
Watch the video!
How do autonomous vehicles see?

A self-driving car. Image by the author.
You’ve probably heard of LiDAR sensors or other weird cameras they are using. But how do they work, how can they see the world, and what do they see exactly compared to us? Understanding how they work is essential if we want to put them on the road, primarily if you work in the government or build the next regulations. But also as a client of these services.
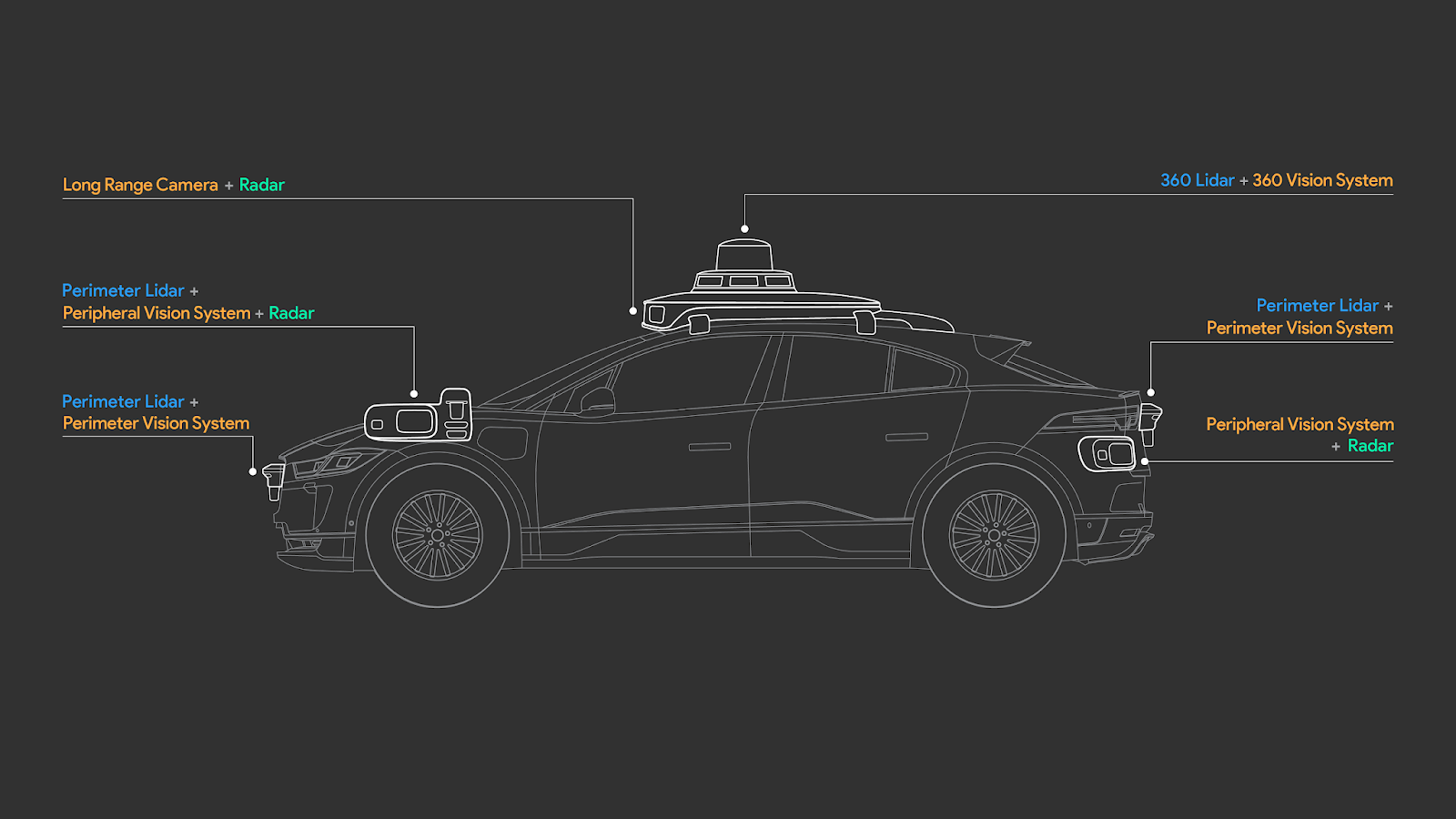
We previously covered how Tesla autopilot sees and works, but they are different from conventional autonomous vehicles. Tesla only uses cameras to understand the world, while most of them, like Waymo, use regular cameras and 3D LiDAR sensors. These LiDAR sensors are pretty simple to understand: they won’t produce images like regular cameras but 3D point clouds. LiDAR cameras measure the distance between objects, calculating the pulse laser’s traveling time that they project to the object.
