

Watch the video and support me on YouTube:
I’m sure you’ve all clicked on a video thumbnail from the slow mo guys to see the water floating in the air when popping a water balloon or any other super cool-looking “slow-mos” made with extremely expensive cameras. Now, we are lucky enough to be able to do something not really comparable but still quite cool with our phones. What if you could reach the same quality without such an expensive setup?
Well, that’s exactly what Time Lens, a new model published by Tulyakov et al. can do with extreme precision. Just look at that! It generated these slow-motion videos of over 900 frames per second out of videos of only 50 FPS! This is possible by guessing what the frames in-between the real frames could look like, and it is an incredibly challenging task. Instead of attacking it with the classical idea of using the optical flow of the videos to guess the movement of the particles in the video, they used a simple setup with two cameras, and one of them is very particular.

Slow-motion example. Image from Tulyakov et al., TimeLens, (2021)
The first camera is the basic camera recording the RGB frames as you know them. The second one, on the other hand, is an event camera. This kind of camera uses novel sensors that only report the pixel intensity changes instead of the current pixel intensities, which a regular camera does, and it looks just like this. This camera provides information in-between the regular frames due to the compressed representation of the information they report compared to regular images. This is because the camera reports only information regarding the pixels that changed and in a lower resolution, making it much easier to record at a higher rate making it a high temporal resolution camera but low-definition. You can see this as sacrificing the quality of the images it captures in exchange for “more images.” Fortunately, this lack of image quality is fixed by using the other frame-based camera, which we will see in a few seconds.

Frame and events displayed. Image from Tulyakov et al., TimeLens, (2021)
Time Lens leverages these two types of cameras, the frame, and the event cameras, using machine learning to maximize these two cameras’ types of information and better reconstruct what actually happened between those frames. Something that even our eyes cannot see. In fact, it achieves results that our intelligent phones and no other models could reach before.

Slow-motion example 2. Image from Tulyakov et al., TimeLens, (2021)
Here’s how they achieved that… As you know, we start with the typical frame which comes from the regular camera with something between 20 and 60 frames per second. This cannot do much as you need much more frames in a second to achieve a slow-motion effect like this one. More precisely, to look interesting, you need at least 300 frames per second, which means that we have 300 images for only one second of video footage. But how can we go from 20 or so frames to 300? We cannot create the missing frame. This is just too little information to interpolate from. Well, we use the event-based camera, which contains much more time-wise information than the frames.
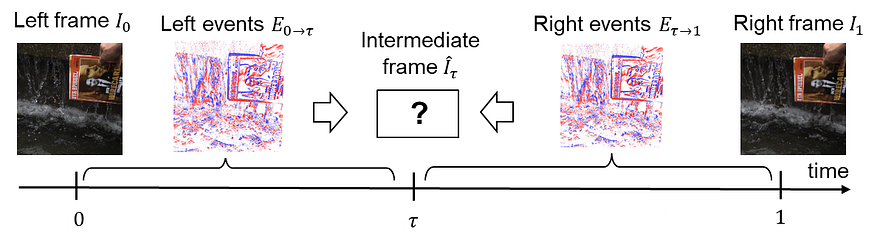
The missing frames to create slow-motion effects. Image from Tulyakov et al., TimeLens, (2021)
As you can see here, it basically contains incomplete frames in-between the real frames, but they are just informative enough to help us understand the movement of the particles and still grasp the overall image using the real frames around them.
The events and frame information are both sent into two modules to train and interpolate the in-between frames: the warping-based interpolation and the interpolation by synthesis modules.
