

Watch the video and support me on YouTube!
CVPR 2021 Best Paper Award Goes to Michael Niemeyer and Andreas Geiger from the Max Planck Institute for Intelligent Systems and the University of Tubingen for their paper called Giraffe, which looks at the task of controllable image synthesis. In other words, they look at generating new images and controlling what will appear, the objects and their positions and orientations, the background, etc. Using a modified GAN architecture, they can even move objects in the image without affecting the background or the other objects! CVPR is a yearly conference that happened just last week where a ton of new research papers in computer vision were out just for this event.

As you already know, if you regularly read my articles, conventional GAN architectures work with an encoder and a decoder setup, just like this. During training, the encoder receives an image, encodes it into a condensed representation, and the decoder takes this representation to create a new image changing the style. This is repeated numerous times with all the images we have in our training dataset so that the encoder and decoder learn how to maximize the results of the task we want to achieve during training. Once the training is done, you can send an image to the encoder, and it will do the same process, generating a new and unseen image following your needs. It will work very similarly whatever the task, whether it is to translate an image of a face into another style like a cartoonifier or create a beautiful landscape out of a quick draft. Using only the decoder, which we also call the generator since it is the model responsible for creating the new image, we can walk in this encoded information space and sample information that we send the generator to generate an infinite amount of new images. This encoded information space is often referred to as the latent space, and the information we use to generate the new image the latent code. We basically select some latent code randomly within this optimal space, and it generates a new random image following the task we want to achieve, following a training process of this generator, of course. This is incredibly cool, but as I just said, the image is completely random, and we have no or few ideas on what it will look like, which is already a lot less useful for creators.
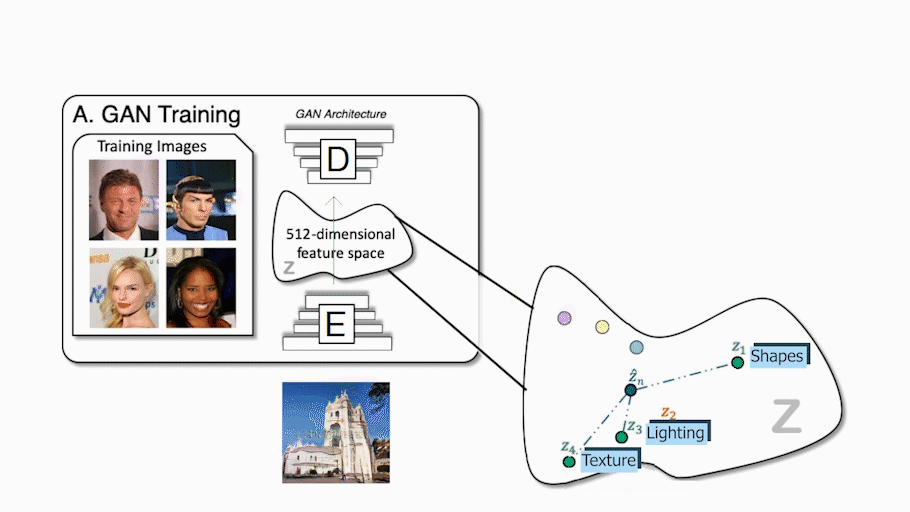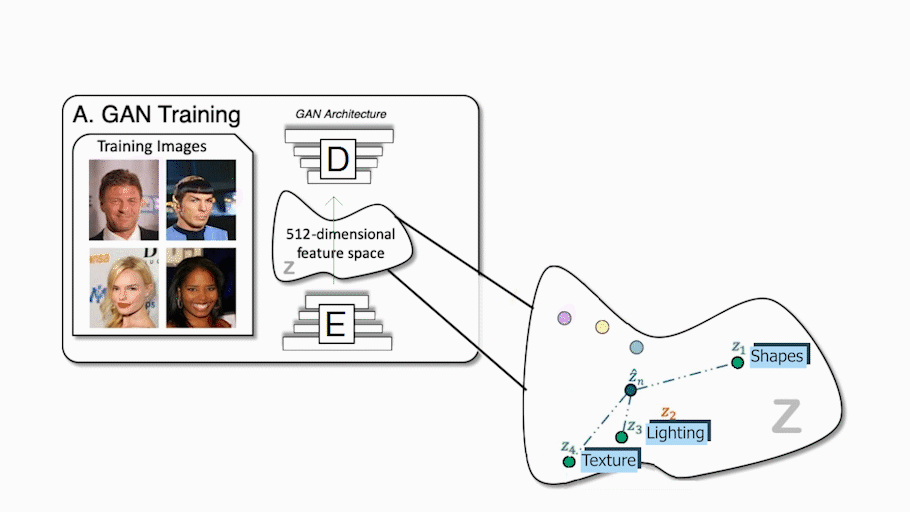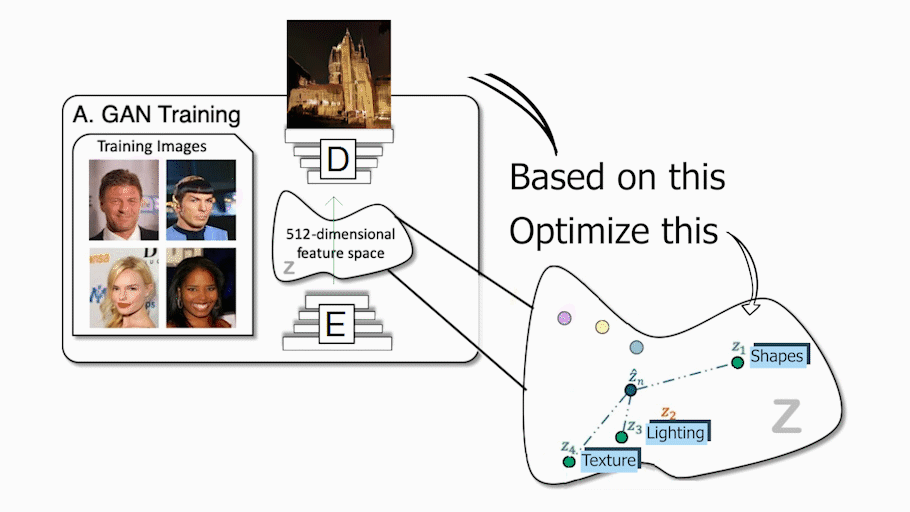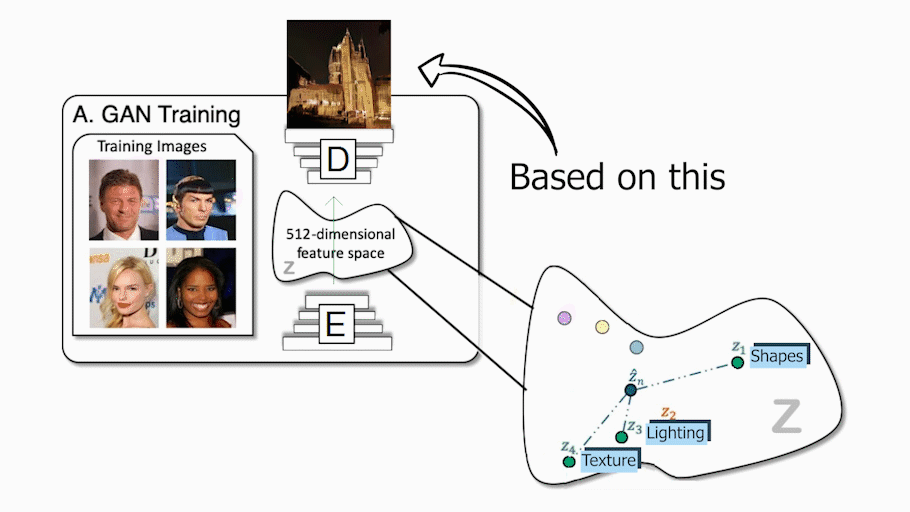
GAN example. Michael Niemeyer and Andreas Geiger (2021)
This is the problem they attacked with this paper. Indeed, by taking latent codes of the shape and appearances of objects and sending it to the decoder, or generator, they are able to control the pose of the objects, which means they can move them around, change their appearances, add other objects, change the background and even change the camera pose. All these transformations can be done independently on each object or background, without affecting anything else in the image!


