

The short version
Explainable AI helps inspect which parts of an input influenced a model’s prediction. In the post’s image-classification example, a saliency map reveals that water pixels, not the shark itself, drove a confident label. That clue exposes a shortcut: masking the irrelevant region changes the label to the correct species. The practical point is to examine predictions qualitatively as well as measure aggregate accuracy before deployment.
Watch the complete videos with an applied example shown!
Powerful artificial intelligence models like DALLE or ChatGPT are super useful and fun to use. But what happens when they are wrong?
What if they lie to you without even knowing they are lying? Often called hallucinations, these problems can be harmful, especially if we blindly trust the AI. We should be able to trace back and explain how those AI models make decisions and generate results.
To illustrate this, let’s look at a very simple example. You are a research scientist aiming to build a model able to classify images, which means identifying what is the main object in the image. You gather a couple of images of different objects and train an algorithm to understand what makes a cat, a cat, a dog, a dog and etc… You now expect your model to be able to identify those objects from any picture and publish it on your website for anyone to use.
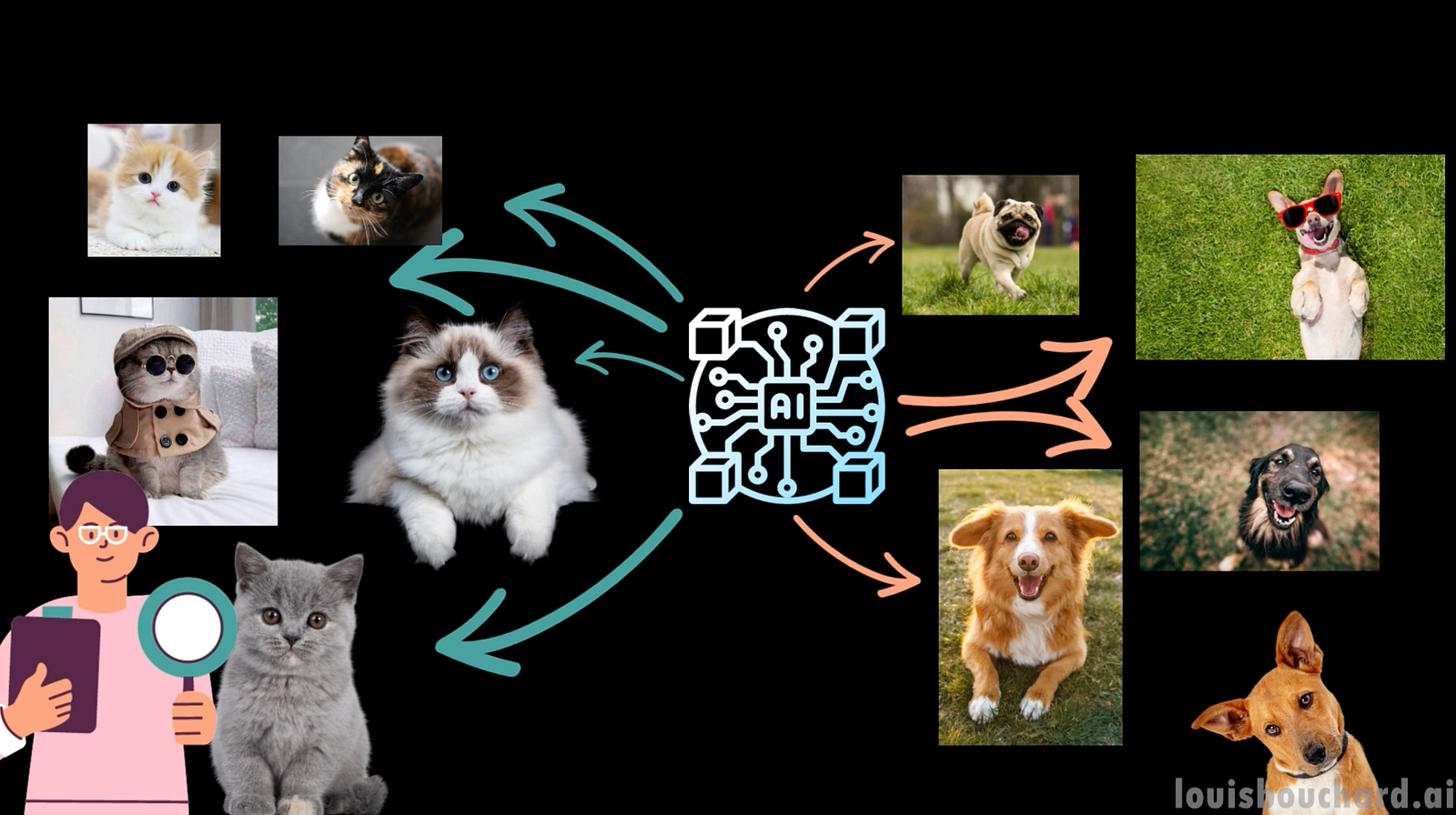
Before doing so, you test it to make sure it performs well. Here, we see the model is pretty accurate. It actually found that they were images of animals, and, more precisely, it even found it was a cat, a dog, and a shark. Cool! Time to push it online and your job is done!