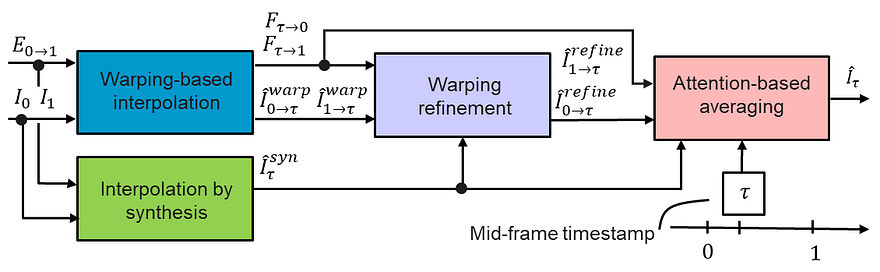
The overall architecture. Image from Tulyakov et al., TimeLens, (2021)
This first warping module is the main tool to estimate the motion from events instead of the frames like the synthesis module does. It takes the frames and events and translates them into optical flow representation using a classic U-net-shaped network. This network simply takes images as inputs, encodes them, and then decodes them into a new representation. This is possible because the model is trained to achieve this task on huge datasets. As you may know, I already covered similar architectures numerous times on my channel, which you can find with various applications for more details.

In short, you can see it as an image-to-image translation tool that just changes the style of the image, which in this case takes the events and frames, and find an optimal optic flow representation for it to create a new frame for each event. It basically translates an event image into a real frame by trying to understand what’s happening in the image with the optical flow.
If you are not familiar with optical flow, I’d strongly recommend watching my video covering a great paper about it that was published at the same conference a year ago.
The interpolation by synthesis module is quite straightforward. It is used because it can handle new objects appearing between frames and changes in lighting like the water reflection shown here. This is due to the fact that it uses a similar U-net-shaped