

The short version
LASR reconstructs an articulated 3D model of a person or animal from a short monocular video without starting from a matching shape template. It uses segmentation and optical flow, begins with a sphere, then adds detail and movable bones in stages. A differentiable renderer lets the system compare its output with the video and improve through self-supervised learning.
How hard is it for a machine to understand an image? Researchers have made a lot of progress in image classification, image detection, and image segmentation. These three tasks iteratively deepen our understanding of what’s going on in an image. In the same order, classification tells us what’s in the image. Detection tells us where it is approximately, and segmentation precisely tells us where it is.

Now, an even more complex step would be to represent this image in the real world. In other words, it would be to represent an object taken from an image or video into a 3D surface, just like GANverse3D can do for inanimate objects, as I showed in a recent video. This demonstrates a deep understanding of the image or video by the model, representing the complete shape of an object, which is why it is such a complex task.
Even more challenging is to do the same thing on nonrigid shapes. Or rather, on humans and animals, objects that can be weirdly shaped and even deformed to a certain extent.
This task of generating a 3D model based on a video or images is called 3D reconstruction, and Google Research, along with Carnegie Mellon University just published a paper called LASR: Learning Articulated Shape Reconstruction from a Monocular Video.
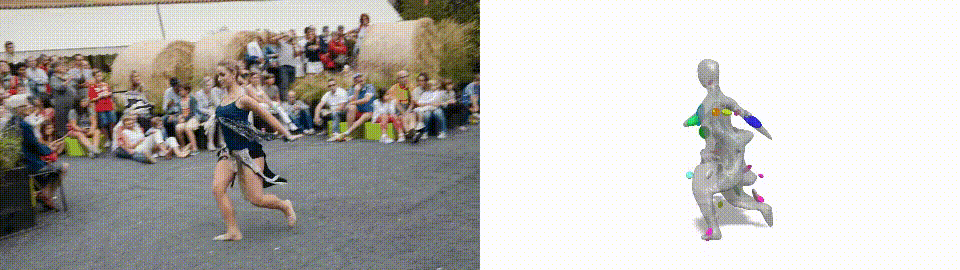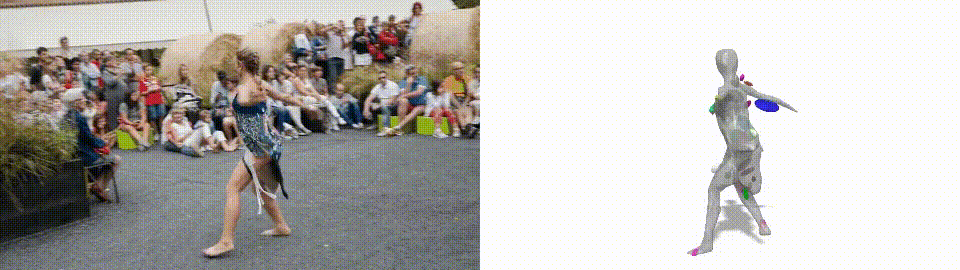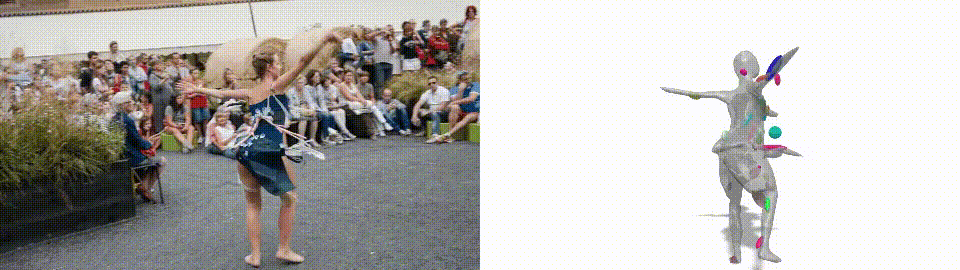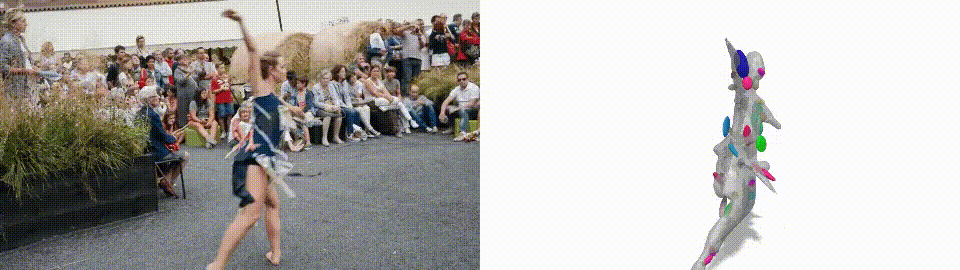
3D Reconstruction example. Gengshan Yang et al., (2021)
As the name says, this is a new method for generating 3D models of humans or animals moving from only a short video as input. Indeed, it actually understands that this is an odd shape, that it can move, but still needs to stay attached as this is still one “object” and not just many objects together.
Typically, 3D modeling techniques needed data prior. In this case, the data prior was an approximate shape of the complex objects, which looks like this… As you can see, it had to be quite similar to the actual human or animal, which is not very intelligent. With LASR, you can produce even better results. With no prior at all, it starts with just a plain sphere whatever the object to reconstruct. You can imagine what this means for generalizability and how powerful this can be when you don’t have to explicitly tell the network both what the object is and how it “typically” looks. This is a significant step forward!

