

The short version
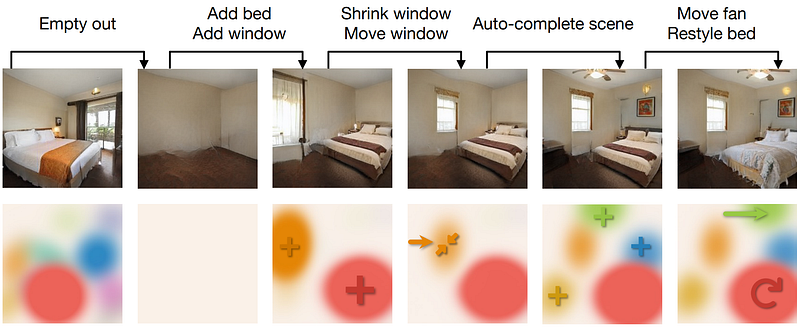
BlobGAN turns scene generation into a direct editing task by representing objects as movable, resizable, removable blobs. A first network maps random noise into a fixed set of blobs, and a StyleGAN2-like decoder converts that layout into an image. Adversarial training teaches recurring blobs to correspond to scene elements without object labels. Once trained, moving, duplicating, or deleting a blob changes its associated element, although results are not always realistic.
If you think that the progress with GANs was over, you couldn’t be more wrong. Here’s BlobGAN, and this new paper is just incredible.
BlobGAN allows for unreal manipulation of images, made super easily controlling simple blobs. All these small blobs represent an object, and you can move them around or make them bigger, smaller, or even remove them, and it will have the same effect on the object it represents in the image. This is so cool!
And you can actually play with this one compared to some companies we all know! They shared their code publicly and a Colab Demo you can try right away. Even more exciting is how BlobGAN works, which we will dive into in a few seconds.
Take a look at the results:
Now that you’ve seen some results in the video or simply the gif above, let’s get back to our paper, BlobGAN: Spatially Disentangled Scene Representations.
The title says it all, BlobGAN uses blobs to disentangle objects in a scene.
Meaning that the model learns to associate each blob with a specific object in the scene, like a bed, window, or ceiling fan. Once trained, you can move the blobs and objects around individually, make them bigger or smaller, duplicate them or even remove them from the picture. Of course, the results are not entirely realistic, but as a great person would say, “imagine the potential of this approach two more papers down the line”.
The blobs. Image from the authors’ paper.
What’s even cooler is that this training occurs in an unsupervised scheme. This means that you do not need every single image example to train it, as you would in supervised training. A quick example is that supervised training would require you to have all the desired manipulations in your image dataset to teach blobs to learn those transformations. Whereas in unsupervised learning, you do not need this extensive data, and the model will learn to achieve this task by itself, associating blobs to objects on its own without explicit labels.
We train the model with a generator and a discriminator in a GAN fashion. I will simply do a quick overview as I’ve covered GANs in numerous videos. As always in GANs, the discriminator’s responsibility is to train the generator to create realistic images. The most important part of the architecture is the generator with our blobs and a StyleGAN2-like decoder. I also covered StyleGAN-based generators in other videos if you are curious about how it works.
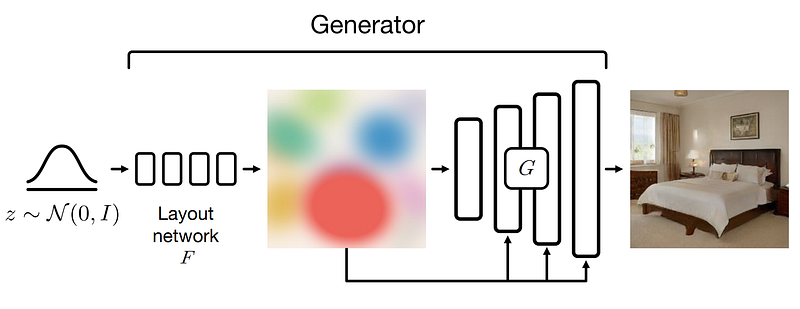
But, in short, we first create our blobs. This is done by taking random noise, as in most generator networks, and mapping it into blobs using a first neural network. This will be learned during training. Then, you need to do the impossible: take this blob representation and create a real image out of it?! This is where the GAN magic happens.
