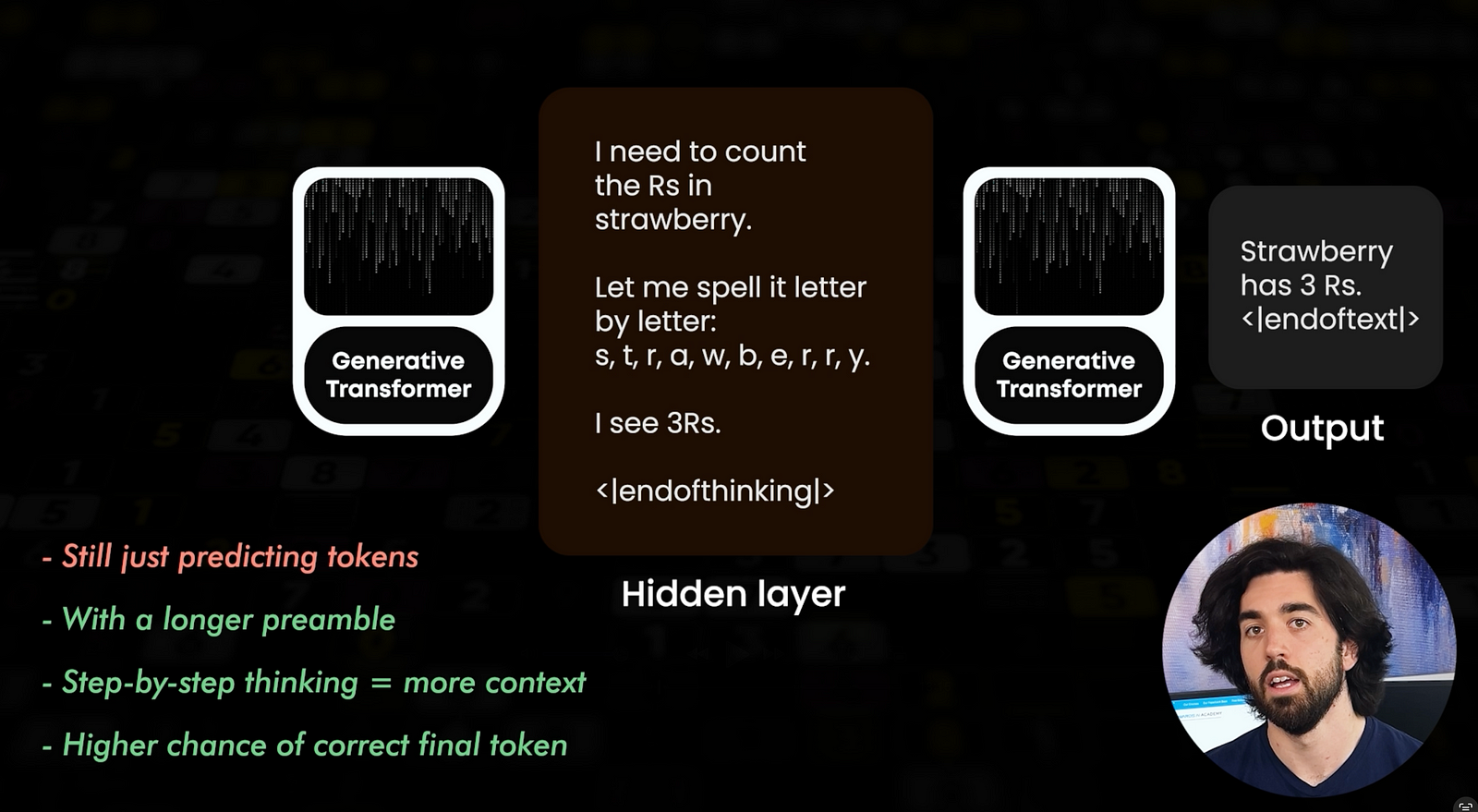
A classic GPT-style model produces one token at a time until it hits an end-of-text marker. Like this. And it learns to generate that token autonomously during its training when it’s done answering, since we’ve manually added this exact same token in all our training examples, to teach it to do so. If you are already lost, I suggest watching our introduction to large language models to get a good grasp of tokens and embeddings, which will really help you better understand and leverage LLMs in general!
Instead of this usual single-stream token generation, reasoning models generate two streams. First comes a hidden monologue, the chain of thought, which is basically the same as the popular chain-of-thought prompting technique. Engineers literally introduced a new token — end-of-thinking — to mark where that private scratch-pad stops. Only after the scratch-pad is closed does the model write the polished answer and emit the usual end-of-text. The model hasn’t become logical in the human sense. It’s still predicting the next most probable token. It simply predicts a longer pre-amble now, walks through the solution step by step, and therefore raises its own chance of guessing the final token correctly, by providing itself more context, nudging the probability in its favour one token at a time.