Prior model vs. LASR. Gengshan Yang et al., (2021)
But how does it work? As I said, it only needs a video, but there are still some pre-processing steps to do. Don’t worry. These steps are quite well-understood in computer vision. As you may recall, I mentioned image segmentation at the beginning of the video. We need this segmentation of an object that can be done easily using a trained neural network.
Then, we need the optical flow for each frame, which is the motion of objects between consecutive frames of the video. This is also easily found using computer vision techniques and improved with neural networks, as I covered not even a year ago on my channel.

Model’s inputs for LASR
They start the rendering process with a sphere assuming it is a rigid object, so an object that does not have articulations. With this assumption, they optimize the shape and the camera viewpoint understanding of their model iteratively for 20 epochs. This rigid assumption is shown here with the number of bones equal to zero, meaning that nothing can move separately, as you can see at the left of this image.

Coarse-to-fine reconstruction from S0 to S3. Gengshan Yang et al., (2021)
Then, we get back to real life, where the human is not rigid. Now, the goal is to have an accurate 3d model that can move realistically. This is achieved by increasing the number of bones and vertices to make the model more and more precise. Here the vertices are 3-dimensional pixels where the lines and volumes of the rendered object connect, and the bones are, well, they are basically bones. These bones are all the parts of the objects that move during the video with either translations or rotations. Both the bones and vertices are incrementally augmented until we reach stage 3 (S3), where the model has learned to generate a pretty accurate render of the current object.
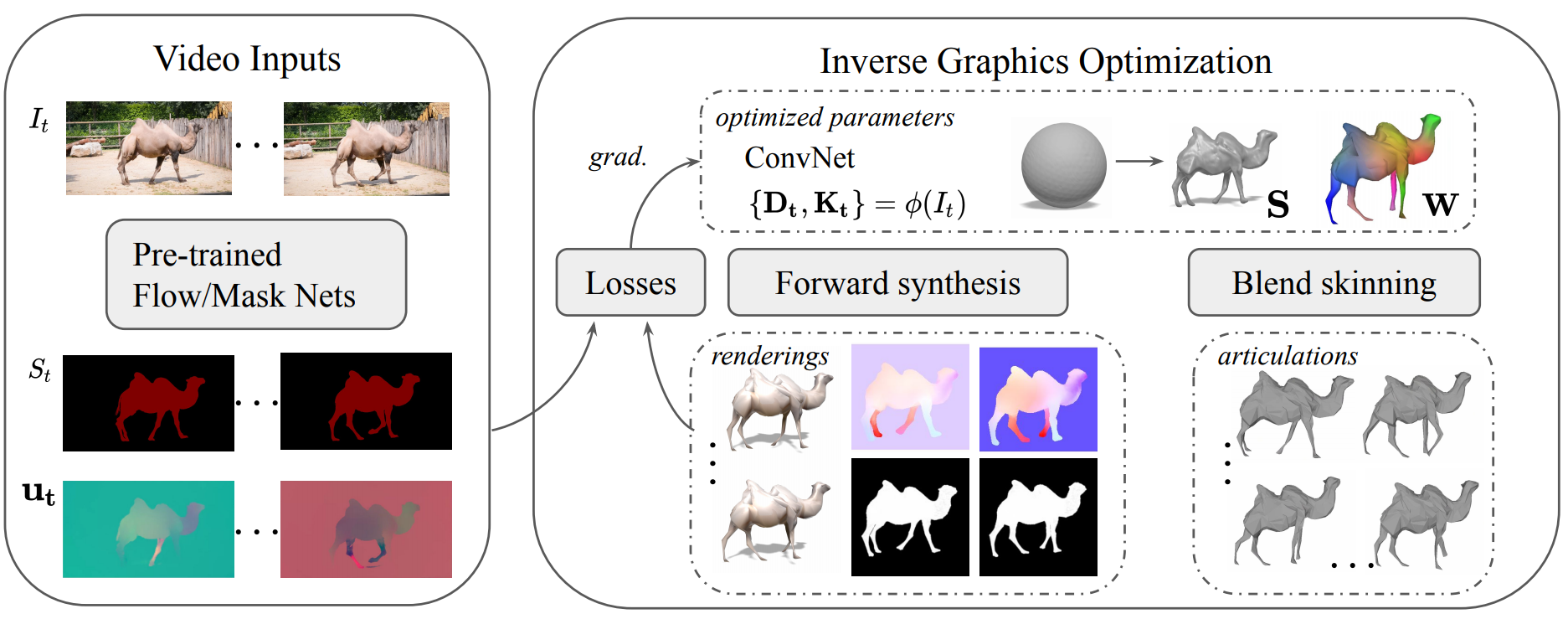
LASR model. Gengshan Yang et al., (2021)
Here, they also need a model to render this object, which is called a differentiable renderer. I won’t dive into how it works as I already covered it in previous videos, but basically, it is a model able to create a 3-dimensional representation of an object. It has the particularity to be differentiable. Meaning that you can train this model in a similar way as a typical neural network with back-propagation. Here, everything is trained together, optimizing the results following the four stages (S0-S3) we just saw improving the rendered result at each stage.