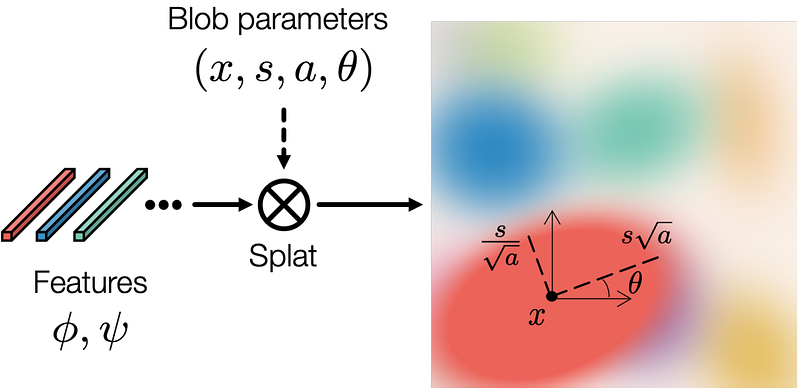
We need a StyleGAN-like architecture to create our images from these blobs. Of course, we edit the architecture to take the blobs we just created as inputs instead of the usual random noise. Then, we train our model using the discriminator to learn to generate realistic images. Once we have good results, it means our model can take on the blob representation instead of noise and generate images.
But we still have a problem. How can we disentangle those blobs and make them match objects?
Well, this is the beauty of our unsupervised approach. The model will iteratively improve and create realistic results while also learning how to represent these images in the form of a fixed number of blobs.
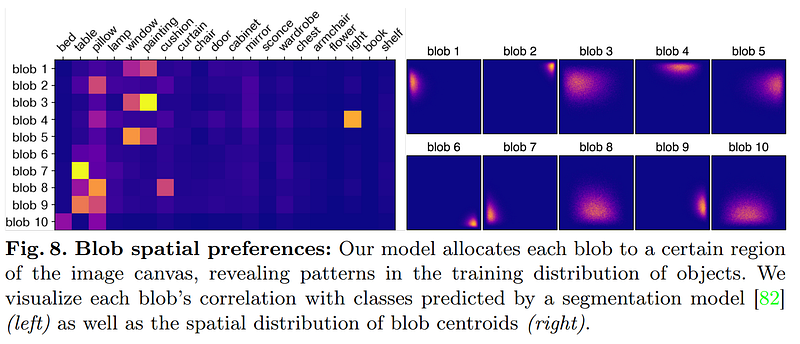
Image from the authors’ paper.
You can see here how blobs are often used to represent the same objects or very similar objects in the scene. Here, you see how the same blobs are used to represent either a window or painting, which makes a lot of sense. Likewise, you can see that light is almost always represented in the fourth blob. Similarly, you can see how blobs are often representing the same regions in the scene, most certainly due to similarities of images in the dataset used for the experiment.
And voilà!
This is how BlobGAN learns to manipulate scenes using a very intuitive blob representation! I’m excited to see the realism of the results improve, keeping a similar approach. Using such a technique, we could design simple interactive apps to allow designers or anyone to manipulate images easily, which is quite exciting.
Of course, this was just an overview of this new paper, and I’d strongly recommend reading their paper for a better understanding and a lot more detail on the approach, implementation, and tests they did.
Thank you for reading until the end, and I will see you next week with another amazing paper! Feel free to comment under my video or join our community on Discord and share your projects there, it’s called Learn AI Together and I would love to e-meet you there!
Reference
►Watch the video: https://youtu.be/mnEzjpiA_4E
►Epstein, D., Park, T., Zhang, R., Shechtman, E. and Efros, A.A., 2022. BlobGAN: Spatially Disentangled Scene Representations. arXiv preprint arXiv:2205.02837.
►Project link: https://dave.ml/blobgan/
►Code: https://github.com/dave-epstein/blobgan
►Colab Demo: https://colab.research.google.com/drive/1clvh28Yds5CvKsYYENGLS3iIIrlZK4xO?usp=sharing#scrollTo=0QuVIyVplOKu
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
FAQ
What is BlobGAN?
BlobGAN represents scene objects with simple controllable blobs before converting that layout into a generated image.
How do blobs make image editing easier?
Moving or resizing a blob gives the user a direct way to reposition an object without editing pixels manually.
Can BlobGAN edit objects independently?
Its structured representation is designed to change individual scene elements while preserving unrelated parts.
Why is this more useful than random GAN generation?
The intermediate layout provides explicit controls instead of asking users to accept a largely random image.
Does training require labels for every object?
No. The method learns its representation without requiring a fully annotated example for every image.