

The short version
MODNet was a 2020 method for removing a person's background from a single image without a green screen or manually supplied trimap. It decomposes human matting into low-resolution semantic estimation, high-resolution boundary detail, and a fusion branch, using MobileNetV2 for efficiency and a one-frame-delay technique for steadier video. The reported real-time speed and comparisons belong to the paper's period, not today's product landscape.
Watch the video and support me on YouTube!
Introduction
Human matting is an extremely interesting task where the goal is to find any human in a picture and remove the background from it. It is really hard to achieve due to the complexity of the task, having to find the person or people with the perfect contour. In this post, I review the best techniques used over the years and a novel approach published on November 29th, 2020. Many techniques are using basic computer vision algorithms to achieve this task, such as the GrabCut algorithm, which is extremely fast, but not very precise.
GrabCut [4]
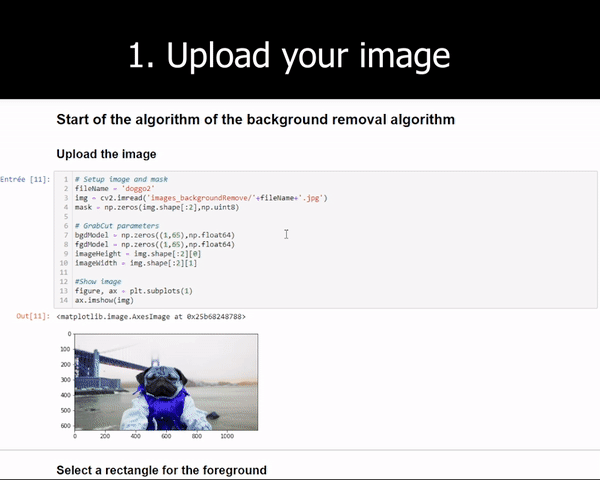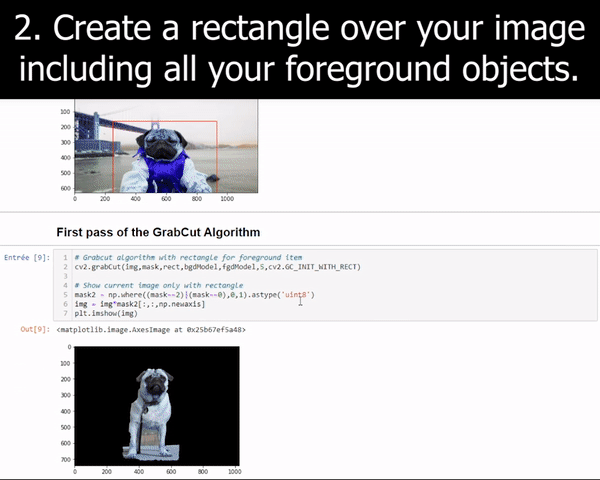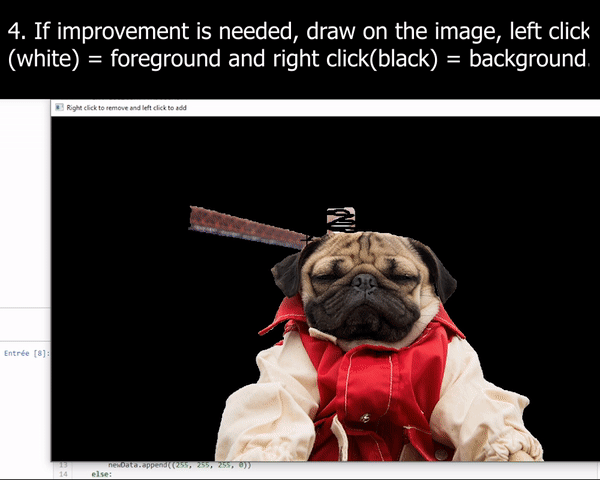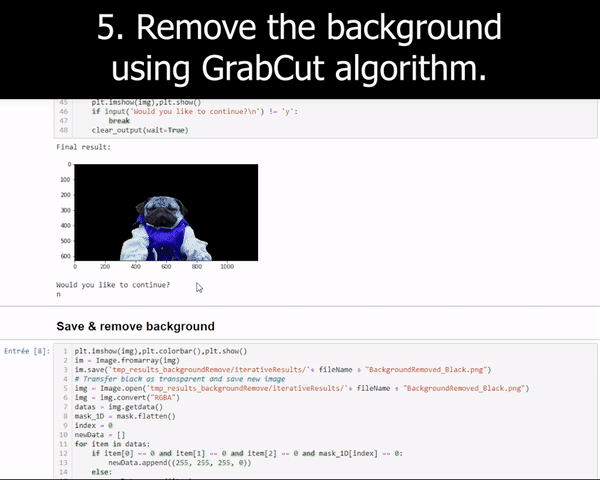
Image by Author
This GrabCut algorithm basically estimates the color distribution of the foreground item and the background using a gaussian mixture model. We draw a rectangle over the object of interest (the foreground) and iteratively tries to improve the results by drawing over the parts the algorithm failed to add pixels to the foreground or remove a set of pixels from the foreground. This is why we often use a “green screen”, helping the algorithms to remove only the green pixels and leave the rest into the final results. But the results are not so great when we do not have access to such a green screen.