”LiDAR sensor enables 3D detection of distances”, Electronic Specifier
This way, they will produce very few data points with valuable and exact distance information, as you can see here. These data points are called point clouds, and it just means that what we will see are just many points at the right positions, creating some sort of 3D model of the world.

”LiDAR sensor enables 3D detection of distances”, Electronic Specifier
Here you can see how LiDAR, on the right, isn’t that precise to understand what it sees, but it is pretty good to understand depth with very little information, which is perfect for efficiently computing the data in real-time. An essential criterion for autonomous vehicles.
This minimal amount of data and high spatial precision is perfect because coupled with RGB images, as shown on the left, we have both accurate distance information and the accurate object information we lack with LiDAR data alone, especially from far away objects or people. This is why Waymo and other autonomous vehicle companies use both kinds of sensors to understand the world.
Still, how can we efficiently combine this information and have the vehicle understand it? And what does the vehicle end up seeing? Only points everywhere? Is it enough for driving on our roads? We will look into this with a new research paper by Waymo and Google Research [1].
I think I couldn’t summarize the paper better than the sentence they used in their article;
“We present 4D-Net, which learns how to combine 3D point clouds in time and RGB camera images in time, for the widespread application of 3D object detection in autonomous driving.” [1]
I hope you enjoyed the article. Please let me know if you enjoyed the read and… I’m just kidding! Let’s dive a little deeper into this sentence.
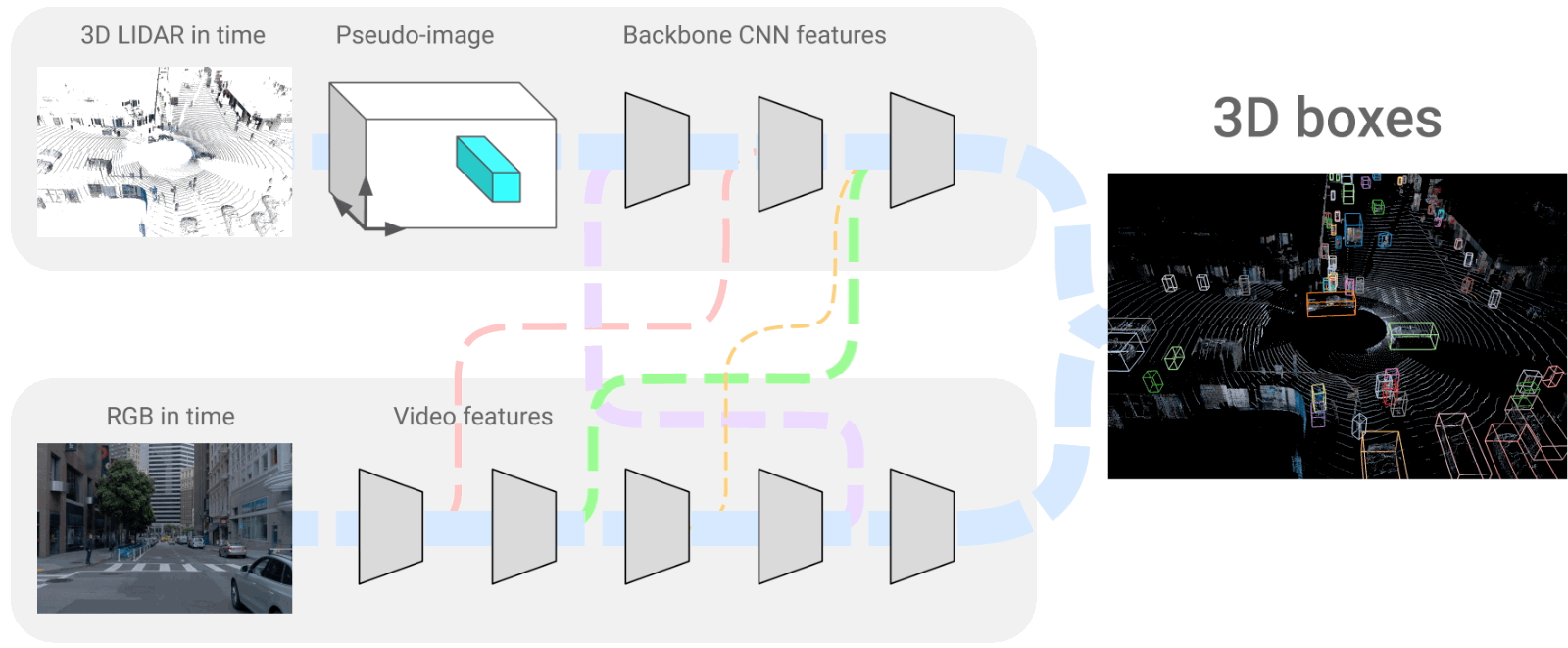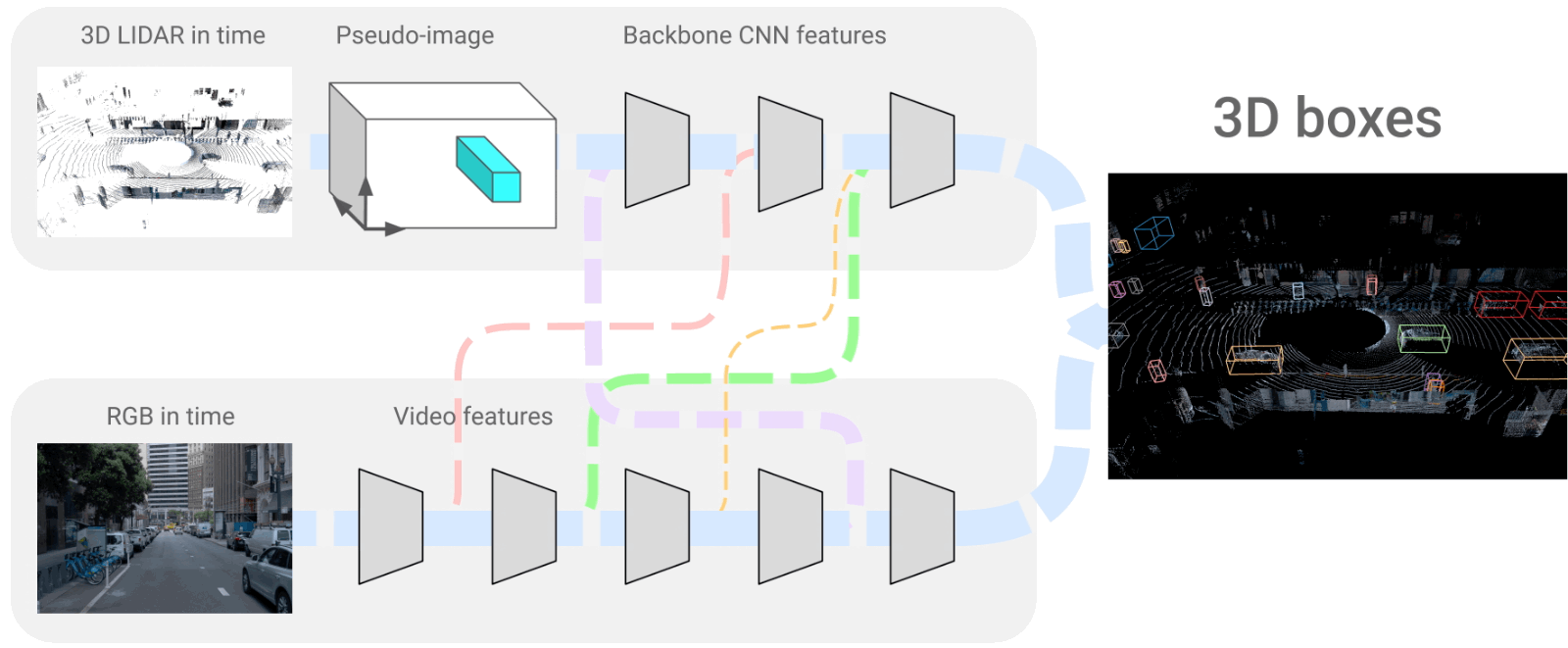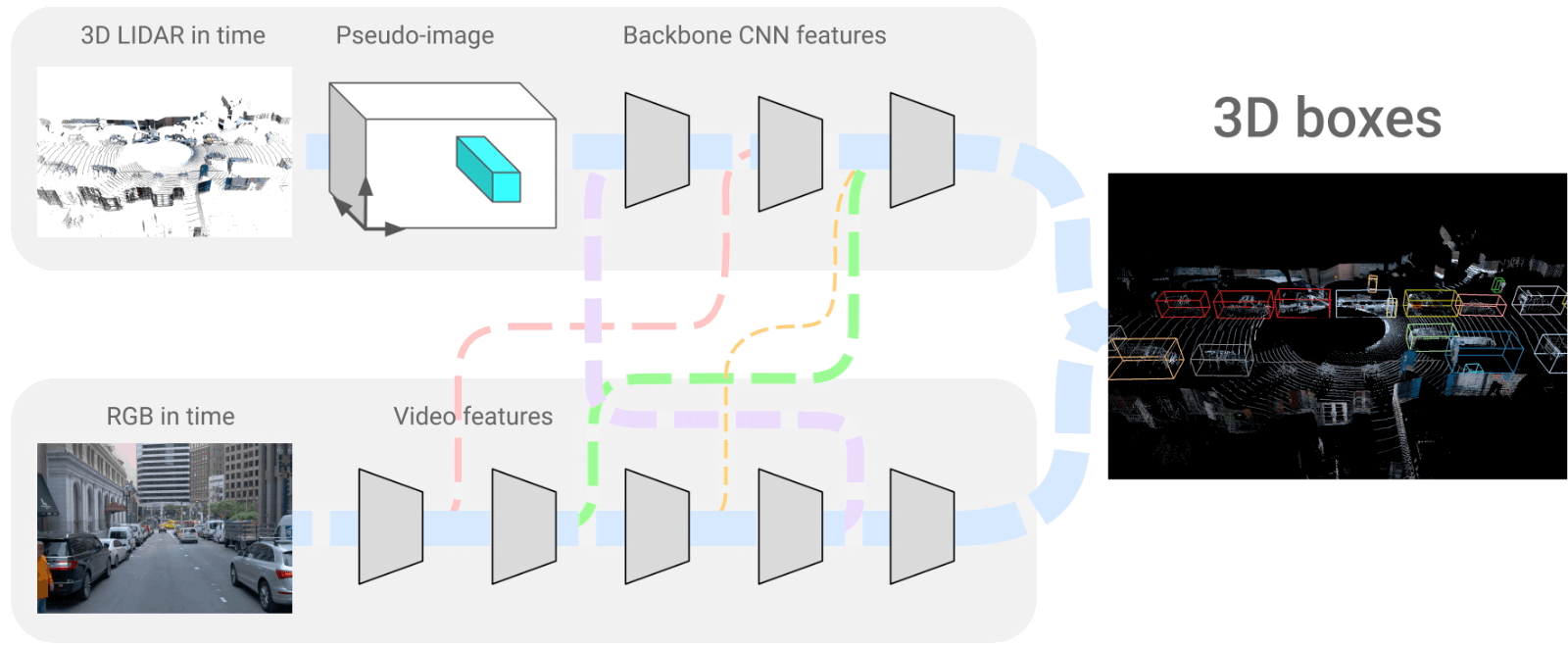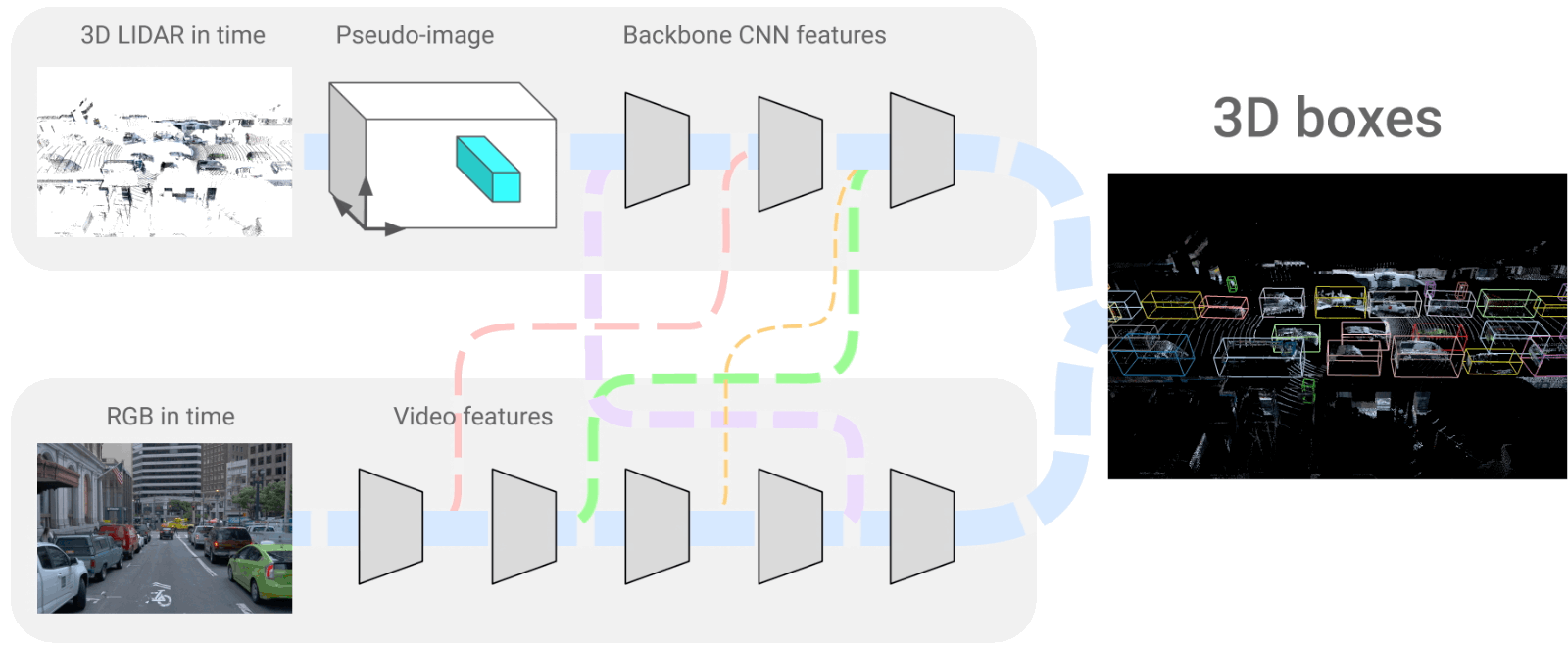
The 4D-Net architecture where we merge LiDAR and RGB frames. Image from the paper [1].
This is what the 3D object detection we are talking about looks like. And it is also what the car will end up seeing. It is a very accurate representation of the world around the vehicle with all objects appearing and precisely identified.
How cool does that look? And more interesting, how did they end up with this result?
They produced this view using LiDAR data, called point clouds in time (PCiT), and regular cameras, or here called RGB videos. These are both 4-dimensional inputs, just like we, humans, see and understand the world. The four dimensions come from the videos being taken in time, so the vehicle has access to past frames to help understand context and objects to guess future behaviors just like we do, creating the fourth dimension. The three others are the 3D space we are familiar with.

Scene understanding. Image by the author.
We call this task scene understanding, and it has been widely studied in computer vision and has seen many advancements with the recent progress of the field and machine learning algorithms. It is also crucial in self-driving vehicles, where we want to have a near-perfect comprehension of the scenes.
