
The short version
Swin Transformer applied self-attention to image patches within local windows, then shifted the windows to connect neighboring regions without the full cost of global attention. The 2021 article presents this hierarchy as an efficient computer-vision backbone and reports gains over contemporary CNNs. Those comparisons are historical, and the post also notes that very long-range relations remained limited.
- Vision transformers changed computer vision by applying attention to image patches, but that does not make CNNs obsolete overnight.
- Transformers can work extremely well with enough data and compute, while CNNs can still be efficient and strong for many practical tasks.
- The right choice depends on dataset size, latency, hardware, robustness, maintainability, and what the product needs to measure.
Watch the video and support me on YouTube!
This article is about most probably the next generation of neural networks for all computer vision applications: The transformer architecture. You’ve certainly already heard about this architecture in the field of natural language processing, or NLP, mainly with GPT3 that made a lot of noise in 2020. Transformers can be used as a general-purpose backbone for many different applications and not only NLP. In a couple of minutes, you will know how the transformer architecture can be applied to computer vision with a new paper called the Swin Transformer by Ze Lio et al. from Microsoft Research [1].
This article may be less flashy than usual as it doesn’t really show the actual results of a precise application. Instead, the researchers [1] showed how to adapt the transformers architecture from text inputs to images, surpassing computer vision state-of-the-art convolutional neural networks, which is much more exciting than a slight accuracy improvement, in my opinion. And of course, they are providing the code [2] for you to implement yourself! The link is in the references below.
Why use transformers over CNNs?
But why are we trying to replace convolutional neural networks (CNNs) for computer vision applications? This is because transformers can efficiently use a lot more memory and are much more powerful when it comes to complex tasks. This is, of course, according to the fact that you have the data to train it. Transformers also use the attention mechanism introduced with the 2017 paper Attention is all you need [3]. Attention allows the transformer architecture to compute in a parallelized manner.

Self-attention process in NLP. Image by Davide Coccomini reposted with permission.
It can simultaneously extract all the information we need from the input and its inter-relation, compared to CNNs. CNNs are much more localized, using small filters to compress the information towards a general answer.
While this architecture is powerful for general classification tasks, it does not have the spatial information necessary for many tasks like instance recognition. This is because convolutions don’t consider distanced-pixels relations.


Self-attention example in Transformers for NLP (left) and computer vision (right). Image by the author.
In NLP, a classical type of input is a sentence and an image in a computer vision case. To quickly introduce the concept of attention, let’s take a simple NLP example sending a sentence to translate it into a transformer network. In this case, attention is basically measuring how each word in the input sentence is associated with each word on the output translated sentence. Similarly, there is also what we call self-attention that could be seen as a measurement of a specific word’s effect on all other words of the same sentence. This same process can be applied to images calculating the attention of patches of the images and their relations to each other, as we will discuss further in the article.
Transformers in computer vision
Now that we know transformers are very interesting, there is still a problem in computer vision applications. Indeed, just like the popular saying “a picture is worth a thousand words,” pictures contain much more information than sentences, so we have to adapt the basic transformer’s architecture to process images effectively. This is what this paper is all about.

Vision transformers’ complexity. Image by Davide Coccomini reposted with permission.
This is due to the fact that the computational complexity of its self-attention is quadratic to image size. Thus exploding the computation time and memory needs. Instead, the researchers replaced this quadratic computational complexity with a linear computational complexity to image size.

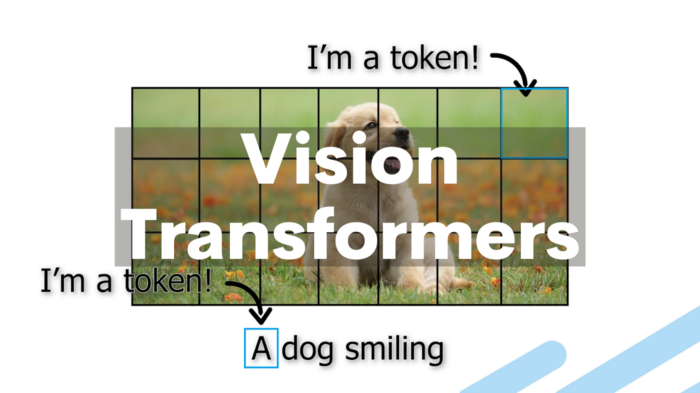
The first step of the Swin Transformer architecture, image tokenization. Image by the author.
The Swin Transformer [1] [2]
The process to achieve this is quite simple. At first, like most computer vision tasks, an RGB image is sent to the network. This image is split into patches, and each patch is treated as a token. And these tokens’ features are the RGB values of the pixels themselves. To compare with NLP, you can see this as the overall image is the sentence, and each patch is the words of that sentence. Self-attention is applied on each patch, here referred to as windows. Then, the windows are shifted, resulting in a new window configuration to apply self-attention again. This allows the creation of connections between windows while maintaining the computation efficiency of this windowed architecture. This is very interesting when compared with convolutional neural networks as it allows long-range pixel relations to appear.