The model then learns just like any other machine learning model using gradient descent and updating the model’s parameters based on the difference between the rendered output and the ground-truth video measurements. So it doesn’t even need to see a ground-truth version of the rendered object. It only needs the video, segmentation, and optical flow results to learn by transforming back the rendered object into a segmented image and its optical flow and comparing it to the input.
What is even better is that all this is done in a self-supervised learning process. Meaning that you give the model the videos to train on with their corresponding segmentation and optical flow results, and it iteratively learns to render the objects during training. No annotations are needed at all!

3D Reconstruction example. Gengshan Yang et al., (2021)
And Voilà, you have your complex 3D renderer without any special training or ground truth needed! If gradient descent, epoch, parameters, or self-supervised learning are still unclear concepts to you, I invite you to watch the series of short videos I made explaining the basics of machine learning.
Thank you for reading.
Watch more examples in the video
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
Gengshan Yang et al., (2021), LASR: Learning Articulated Shape Reconstruction from a Monocular Video, CVPR, https://lasr-google.github.io/
FAQ
What does articulated 3D reconstruction produce?
It builds a three-dimensional representation of a moving human or animal from a short video rather than requiring a dedicated 3D scanning setup.
What input does the reconstruction method require?
The method starts from a video, then derives additional signals from its frames before optimizing the underlying 3D model.
Why does the method calculate optical flow?
Optical flow estimates how objects move between consecutive frames, giving the reconstruction system information about both shape and articulation over time.
What role does the differentiable renderer play?
It renders the current 3D estimate in a way that lets training errors flow backward and update the model through gradient descent.
How does the system learn the final 3D representation?
It repeatedly compares rendered outputs with measurements from the source video and adjusts its parameters to reduce the difference.