network to understand the frames with the events to generate a new fictional frame. In this case, the U-net takes the events in-between two frames and generates a new possible frame for each event directly instead of going through the optical flow.
The main drawback here is that noise may appear due to the lack of information regarding the movement in the image, which is where the other module helps. Then, the first module is refined using even more information from the interpolation synthesis I just covered. It basically extracts the most valuable information about these two generated frames of the same event to refine the warped representation and generate a third version of each event using a U-net network again.
Finally, these three frame candidates are sent into an attention-based averaging module. This last module simply takes these three newly generated frames and combines them into a final frame, which will take only the best parts of all three possible representations, which is also learned by training the network to achieve that. If you are not familiar with the concept of attention, I’d strongly recommend watching the video I made covering how it works with images.
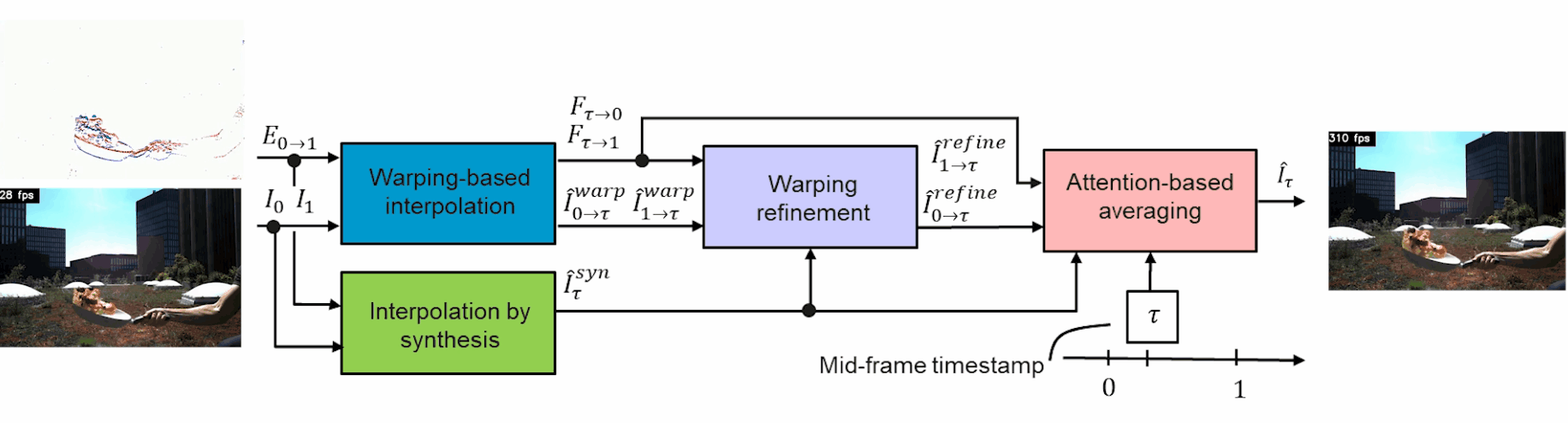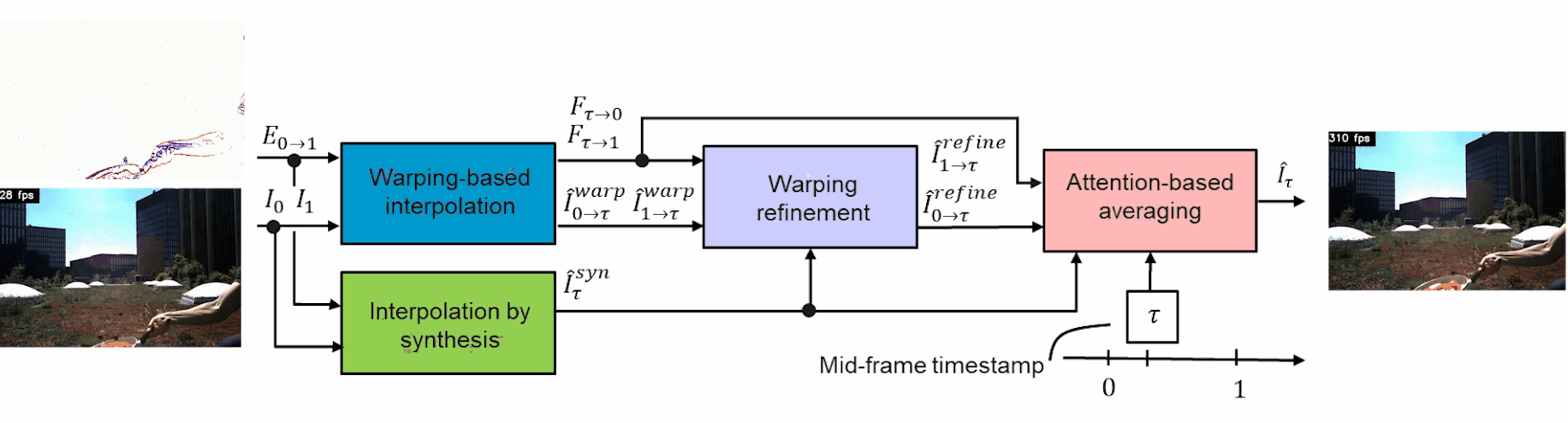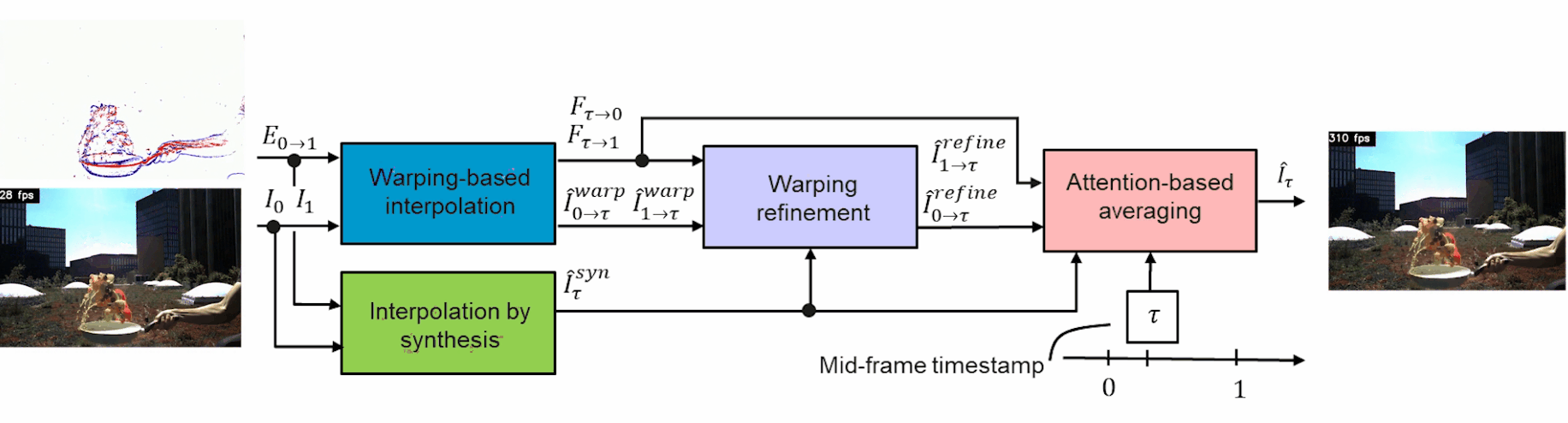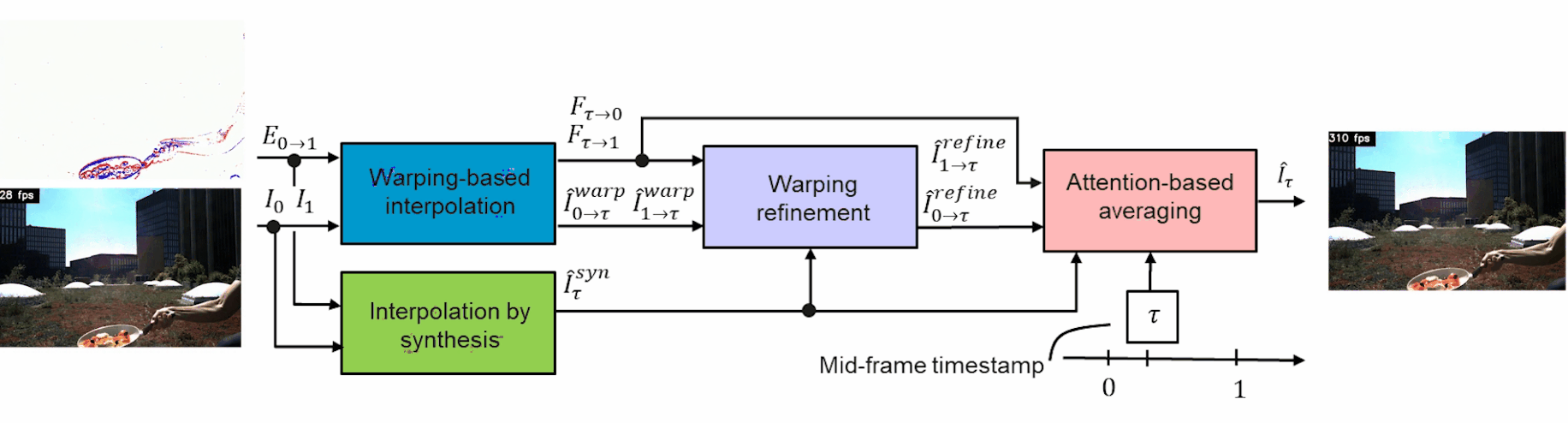
The overall architecture with inputs/output. Image from Tulyakov et al., TimeLens, (2021)