Self-attention applied on windows. Image by the author.
This was only for the first stage. The second stage is very similar but concatenates the features of each group of two by two neighboring patches, downsampling the resolution by a factor of two. This procedure is repeated twice in Stages 3 and 4 producing the same feature map resolutions like those of typical convolutional networks like ResNets and VGG.
You may say that this is highly similar to a convolutional architecture and filters using dot products. Well, yes and no.
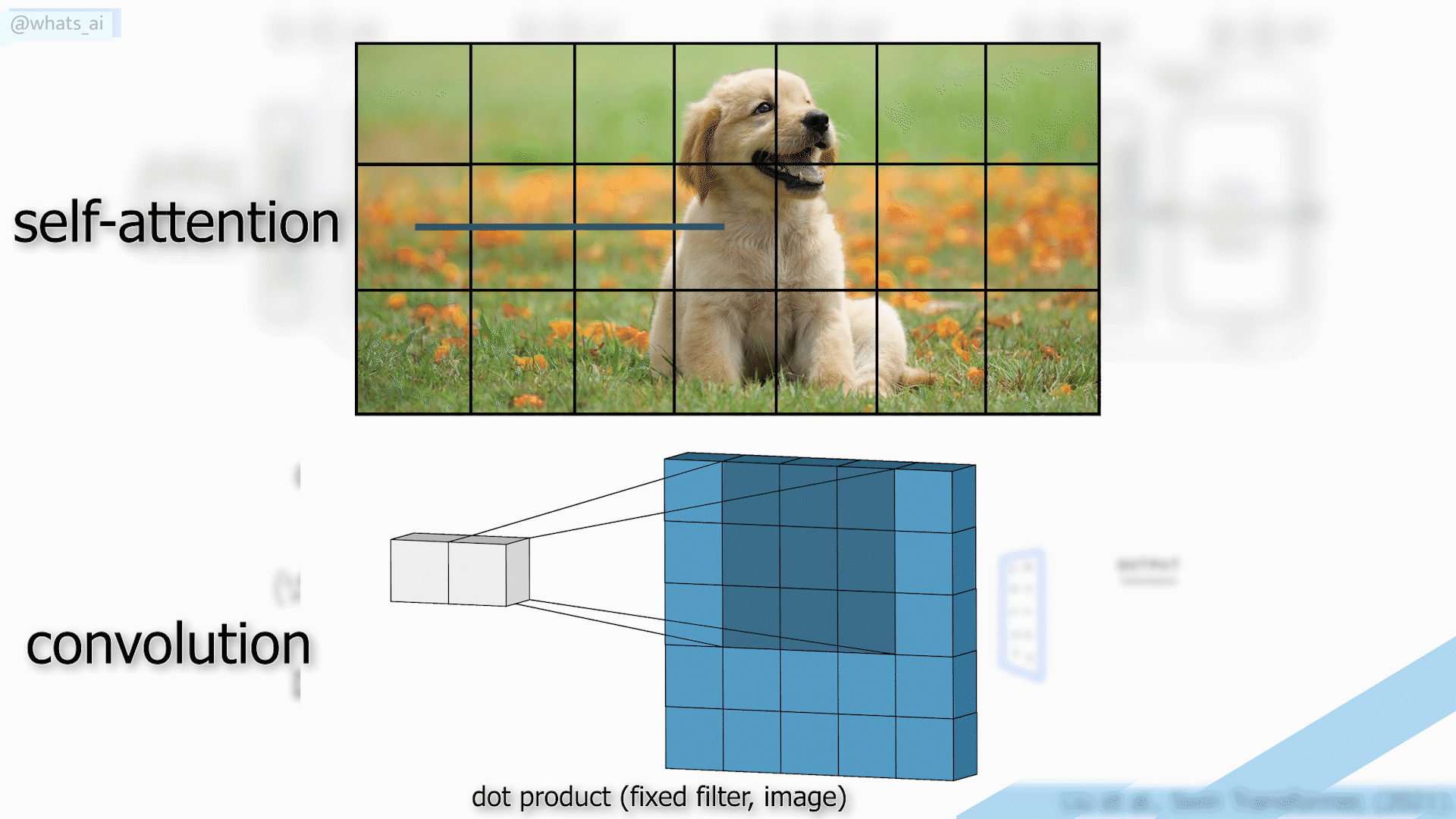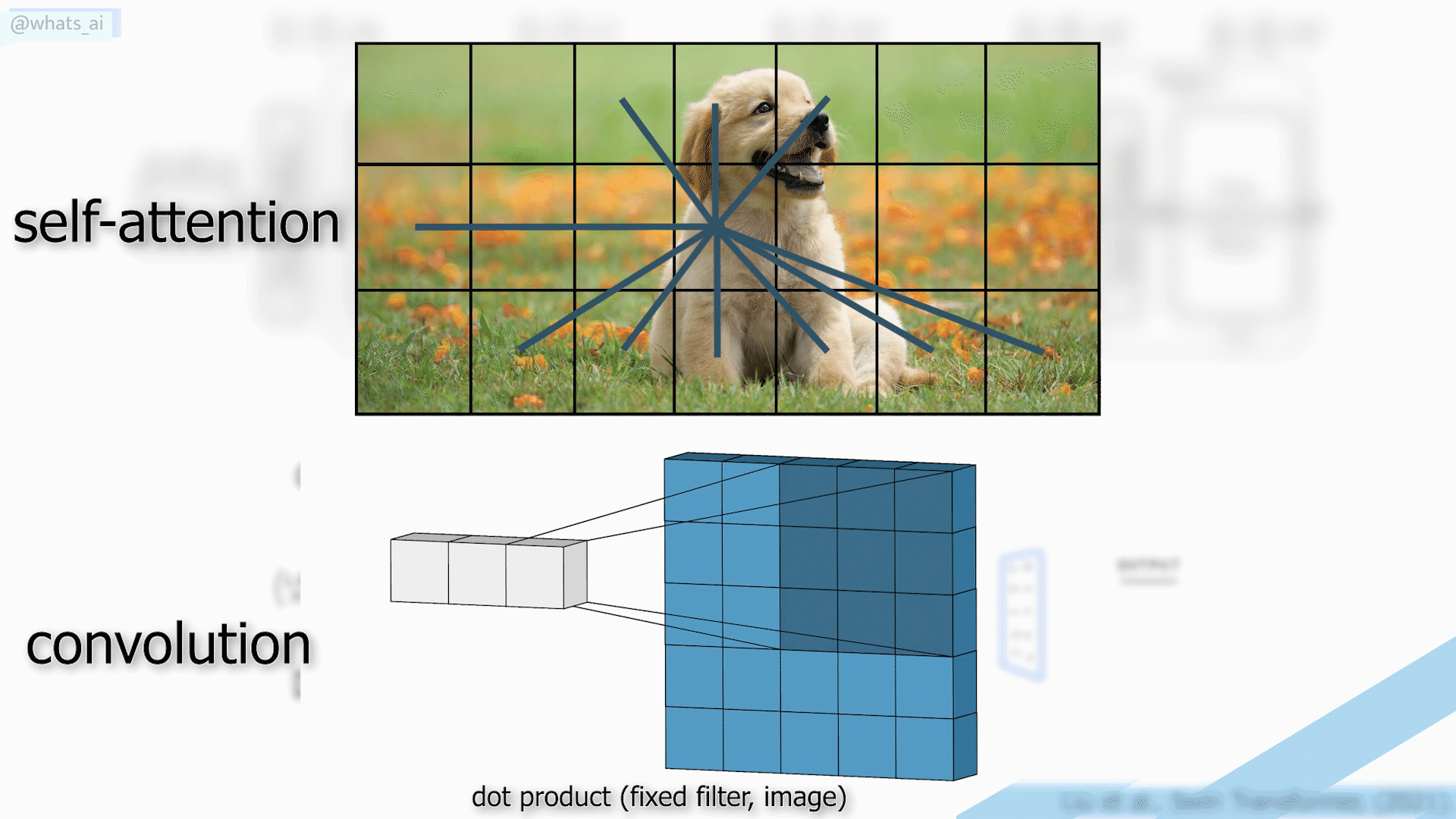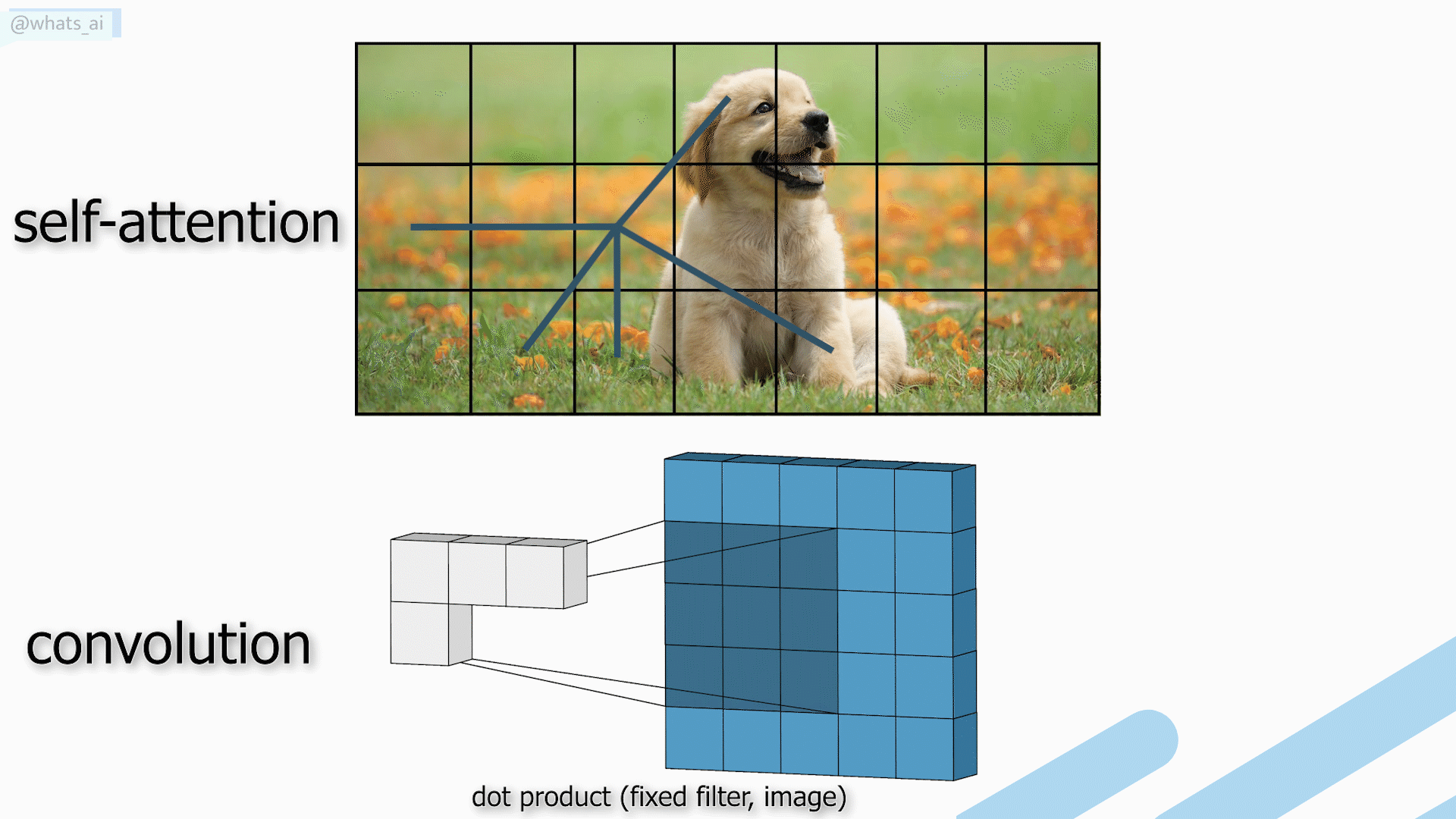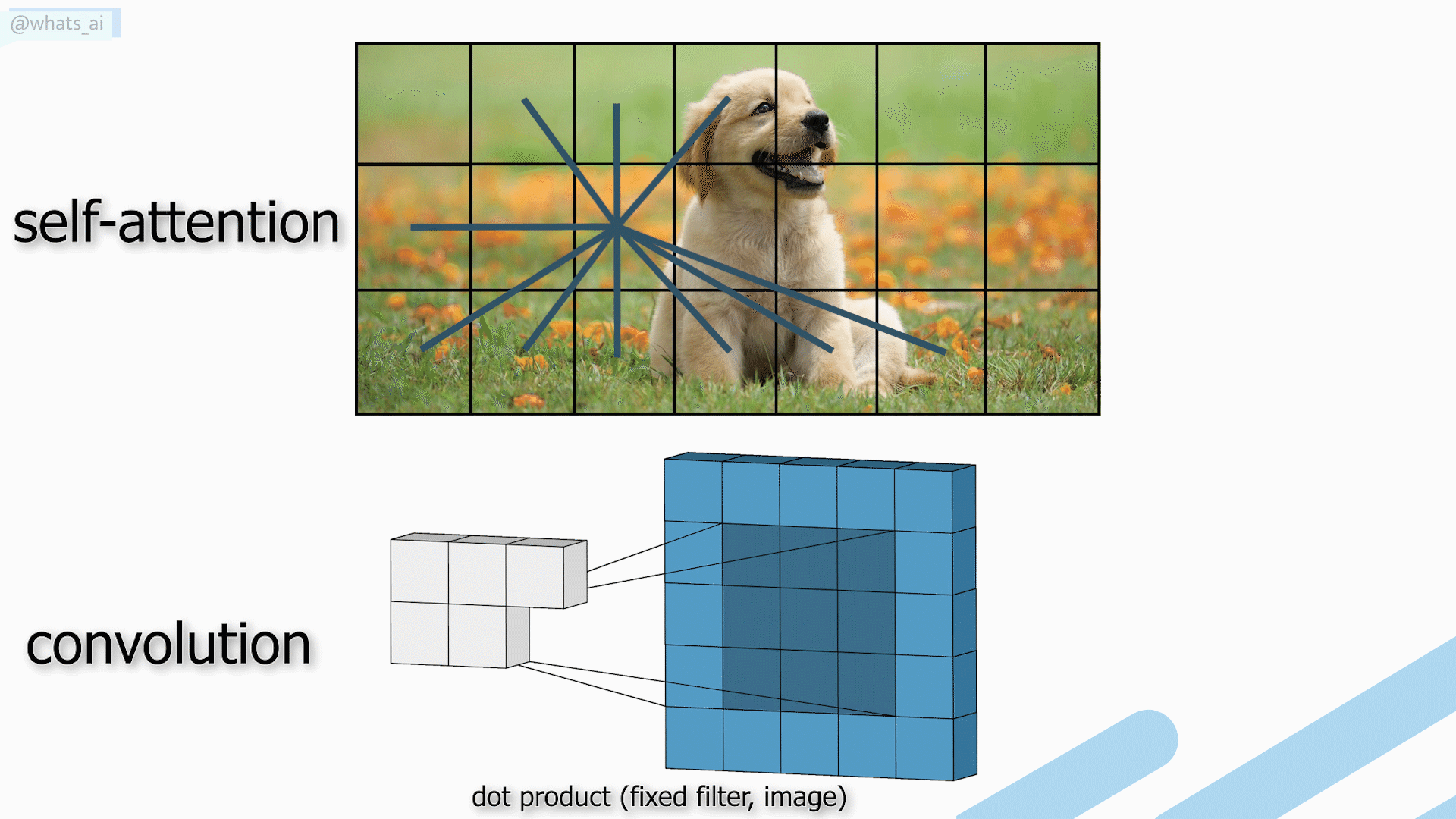
The power of convolutions is that the filters use fixed weights globally, enabling the translation-invariance property of convolution, making it a powerful generalized. In self-attention, the weights are not fixed globally. Instead, they rely on the local context itself. Thus, self-attention takes into account each pixel, but also its relation to the other pixels.