Deep Image Matting [3]
Modern deep learning and the power of our GPUs made it possible to create much more powerful applications that are yet not perfect. The best example here is Deep Image Matting, made by Adobe Research in 2017. A version of this model is currently used in most websites you use to automatically remove the background from your pictures. Unfortunately, this technique needs two inputs: an image, and its trimap. A trimap is basically a representation of the image in three levels: the background, the foreground, and a region where the pixels are considered as a mixture of foreground and background. Looking like this.


To successfully remove the background using the Deep Image Matting technique, we need a powerful network able to localize the person somewhat accurately. Then, we produce a segmentation where the pixels equivalent to the person are set to 1, and the rest of the image is set to 0. Next, we use basic computer vision transformations to create a trimap from this segmentation. We start by reducing the size of the segmented object to leave a bit of space for the unknown region by eroding it, removing some pixels at the contour of the object iteratively. After that, we add this third section, which is the unknown region, by dilating the object, adding pixels around the contour. Producing a result like this. This trimap is the one sent to the Deep Image Matting model with the original image, and you get your output. You can see how much computing power is needed for this technique. Using two powerful models if you would like to achieve somewhat accurate results.




Trimap progression. Segmentation of the object (left), erode the segmentation (middle), add the unknown region with dilations (right). Image by Author.
As you just saw on the cover picture, the current state-of-the-art approaches are quite accurate, but they need a few seconds and sometimes up to minutes to find the results for a single image. You can just imagine the time it would need to process a whole video.
MODNet [1]
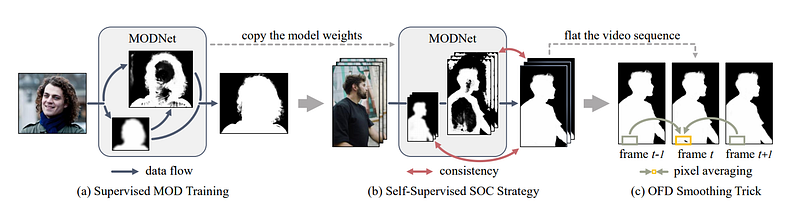
Human Matting framework. “a) We train MODNet on the labeled dataset to learn matting sub-objectives from RGB images. b) To adapt to real-world data, we finetune MODNet on the unlabeled data by using the consistency between sub-objectives. c) In the application of video human matting, our OFD trick can help smooth the predicted alpha mattes of the video sequence.” from Ke, Z. (2020) [1]
Fortunately for us, this new technique can process human matting from a single input image, without the need for a green screen or a trimap in real-time at up to 63 frames per second! They called their network: MODNet. It’s a light-weight matting objective decomposition network. Which we will further detail. They trained their network in both a supervised and self-supervised way. The supervised way takes an input, and learns to remove the background based on a corresponding ground-truth, just like usual networks. Then, there is the self-supervised training process. This is called self-supervised because this network does not have access to the ground truth of the videos it is trained on. It uses unlabeled data and has access to the information found in the previous step, which are the parameters of the network. It basically takes what the first network learned, and understands the consistency between the object in each frame to correctly remove the background. These two pieces of training are made on the MODNet architecture. MODNet is basically composed of three main branches.