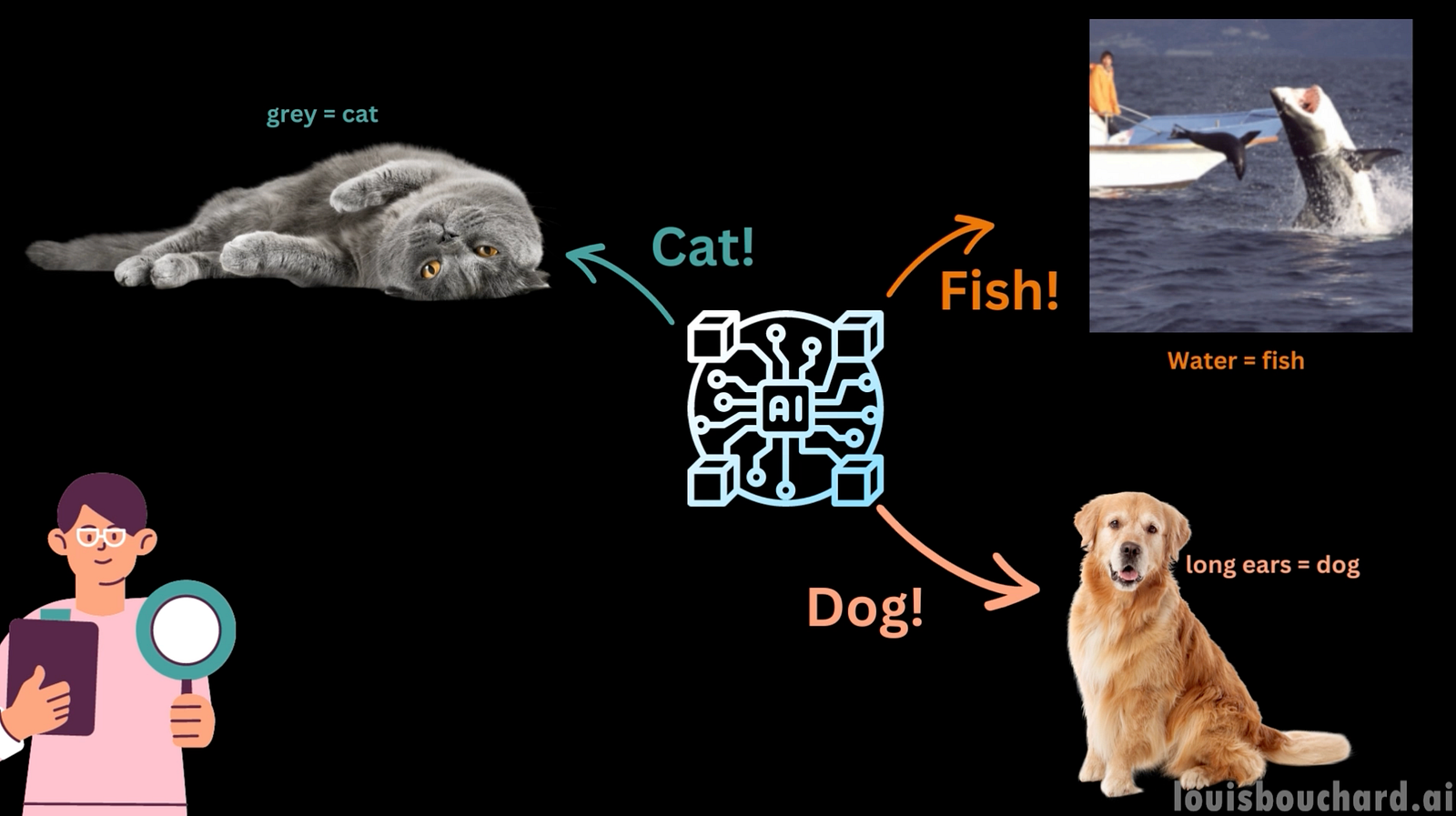
Well, that is far from it. What if your model was actually just lucky? Or, worse, it is making decisions based on completely unrelated parts of the image. This is where a very important topic comes into play: explainability. For instance, let’s take a look at what this model focused on here using an approach called a saliency map. This saliency map shows what part of the image the model focuses its attention on by attributing more weight to it.