GIRAFFE on the left, and a regular 2D GAN approach on the right. Michael Niemeyer and Andreas Geiger (2021)
As you can see, it is MUCH better than other GAN-based approaches that typically cannot disentangle the objects from one another and are all affected by the modification of a specific object.
The difference with their method is that they attack this problem in a three-dimensional scene representation, just like how we see the real world, instead of staying in the two-dimensional image world as other GANs do. But other than that, the process is quite similar. They encode the information, identify the objects, edit them inside the latent space, and decode it to generate the new image. Here, there are just some more steps to do inside this latent space. We can see this as a combination of the classical GAN image synthesis network with a neural renderer used to generate the 3D scene from the images sent to the network, as we will see.
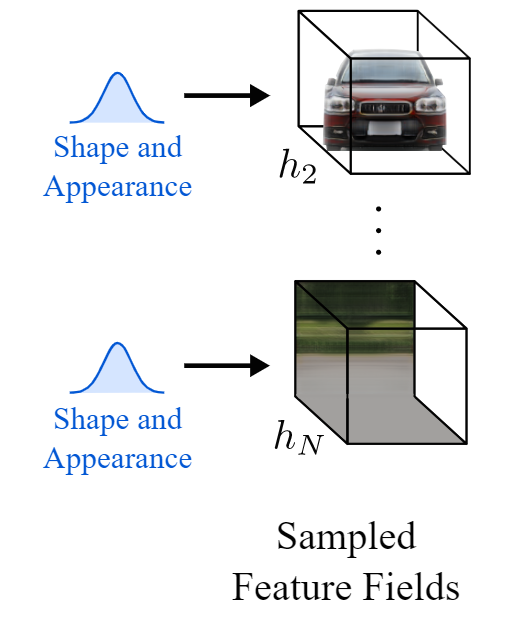
Generation of objects individual 3D representations. Michael Niemeyer and Andreas Geiger (2021)
There are three main steps to achieve that. After encoding the input image, meaning that we are already in the latent space, the first step is to transfer the image into a 3D scene. But not just a simple 3D scene, a 3D scene composed of 3D elements, which are the objects and background. This way of seeing the images as a scene composed of generated volume renderings allows them to change the camera angle in the generated image and control the objects independently. This is achieved using a similar model as the paper I previously covered called NERV, but instead of using a single model to generate the entire locked scene from the input image, they independently generate the objects and background using two separate models. Here called the Sampled Feature Fields. The parameters of this network are also learned during training. I won’t enter into the details, but it is very similar to NERF, which I covered in another article. If you would like to have more details on such networks, you can watch this video about NERV, and it is also linked in the references below.
