

Key takeaways
- This is a big deal for the film industry, allowing you to instantly re-age someone for a whole movie with very little cost.
- This means that the model is able to take a face and change how old the person looks with consistency, realism, and high-resolution results across variable expressions.
- Well, here’s both a solution and a new problem to this situation.
Watch the video
Whether it be for fun in a Snapchat filter, for a movie, or even to remove a few wrinkles, we all have a utility in mind for being able to change our age in a picture.
This is usually done by skilled artists using Photoshop or a similar tool to edit your pictures. Worst, in a video, they have to do this kind of manual editing for every frame! Just imagine the amount of work needed for that. Well, here’s both a solution and a new problem to this situation.

Results from FRAN’s paper.
Disney’s most recent research publication, FRAN, can do that automatically. This is a big deal for the film industry, allowing you to instantly re-age someone for a whole movie with very little cost. However, it is a problem for artists simultaneously cut some job opportunities and help them cut long and tedious work hours to focus on talent-related tasks. Something cool here is that they created a FRAN-based tool for artists to use and edit the results, making their work more efficient by focusing on improving the details rather than monotonic copy-pasting edits. I’d love to hear your thoughts about that on our Discord community. But let’s focus once more on the purely positive side of this work: the scientific progress they made in the digital re-aging of faces in video.

Results from FRAN’s paper.
What you’ve been seeing are the results of this new FRAN algorithm, and I believe you can already agree on how amazing these results look! Just look at how much more realistic it looks compared to other state-of-the-art re-aging approaches that contain many artifacts and fail to keep the person’s identity the same (see below). Plus, FRAN’s approach does not require to center the faces as these other approaches do, which makes it even more impressive. What’s even more incredible is how simple their approach is.

Results comparison. Image from the paper.
First, FRAN unsurprisingly stands for Face Re-Aging Network.
This means that the model is able to take a face and change how old the person looks with consistency, realism, and high-resolution results across variable expressions, viewpoints, and lighting conditions.
For movies, the actor’s age appearance is usually changed by the production team using dedicated costumes, hairstyles and etc., to depict the aimed age, and only the face is left for digital artists to edit frame by frame, which is where FRAN comes in, focusing strictly on skin regions of the face. They also focus on adult ages as movies already have efficient and different techniques for very young re-aging as the whole body and faces’ shapes are different and smaller in those cases.
But how can they take a face from any position and just change its appearance to add or remove a few dozen years? Mainly because they have no ground truth on this task. Meaning that they cannot train an algorithm to replicate before and after pictures. Very few examples exist of the same person with 20 or more years apart in every angle. They need to have a different approach than conventional supervised learning approaches where you try to replicate the examples you already have. Typically, researchers tackle this problem using powerful models trained on generated fake faces of all ages. Though the results are pretty impressive, they mainly work on centered and frontal faces due to the training data of fake faces generated for it. Thus, the results are hardly generalizable to real-world scenes since they do not really keep the identity of the person as it was not trained using the same person at different time periods, but just a variety of different people of different ages and such static models can hardly produce realistic facial movements due to its training on static images: it doesn’t know real-world mechanics, lighting changes, etc.