You now have a high-definition frame for the first event in-between your frames and just need to repeat this process for all the events given by your event camera. And voilà! This is how you can create amazing-looking and realistic slow-motion videos using artificial intelligence.
As always, if you are curious about this model, the link to the code and paper are in the description below.
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References:
►Read the full article: /timelens
►Official code: https://github.com/uzh-rpg/rpg_timelens
►Reference: Stepan Tulyakov*, Daniel Gehrig*, Stamatios Georgoulis, Julius Erbach, Mathias Gehrig, Yuanyou Li, Davide Scaramuzza, TimeLens: Event-based Video Frame Interpolation, IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, 2021, https://rpg.ifi.uzh.ch/docs/CVPR21_Gehrig.pdf
FAQ
What does TimeLens do?
TimeLens reconstructs intermediate video frames by combining ordinary frames with high-temporal-resolution event-camera data.
What is an event camera?
It records changes in brightness asynchronously, capturing fast motion without producing conventional full frames.
Why combine frame and event cameras?
Frames provide detailed appearance, while events provide precise motion timing between those frames.
How does this create slow motion?
The model estimates missing moments so playback can contain many more frames for each second of recorded action.
What can go wrong in generated slow motion?
Occlusion, rapid lighting changes, sparse events, and ambiguous motion can produce warped or invented intermediate details.