If we come back to the network we saw above, you can see that the two networks always “talk” to each other with connections. This is mainly because when we take images, we have objects at various ranges in the shot and with different proportions.

Cars at different scales. Image by the author.
The car in front of you will look much bigger than the car far away, but you still need to consider both.
Like us, when we see someone far away and feel like it is our friend but wait to get closer to be sure before shouting his name, the car will lack details for such faraway objects.

Image by the author.
Filter example in a convolutional neural network for early and deep layers. Image by the author.
Meaning that early layers will be able to detect small objects and only edges or parts of the bigger objects. Deeper layers will lose the small objects but be able to detect large objects with great precision.
The main challenge with this approach is combining these two very different kinds of information through these connections; the LiDAR 3D space data and more regular RGB frames. Using both information at all network steps, as described earlier, is best to understand the whole scene better.
But how can we merge two different streams of information and use the time dimension efficiently? This data translation between the two branches is what the network learns during training in a supervised way with a similar process as in the self-attention mechanisms I covered in previous articles by trying to re-create the real model of the world. But to facilitate this data translation, they use a model called PointPillars, which takes point clouds and gives a 2-dimensional representation.
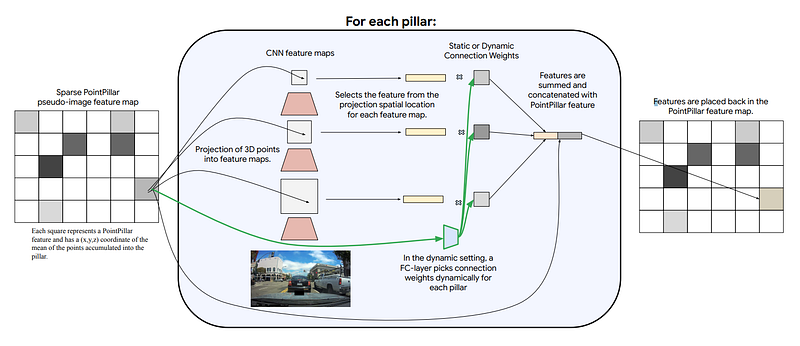
PointPillars. Image from the paper [1].
You can see this as a pseudo image of the point cloud, as they call it, creating somewhat of a regular image representing the point cloud with the same properties as the RGB images we have in the other branch. Instead of the pixels being red-green-blue colors, they simply represent the depth and positions of the object (x,y,z) coordinates. This pseudo image is also really sparse, meaning that the information on this representation is only dense around important objects and most probably useful for the model. Regarding time, we simply have the fourth dimension in the input image to keep track of the frames.
The 4D-Net architecture where we merge LiDAR and RGB frames. Image from the paper [1].
These two branches we see are convolutional neural networks that encode the images, as described in multiple of my articles, and then decode this encoded information to recreate the 3D representation we have here. So it uses a very similar encoder for both branches, shares information with each other, and reconstructs a 3D model of the world using a decoder.
And Voilà! This is how the Waymo vehicles see our world, through these 3D models of the world we see on the right of the above image. It can process 32 point clouds in time and 16 RGB frames within 164 milliseconds, producing better results than other methods. This might not ring any bell, so we can compare it with the next best approach that is less accurate and takes 300 milliseconds, almost double the time to process.
Of course, this was an overview of this new paper by Google Research and Waymo. I’d recommend reading the paper linked below to learn more about their model’s architecture and other features I didn’t dive into, like time information’s efficiency problem.
I hope you enjoyed the article, and if you did, please consider supporting my work on YouTube by subscribing to the channel and commenting on what you think of this summary. I’d love to read what you think!
Thank you for reading, and I will see you next week with another amazing paper explained!
References
- The video: https://youtu.be/0nJMnw1Ldks
- Piergiovanni, A.J., Casser, V., Ryoo, M.S. and Angelova, A., 2021. 4d-net for learned multi-modal alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 15435–15445).
- Google Research’s blog post: https://ai.googleblog.com/2022/02/4d-net-learning-multi-modal-alignment.html?m=1