Results from SAM’s paper.
Their first contribution is tackling this gap in the number of images from the same person at different ages. Their goal here is to do the same thing as previous approaches but with a small tweak. They will still be using generated, fake faces but will build a dataset full of the same faces with different ages, so the same background and same everything to have the algorithm focus strictly on the face. They figured that even if these approaches do not really generalize well in the real world and in video scenes, they still understand the aging process really well, so they could use it to generate more images of they same person at different ages as a first step to build a better dataset. This step is done using a model called SAM, which can take a person’s face that is perfectly centered and re-age it. It will only be used to construct our set of before and after pictures to be used for training their FRAN algorithm. This step is necessary since our algorithms are too dumb to generalize from few examples as we do, and we cannot get nearly as many pictures of real faces with the same lighting, background, and clothing at different ages: it must be artificially generated.
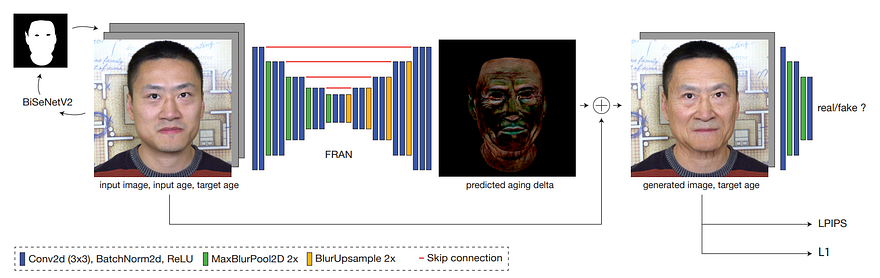
Overview of the FRAN model. Left: U-Net model to generate the predicted mask for re-aging. Right: the discriminator’s prediction of real (from the dataset) or generated images for training. Image from the paper.
The second contribution is using this new set of images they created and training an algorithm able to replicate this process on real-world scenes along with good consistency across video frames. The algorithm they built is, in fact, quite simple and similar to most image-to-image translation algorithms you will find. They use a U-Net architecture, which takes an input and output age and an image to learn the best way to transform it into a new image by encoding it into the most meaningful space possible and decoding it into the new image. So the network learns to take any image and get it into what we call a latent space where we have our encodings. This latent space basically contains all the necessary information the network learned for its specific task, so the different features of the face for this particular individual, but does not contain information about the image background and other features that aren’t necessary for re-aging.
Then, it takes this information to predict some kind of re-aging mask. This mask will only contain the parts that need to be edited in the picture for a re-aging effect making the task much more manageable than predicting the whole image once again. And we simply merge this predicted mask to our initial image to get the re-aged face. This mask is the main reason why their approach is so much better at preserving the person’s identity since they limit their network’s field of action to the re-aging modifications only and not the whole image. When you can’t make it more intelligent, just make it more specific!
The model is trained following a GAN approach, which means it will use another model that you see in the model’s overview image above, on the right, called a discriminator trained simultaneously used to calculate if the generated re-aged image is similar to the ones we have in our training dataset, basically rating its results for guiding the training.
And voilà! This is how FRAN helps you re-age your face anywhere between 18 and 85 years old.
Of course, this was just a simple overview of this new DisneyResearch publication, and I’d recommend reading their excellent paper for more information and results analysis. If you are unfamiliar with GANs, I suggest watching the short introduction video I made about them.
Thank you for reading, and I will see you next time with another amazing paper!
References
►Loss et al., DisneyResearch, 2022: FRAN, https://studios.disneyresearch.com/2022/11/30/production-ready-face-re-aging-for-visual-effects/
►GANs explained: https://youtu.be/ZnpZsiy_p2M
►SAM: https://yuval-alaluf.github.io/SAM/
►Discord: /learn-ai-together/
FAQ
What is the useful lesson from Automatic Re-Aging with AI! Disney’s FRAN Model Explained?
Disney's New Model Explained. This is a big deal for the film industry, allowing you to instantly re-age someone for a whole movie with very little cost.
What can break in automatic Re-Aging with AI! Disney’s FRAN Model?
This means that the model is able to take a face and change how old the person looks with consistency, realism, and high-resolution results across variable expressions, viewpoints, and lighting conditions.
What should you check in the outputs from automatic Re-Aging with AI! Disney’s FRAN Model?
Well, here’s both a solution and a new problem to this situation.
How should builders use automatic Re-Aging with AI! Disney’s FRAN Model?
Well, here’s both a solution and a new problem to this situation.
When does automatic Re-Aging with AI! Disney’s FRAN Model become useful in practice?
However, it is a problem for artists simultaneously cut some job opportunities and help them cut long and tedious work hours to focus on talent-related tasks.
What should beginners understand about automatic Re-Aging with AI! Disney’s FRAN Model?
Typically, researchers tackle this problem using powerful models trained on generated fake faces of all ages.
What is the common mistake with automatic Re-Aging with AI! Disney’s FRAN Model?
Well, here’s both a solution and a new problem to this situation.