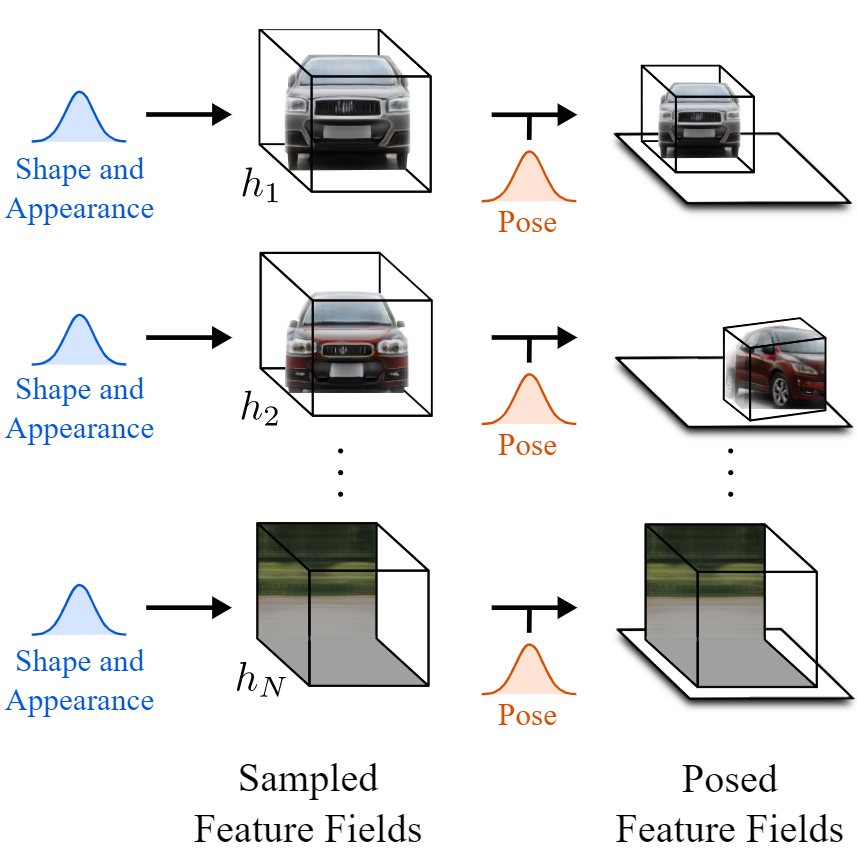
Pose transition in the 3D representation. Michael Niemeyer and Andreas Geiger (2021)
Having this scene with disentangled elements, we can edit them individually without affecting the rest of the image. This is the second step. They can do whatever they want to the object, like changing its position and orientation.
In other words, they change the pose of the objects or background. At this point, they can even add new objects placed wherever they want. Then, they simply combine them into a final 3D scene containing all the objects and background by adding all feature fields together.
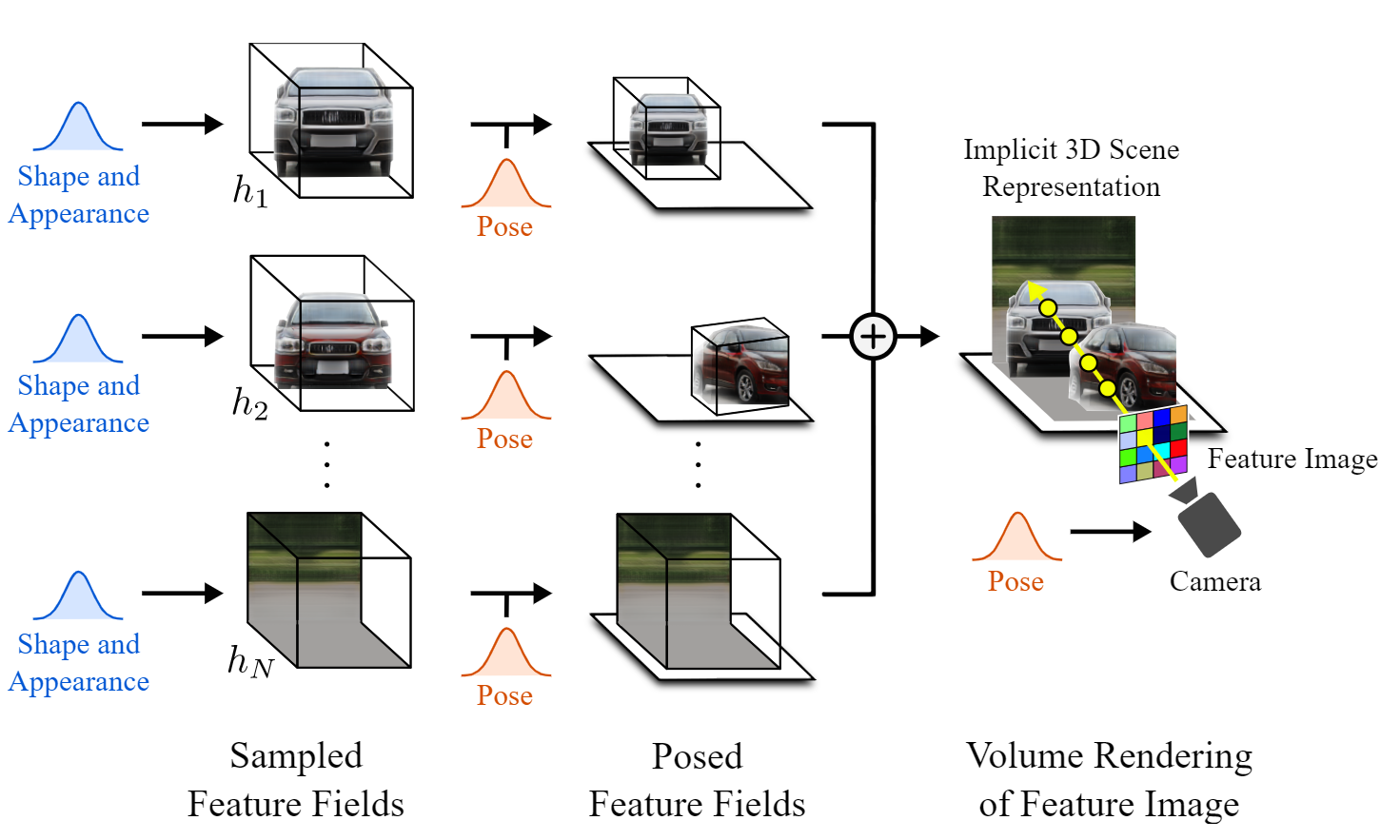
The complete latent space computations. Michael Niemeyer and Andreas Geiger (2021)
Finally, we have to come back to the 2D world of natural images. So the last step is to take this 3D scene and render a regular image out of it. Since we are still in the 3D world, we can change the camera viewpoint to decide how we will look at the scene. Then, we evaluate each pixel based on this camera ray and other parameters such as the alpha value and the transmittance. This gives us what they call the feature image, but this feature image is an image composed of feature vectors