Create Realistic Animated Looping Videos from Pictures
This model takes a picture, understands which particles are supposed to be moving, and realistically animates them in an infinite loop while conserving the rest of the picture entirely still creating amazing-looking videos like this one.


Watch the video and support me on YouTube!
Have you ever taken a beautiful landscape picture and later on you noticed that it didn't look quite as good as when you were there. It may be because you just cannot freeze such a real-life landscape and expect it to look as good. In that case, what about having this picture animated where the normally-moving particles would be in constant movement, just like the moment you took the photo? Observing the water flow or see the smoke disperse in the air.

Have you ever taken a beautiful landscape picture and later on you noticed that it didn't look quite as good as when you were there. It may be because you just cannot freeze such a real-life landscape and expect it to look as good. In that case, what about having this picture animated where the normally-moving particles would be in constant movement, just like the moment you took the photo? Observing the water flow or see the smoke disperse in the air. Well, this is what a new algorithm from Facebook and the University of Washington does. It takes a picture, understands which particles are supposed to be moving, and realistically animates them in an infinite loop while conserving the rest of the picture entirely still creating amazing-looking videos like this one. Sincerely, I don't know why but I LOVE how it looks and wanted to share their work. What do you think about these results, and how would you use them? Personally, once the code is released, I am using these as desktop backgrounds.
Now that we've seen what it can achieve, I hope you are as excited as I was when discovering this paper. Let's get into the even more interesting things. Which is: how can they take a single picture and create a realistic animated looping video out of it? This is done in three important steps. The first step is to find what needs to be animated from what needs to stay still. In other words, find the water, smoke, or clouds to animate.
Of course, detecting these moving particles is extremely easy for humans as we can imagine the real scene and how it actually was, but how can a computer that sees only a picture and doesn't know the world do this? Well, the answer lies within the question: we need to teach it a bit more about the world and how it works, or in this case, how it moves. This is done by training an artificial intelligence model on videos of real landscape scenes instead of pictures. This way, it can learn how water, smoke, and clouds typically behave in the form of a flow field. This flow field is a version of the input image where each pixel value is an approximation of their direction and speed at a frozen time. It is called an Eulerian flow field. Eulerian flow fields look at how fluid moves focusing on a fixed location instead of following the particles of the fluid.

You can see this as sitting in front of a waterfall and watching the same exact positions observing how the water changes there, instead of following the water down the waterfall. And this is exactly what we need in this case as the image is precisely representing that: flowing water in a still position.

So using many landscape videos, they started by identifying these fields for each video. This is done quite easily as it actually moves during the videos, and we can use widely known techniques to identify the moving particles in each frame. Then uses this identified flow for each frame as a landmark to train their algorithm. The training starts with an image-to-image translation network using video frames as inputs. These identified flow fields are used to compare the outputs to teach the network in a supervised way what we want to achieve. This is done by iteratively correcting and improving the network based on the difference between the generated image and our known flow fields. After such training, the network can generate this flow field without any external help for any image of a landscape received. This works just like any other GAN architecture, or more precisely like any encoder coupled with a decoder. It first encodes the input frame, the landscape image, and then decodes it to generate a new version of the same image, conserving the spatial features and changing the image's style. In this case, the style changed is the pixel values which identify a motion field instead of the actual colors of the images. Once the network is trained, it can generate a map that looks just like this, which will be used for the whole animation as this Eulerian flow field representation doesn't need to change over time during the video as it shows how each pixel will behave in the next frame.
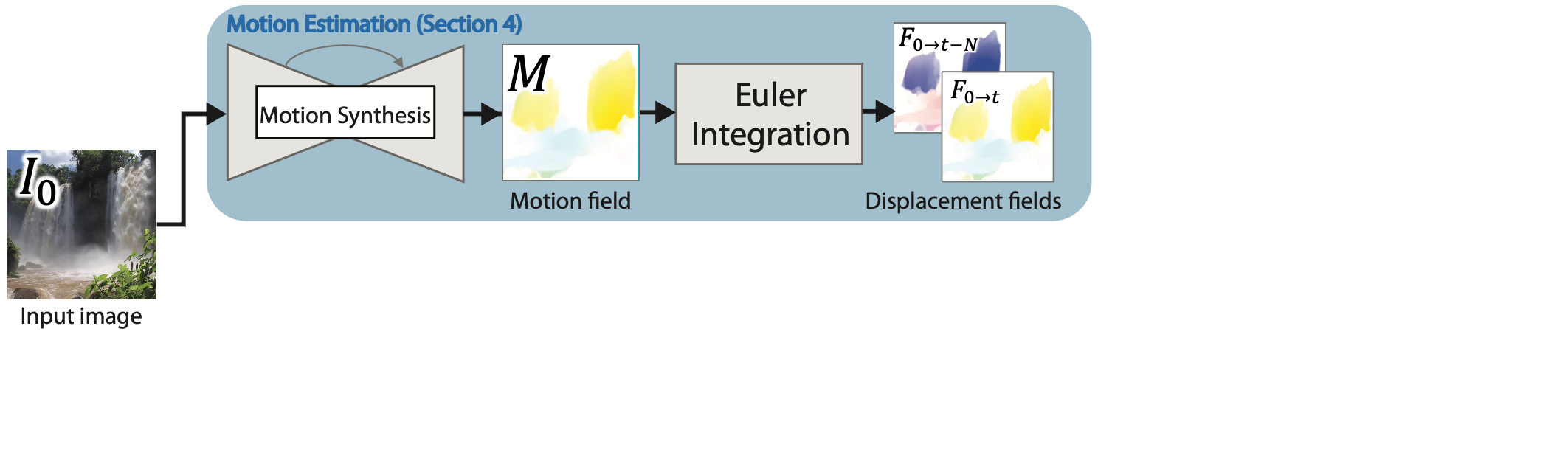
The second step is to animate these sections of the image and do it realistically. For this, we only need two things: the input image and the Eulerian or static flow estimation we just found for the image. Using this information, we know where the pixels are supposed to go next based on their speed and directions, but directly applying this will cause some issues as some pixels may not have any values after the translation, resulting in black holes starting where the motion begins in the picture. This is because:
- the predicted motion field isn't perfect and
- some pixels will go to the same resulting pixel after their displacement
which means that it will get worse over time and produce something like this.