And how do you get such a “reasoning” model?
To get a reasoning model, you start from a giant pre-trained model, like GPT-4 or Gemini-class. So it follows the same pre-training step you already know if you’ve watched my videos before. Then, you build a dataset where each example contains a question, a full chain-of-thought proof, and the final answer. Code and Mathematics are popular because proofs and code are verifiable and binary: either the theorem is solved or it isn’t, either the code runs or not. Then, feed those triples into a supervised fine-tuning pass so the network learns to place end-of-thinking before end-of-text. Then add a reinforcement-learning loop. Instead of rewarding every token, you grade only the final answer with a special function or a judge — maybe another language model, maybe a human, maybe a compiler if the task is code. Good answer? No gradient update. Bad answer? Tiny penalty. This is super similar to the reinforcement fine-tuning OpenAI recently announced, where a dozen such examples can shift style and structure towards your goals. Finally, run a balancing phase where the model practices questions that need zero, little, or a lot of reasoning so it learns when to keep quiet and when to spend lots of time (and compute) thinking. Just like how we can answer on the fly for basic 2+2 questions, but need a pen and paper, or even a calculator, for a more complex integral.
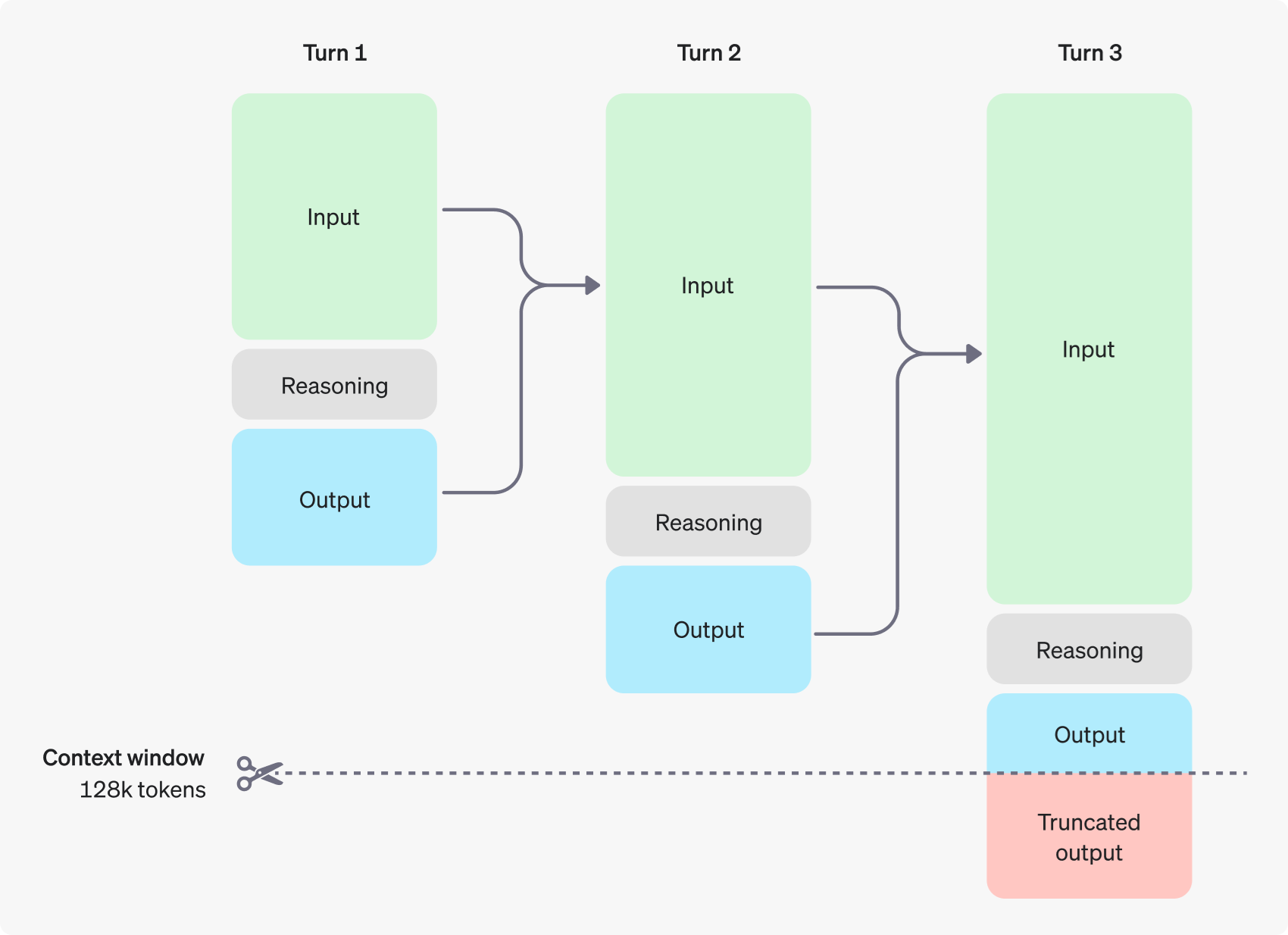
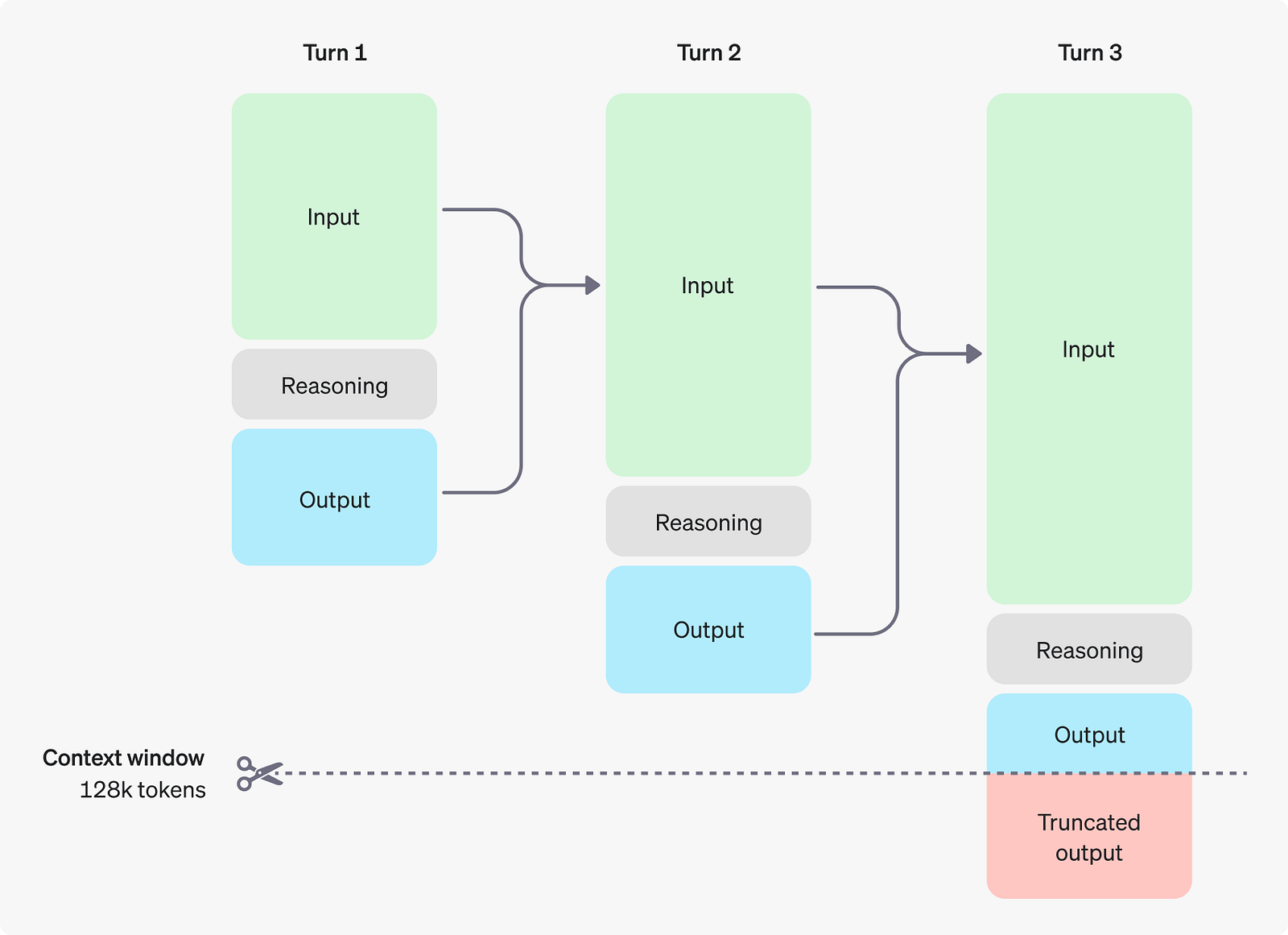
Thanks to this whole training process, at deployment, the model decides on the fly how long to think. Ask it a trivial fact, and it might whisper one or two hidden lines, punctuate end-of-thinking, and answer instantly. Ask it to design a novel sorting algorithm and you may watch it mull for sixty seconds, chewing through hundreds of tokens of private deduction before it speaks. That delay costs real money: every thinking token is an API charge and a GPU cycle. Multiply that by the loop inside an agent that calls the model ten times, and suddenly your side project feels like renting a small data-centre. That’s the dark side of our new scaling axis: we replaced parameter growth with inference-time growth and the bill followed.