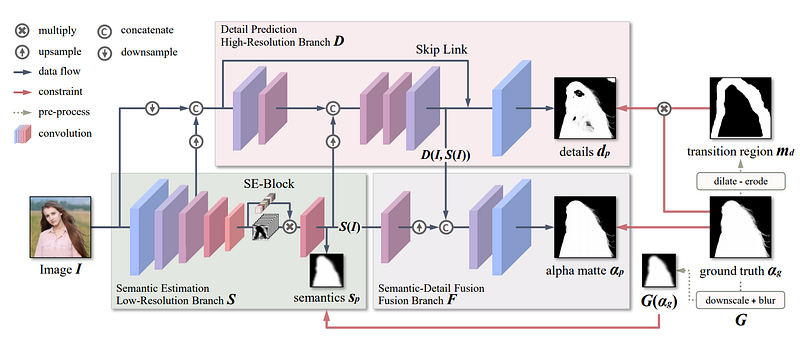
MODNet architecture. Image from Ke, Z. (2020) [1]
There is a low-resolution branch which estimates the human semantics. Then, based on these results, the original image, and the ground truth of the image, a high-resolution branch focuses on detecting precise human boundaries. Finally, a fusion branch, also supervised by the whole ground truth matte is added to predict the final result of the alpha matte, which will be used to remove the background of the input image. This network architecture is way faster because it first finds the semantic estimation itself, using a basic decoder inside the low-resolution branch, making it much faster to process. As you can see, the network is basically mainly composed of downsampling, convolutions, and upsampling. An arbitrary CNN architecture can be used where you see the convolutions happening, in this case, they used MobileNetV2 because it was made for mobile devices. It is a small network and extremely efficient when compared to other state-of-the-art architectures. If you are not familiar with convolutional neural networks, or CNNs, I invite you to watch the video I made explaining what they are.
The downsampling and the use of fewer convolutional layers in the high-resolution branch is done to reduce the computational time. This fusion branch is just a CNN module used to combine the semantics and details, where an upsampling has to be made if we want the accurate details around the semantics. Finally, the results are measured using a loss highly inspired by the Deep Image Matting paper. It calculates the absolute difference between the input image and the composited image obtained, from the ground truth foreground and the ground truth background. Now, there’s one last step to this network’s architecture. If we come back to the full architecture here, we can see that they apply what they called a one-frame delay. Which uses the information of the precedent frame and the following frame to fix the unknown pixels hesitating between foreground and background.
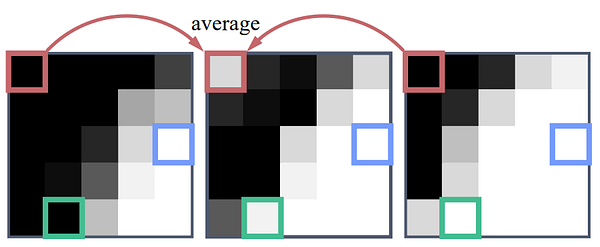
Image from Ke, Z. (2020) [1]
Here, you can see an example where the foreground moves slightly to the left in three consecutive frames and the pixels does not correspond to what it is supposed to, with the red pixel flickering in the second iteration.
Then, you have your final results with the foreground object extracted, which is a person in this case and you can add in many different backgrounds.

Results example using MODNet. Image via MODNet’s GitHub project [2].
Conclusion
Of course, this was just a simple overview of this new paper. I strongly recommend reading the paper [1] for a deeper understanding of this new technique. The code and a pre-trained model will also be available soon on their Github [2], as they wrote on their page. Both are linked in the reference below.
If you like my work and want to support me, I’d greatly appreciate it if you follow me on my social media channels:
- The best way to support me is by following me on Medium.
- Subscribe to my YouTube channel.
- Follow my projects on LinkedIn
- Learn AI together, join our Discord community, share your projects, papers, best courses, find Kaggle teammates, and much more!
References
[1] Ke, Z. et al., Is a Green Screen Really Necessary for Real-Time Human Matting? (2020), https://arxiv.org/pdf/2011.11961.pdf
[2] Ke, Z., GitHub for Is a Green Screen Really Necessary for Real-Time Human Matting? (2020), https://github.com/ZHKKKe/MODNet
[3] Xu, N. et al., Deep Image Matting — Adobe Research (2017), https://sites.google.com/view/deepimagematting
[4] GrabCut algorithm by OpenCV, https://docs.opencv.org/3.4/d8/d83/tutorial_py_grabcut.html
FAQ
What is real-time image matting?
It estimates a soft transparency value for every pixel so a person can be separated from the background live.
Why is matting harder than a hard segmentation mask?
Hair, motion blur, transparent edges, and fine details contain mixtures of foreground and background.
How does GrabCut remove a background?
It iteratively separates foreground and background from an initial user-defined region and optional corrections.
Why were earlier deep-matting methods difficult for video?
Accurate processing could take seconds or minutes per frame, making continuous video too slow.
What does MODNet improve?
MODNet targets fast, single-image human matting without requiring a green screen or manually prepared trimap.