for each pixel. As we are still in the latent space, these features need to be translated into RGB colors and high-resolution images. This is done using the typical decoder just like other GAN architectures, upscaling it back to its original dimensions and learning the feature to RGB channels translation simultaneously. And voilà, you have your new image with a lot more control over what is generated!
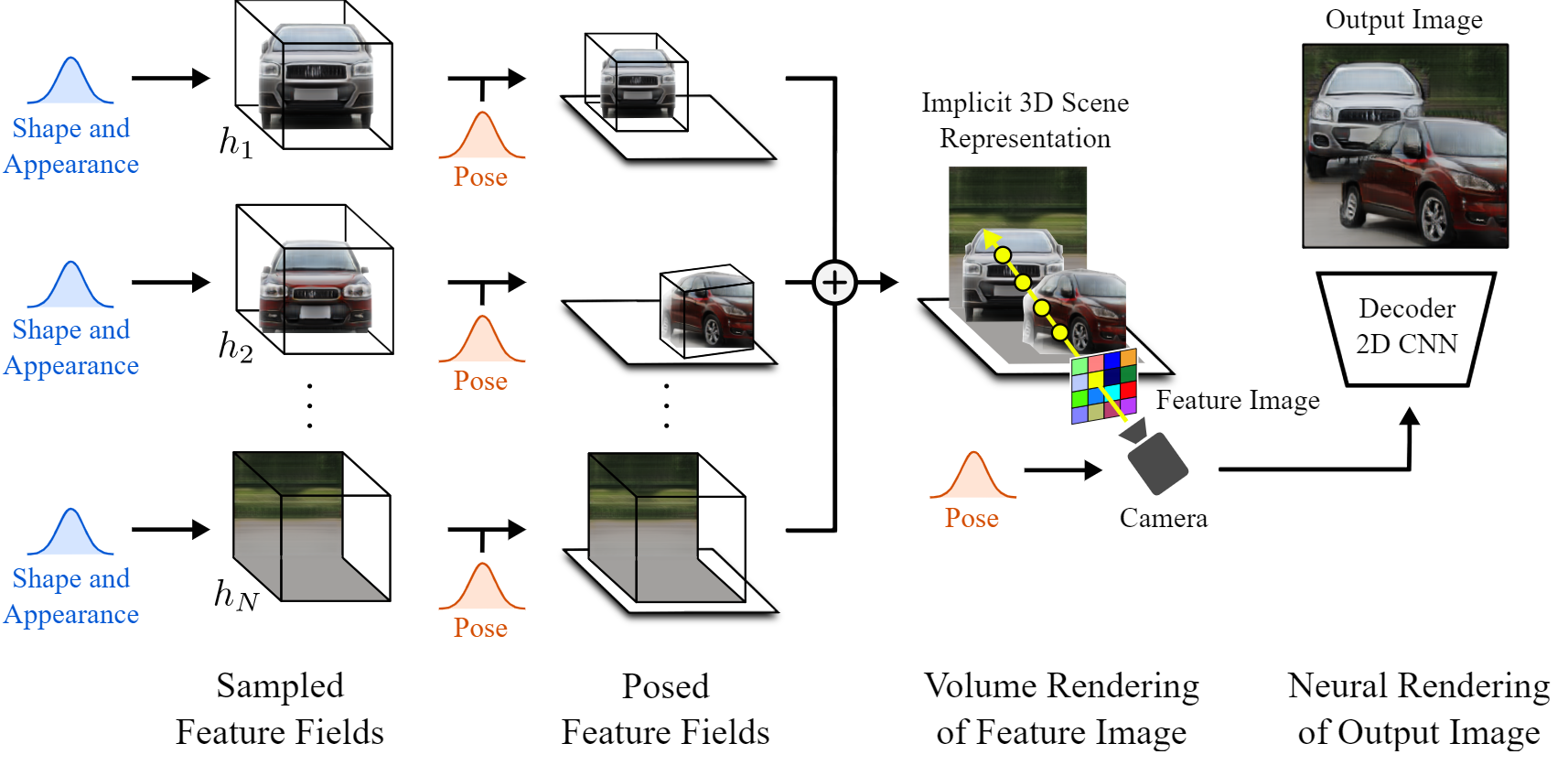
The complete network, after the encoding from an encoder. Michael Niemeyer and Andreas Geiger (2021)
Of course, as you can see, it is still not perfect when used on real-world data. Still, it is extremely impressive and is a significant step forward in the right direction, especially considering that these are synthetic images entirely generated by GANs and that it is only the first paper able to control generated images at this level of precision.
Imperfections examples. Michael Niemeyer and Andreas Geiger (2021)
The paper is really interesting, and I recommend reading it to understand how their model works. Congratulations to Michael Niemeyer and Andreas Geiger for their well-deserved best paper award. They also made the code available on their GitHub if you would like to play with it. The link is in the references below
Thank you for reading!

Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
- Michael Niemeyer and Andreas Geiger, (2021), “GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields”, Published in CVPR 2021.
- Project link with paper and more: https://m-niemeyer.github.io/project-pages/giraffe/index.html
- Code: https://github.com/autonomousvision/giraffe
- NERF video: https://youtu.be/ZkaTyBvS2w4
FAQ
What does GIRAFFE generate?
GIRAFFE generates images from an explicit 3D-aware scene representation rather than treating the full picture as one uncontrolled output.
How does GIRAFFE improve controllability?
It represents objects separately, allowing position, orientation, and camera viewpoint to change without rebuilding the entire scene.
Can one object move without changing the background?
Yes. Independent object representations are designed to preserve unrelated scene components during an edit.
Why is control important for image generation?
Creators need repeatable changes to specific elements, not only visually appealing but random samples.
What makes the method 3D-aware?
It composes generated volume representations into a scene that can be rendered from different camera angles.