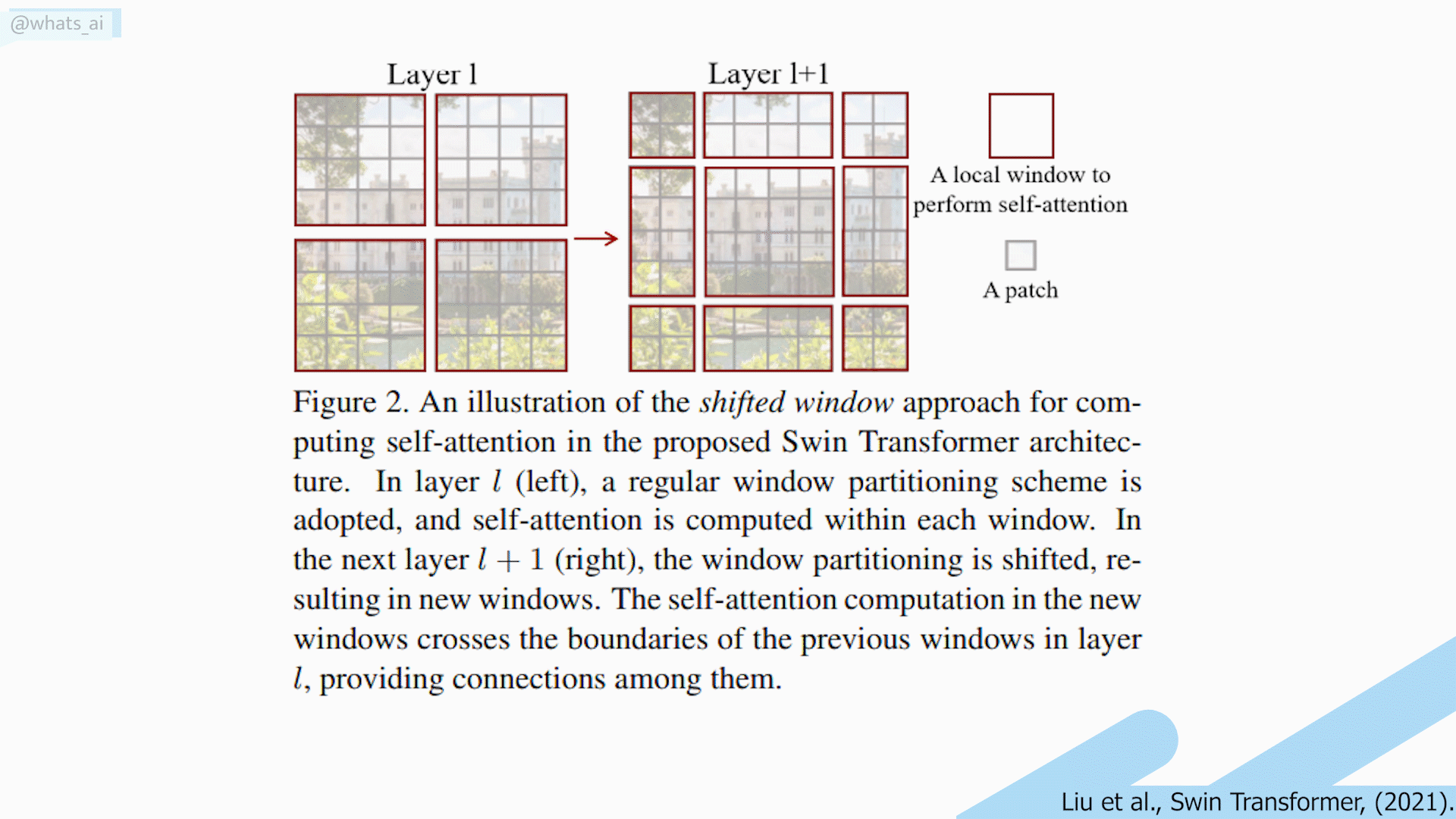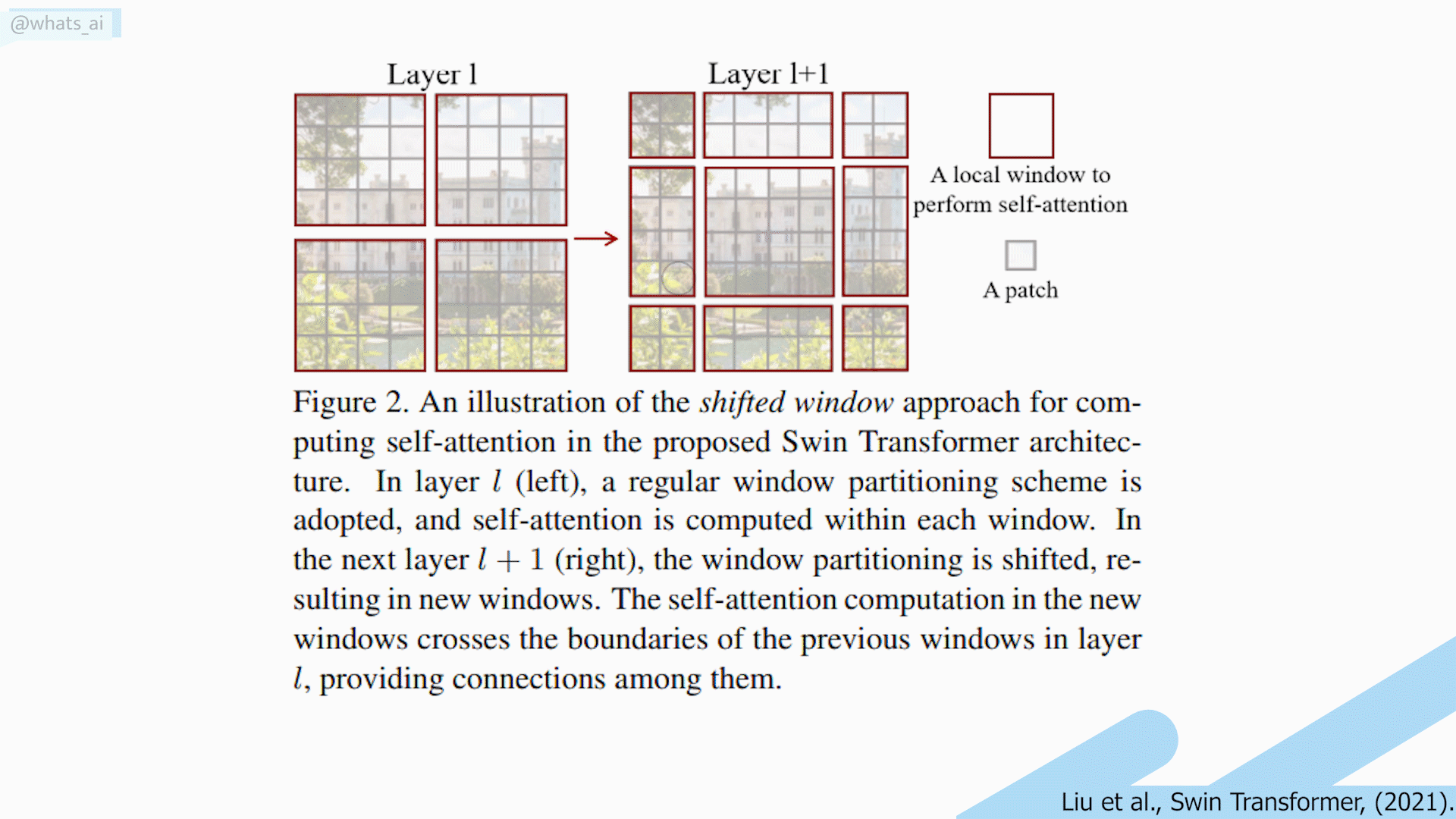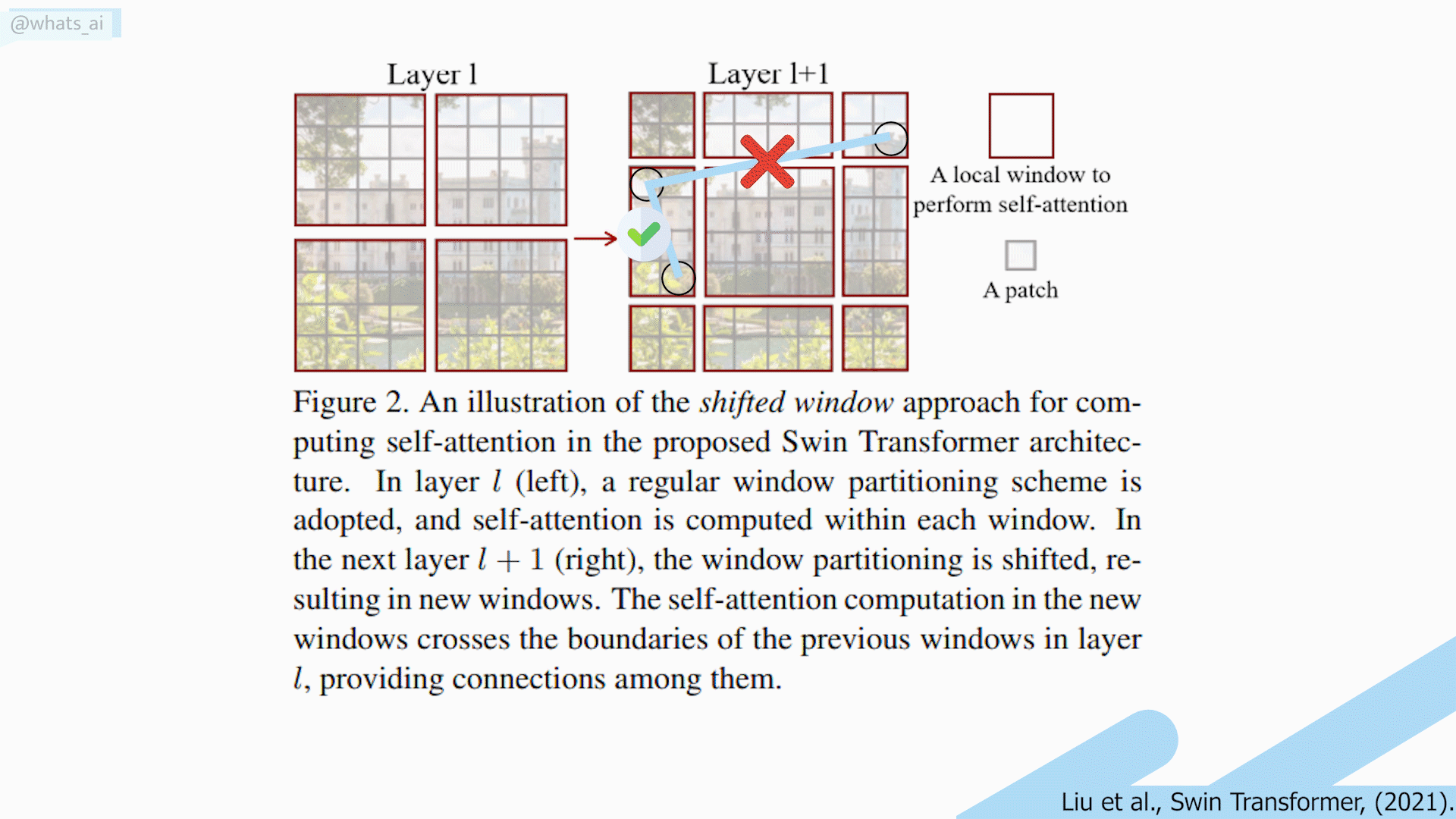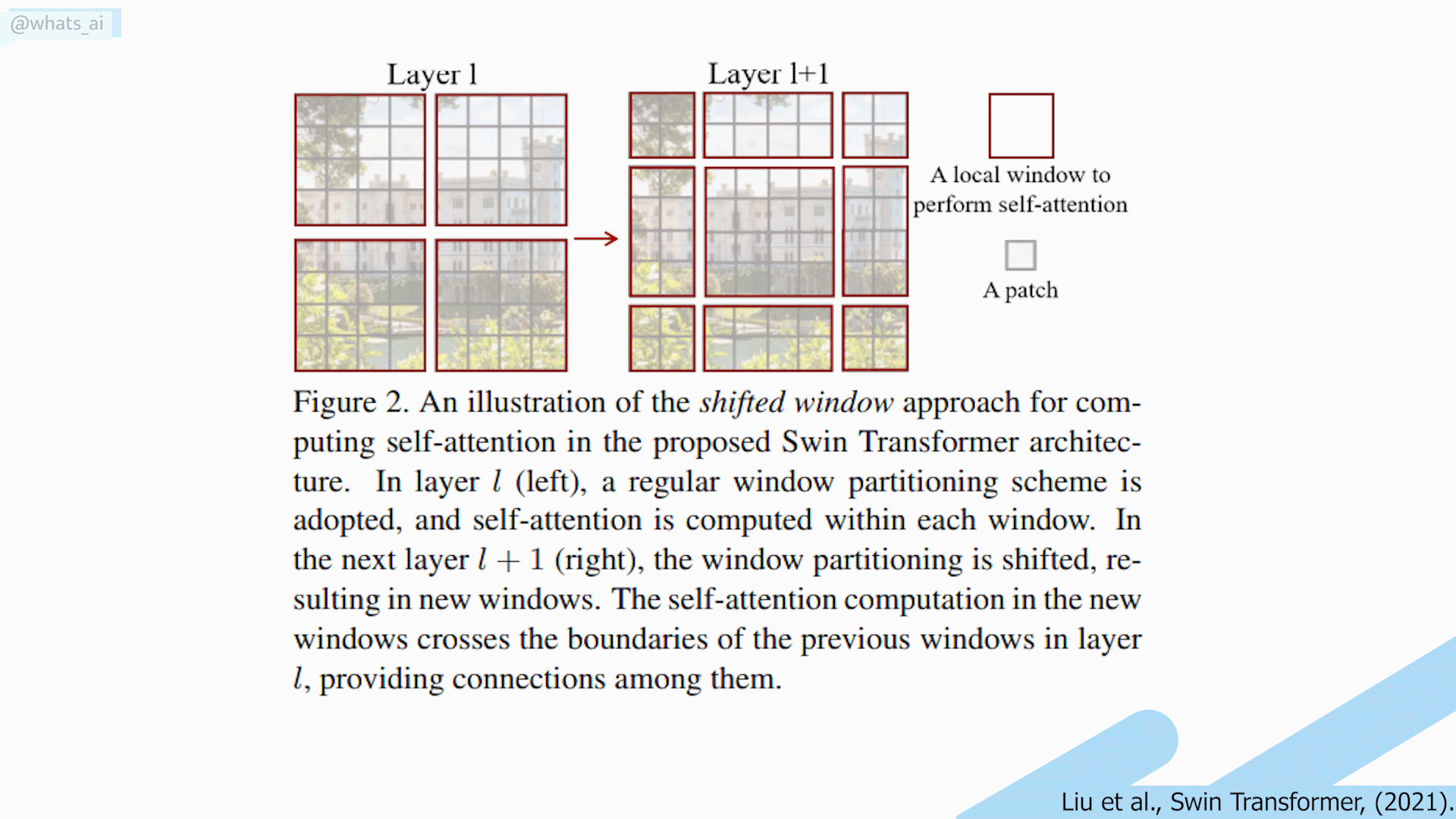
Shifting window long-range relation problem. Image by the author.
Also, their shifted window technique allows long-range pixel relations to appear. Unfortunately, these long-range relations only appear with neighboring windows. Thus, losing very long-range relations, showing that there is still a place for improvement of the transformer architecture when it comes to computer vision.

Conclusion
As they state in the paper:
It is our belief that a unified architecture across computer vision and natural language processing could benefit both fields, since it would facilitate joint modeling of visual and textual signals and the modeling knowledge from both domains can be more deeply shared. [1] p.2
And I completely agree. I think using a similar architecture for both NLP and computer vision could significantly accelerate the research process. Of course, transformers are still highly data-dependent, and nobody can say whether or not it will be the future of either NLP or computer vision. Still, it is undoubtedly a significant step forward for both fields!
I hope this article could give you a great introduction to transformers and how they can be applied to computer vision applications.
Thank you for reading!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by following me here on Medium or subscribe to my channel on YouTube if you like the video format.
- Support my work on Patreon
- Join our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
References
[1] Liu, Z. et al., 2021, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows”, arXiv preprint https://arxiv.org/abs/2103.14030v1
[2] Swin Transformer, Lio, Z. et al, GitHub code, https://github.com/microsoft/Swin-Transformer
[3] Vaswani, A. et al., 2017. “Attention is all you need”, arXiv preprint https://arxiv.org/abs/1706.03762.
FAQ
What is a vision transformer?
A vision transformer applies the transformer architecture to images, often by splitting an image into patches and using attention across them.
Will transformers replace CNNs in computer vision?
Transformers are important and often very strong, but CNNs remain useful for many tasks where data, compute, latency, or simplicity matter.
Why did transformers become popular for vision?
They can model long-range relationships in an image and scale well with large datasets and compute, especially in modern multimodal systems.
When is a CNN still a good choice?
A CNN can be a good choice when the dataset is smaller, the deployment target is constrained, or the task benefits from efficient local features.
How should builders choose between CNNs and transformers?
Compare them on your data, latency budget, accuracy target, hardware, failure cases, and how easy the model is to deploy and maintain.