So how can we make this more intelligent? Again, it is done using an encoder and a decoder and doing one more step in-between the two. So they encode the input frame a second time using a different encoder trained on this specific task, producing what they call here their deep features. These deep features are the encodings of the input image, meaning that it is a concentration of the important information for this task about the picture. What is judged "important information" here is what they optimized their model to do during training. Using these deep features, controlled by the displacement fields indicating how the next frame looks like, they use a decoder trained to generate the next frame from this condensed information about the frame and the flow field we give it.
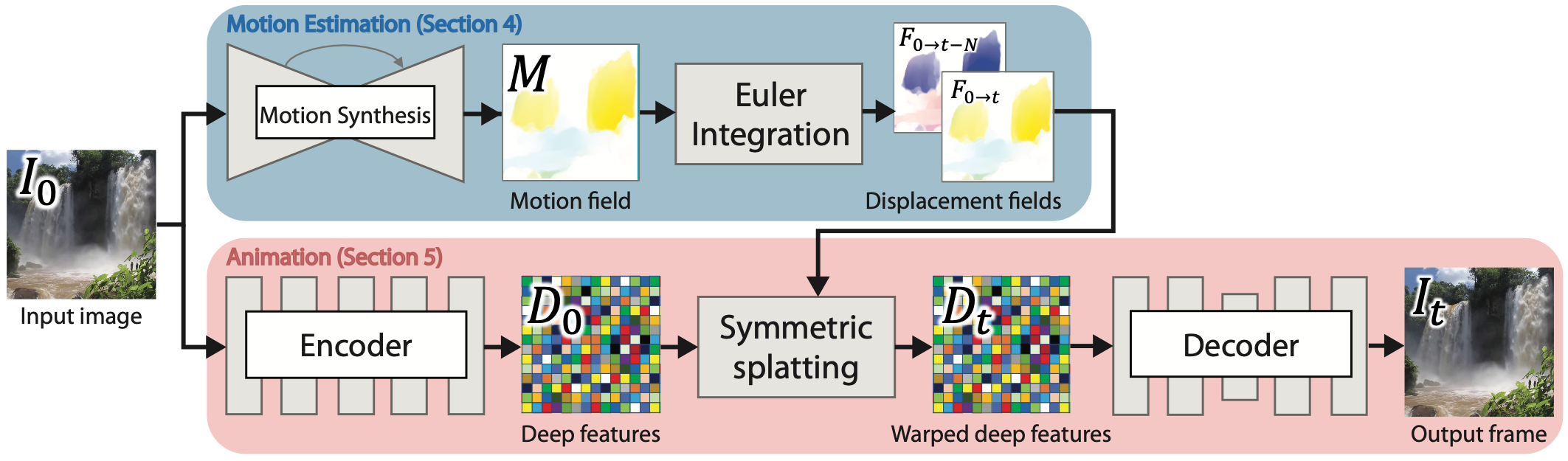
Note that during training, they used two different frames, the first and last frames, to learn the real-looking flow of the fluids and try to avoid such black holes from happening. Now comes the third and last step: the looping part. Using the same frame as starting frame, they generate animation in two directions, a forward movement and a backward movement, until they reach the second frame. This enables them to produce the looping effect by merging the two videos since one starts when the other ends and meets in the center. Then, at inference time, or in other words, when you actually use the model, it does the same thing with only a starting frame, which is the image you give the model. And voila, you have your animated image!

I hope you enjoyed this article as much as I enjoyed discovering this technique. If so, I invite you to read their paper too for more technical details about this super cool model. It is extremely well done!
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
- Paper: Holynski, Aleksander, et al. "Animating Pictures with Eulerian Motion Fields." Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021., https://arxiv.org/abs/2011.15128
- Project link (with code soon): https://eulerian.cs.washington.edu/