Looking at this map, you see that the model isn’t focusing on the right features but fails confidently. Here, we see the pixels that affected the model’s decision the most, which aren’t even on the shark. The top right corner with the water confidently identified a killer shark.

If we hide it from the image and re-run the model, we now see the correct great white shark identified. I don’t know the two species enough to say if this is a grave mistake or not, but you can see how a model can confidently fail thanks to image features that aren’t relevant at all. Here, we could fix the problem by hiding those parts, but this was thanks to the saliency map that helped us understand the model’s decision process and its bias towards the water.
And now imagine an AI that controls your future self-driving car, making decisions because of completely unrelated objects on the road or in the sky. I wouldn’t be comfortable sitting in a car that couldn’t tell me why it decided to accelerate or brake. Luckily, there are techniques and companies that focus on this important issue, which provides an easy-to-use interface for interpreting your model’s results and decisions using Applied Explainability techniques.
Explainability AI, also known as XAI or interpretability in artificial intelligence, aims at demystifying the black box behind the decision-making process of AI models through various techniques.
It is worthwhile even when compromising on accuracy. Being able to justify and explain your decision is very important. Think of a researcher who couldn’t explain their conclusion. Would you trust it? This is why we do theorems and experiments: to have proof and a solid foundation for our beliefs. AI is the same. Understanding where the results come from makes the model much more valuable. Explainability also reduces the need for tons of experiments and the need for lots of manual tasks in order to identify and resolve issues to get better results.
In short, the goal here is to demystify the black box behind AI models, which is also my goal with this blog; how fitting!
[
The What’s AI Weekly by Louis-François Bouchard | Substack
We already saw one of such approaches used with models dealing with images: saliency maps, but there are many other approaches allowing you to better understand your model’s decisions, even if it’s dealing with complicated data that aren’t images of dogs and cats. In my video, we took a look at a specific and applied example using Tensorleap that you can actually use to build better models in the real world….
I hope this short introduction to XAI helped illustrate how important it is to take the time to explain the predictions of your model, not only quantitatively but also qualitatively. Classifying cats as dogs might not be problematic, especially because we rarely see both at the same place and time, but such model predictions based on the wrong features of the image on other tasks can lead to huge consequences.
This is a very exciting field that I hope more researchers will get into, allowing us to build more reliable models that we actually understand and trust. Hopefully, this article might motivate one more person to investigate their model’s decision-making process a little bit more and implement XAI techniques in their testing and validation pipeline, just like software developers have many tools that ensure their code is safe to deploy before doing so.
Also, let me know if you’d like more articles on the topic, like covering some specific approaches more in-depth or an interview with an expert in the field. I think it’s a very important field that I personally used a lot during my Master’s research, and I still am in the Ph.D.
FAQ
What is explainable AI?
Explainable AI uses methods that help people inspect which inputs or internal factors influenced a model's prediction.
How can an attention or saliency map reveal a failure?
It can show that a classifier relied on background artifacts instead of features belonging to the target object.
Why is confident accuracy not enough?
A model can achieve a good score through shortcuts that fail when the deployment environment changes.
How can explainability improve model development?
It helps teams find biased features, data gaps, mislabeled examples, and cases needing targeted retraining.
Does an explanation prove a model is correct?
No. Explanation methods are approximations and must be validated alongside performance, robustness, and domain expertise.