By the way, OpenAI doesn’t show this thinking process, so you need to be careful about that. They only send a controlled summary, which isn’t what the model actually generated in its thinking, so you can’t use that to train your own thinking model. Oh, and if a part of the hidden reasoning is crucial for the next turn of the conversation, copy it into your follow-up prompt, because the model itself will forget — its private notes are not automatically passed to the next round!
The prompting advice changed with these new types of models, too. With ordinary LLMs, we often said to write something like “Let’s think step by step” or give it a plan of action like “First list the letters, then count the R’s.”
With reasoning models, you don’t need to. The chain-of-thought is baked in. Instead, you mainly want to give it a goal and the core restrictions and guidelines you want it to follow. It will then come up with the steps and necessary actions to accomplish the task. So, here, the more information about what you want, contrary to information about how to proceed, the better. And if you care about latency or cost, ask explicitly for concise thinking: “Reason briefly for at most five steps, then answer.” You’re paying for tokens; make the writer conscious of that — and likewise if you want a very deep answer!
Now, how does all this connect to the famous scaling laws we started with? Think of classic scaling as two axes: parameters and data. We stretched them until we hit physical walls — electric bills, atom-sized transistors, a shrinking pile of new text. Reasoning models add a third axis that we call test-time or inference-time compute. Instead of buying a taller bucket or stuffing it with more internet, we shake the bucket longer each time we fetch something from it. It’s a clever hack, but it also inherits the law of diminishing returns. Early experiments — OpenAI’s O1, DeepSeek R1 — show big gains on math and code benchmarks with moderate extra thinking. Double the scratch-pad again, and the curve flattens. Eventually, you’re feeding the model so many of its own tokens that you can’t nudge it towards a better answer if it didn’t know it already in its own knowledge base. Which links this axis of scaling to another one: tool use, and thus, agents, which we’ve covered in another video recently.
And let’s address the elephant: does this mean machines are finally “reasoning”? Not more than yesterday. They’re still next-token predictors. Super powerful statistical machines predicting one token at a time. The apparent logic it gains comes from sampling more conditional probabilities, not from symbol manipulation or causal world models. The chain-of-thought helps the model expose intermediate states that were previously hidden, which makes the final guess better and easier for humans to audit. But under the hood, every step is the same statistical game we’ve played since GPT-2 — just looped longer on more data and more compute.
Where does that leave us? With more options and more potential. For simple customer-support replies, stick to small, faster models. For complex research questions or multi-step code generation, rent a reasoning model, budget for the tokens, and enjoy the extra depth. If you need even more power and capabilities, browse the web, code, plan tasks, and cite sources, build an advanced workflow or even an agent leveraging the power of reasoning models, and tools. But you are not stuck with using one or the other! In a complex system, we usually combine both reasoning models as being the “brain” of the agent, and non-reasoning models as “actors” doing what the brain told them to do, whether it is to translate, use a tool or do specific actions. By the way, we teach to combine these models and more in our agents-focused course in partnership with my friends at Decoding ML. If you are interested in learning more about agents and building agentic systems yourself, check out the course here: https://academy.towardsai.net/courses/agent-engineering?ref=1f9b29.
Just keep an eye on power bills and on new accelerator chips — someone has to pay for the extra seconds of GPU time, and our planet pays for it too. So please, for both sakes, use the simplest model or the simplest solution that fixes your problem.
We started the article counting letters in a fruit and ended with a new scaling law that demonstrates that you can spend a little extra computing time at inference time to buy a lot more reasoning. Whether that shortcut carries us all the way to AGI or just buys a little breathing room before the next hardware leap is still an open question. But for now, if you feel your model isn’t smart enough, don’t rush to train a bigger one — try letting it think out loud first, then decide if the answer was worth the extra tokens!
I hope you’ve enjoyed this article. If you did, please share it with a friend and spread the knowledge! Thank you for reading, and I’ll see you in the next one!