Harness Engineering: The Missing Layer Behind AI Agents
The clearest way to understand the difference between prompt engineering, context engineering, and harnesses


Watch the video format!
If you’ve been hearing “harness engineering” everywhere lately and your first thought is, okay, so this is probably just prompt engineering with a nicer name, that’s the first misconception to kill.
It’s not, and it’s not “just” a new term.
And the reason this matters is not just vocabulary. It tells you where AI is actually heading. By the end of this, you should be able to tell the difference between prompt engineering, context engineering, and harness engineering, and more importantly, why the industry suddenly started caring about this now.
What changed is pretty simple. Agents got good enough to be useful, but not reliable enough to trust on their own. That’s the entire story.
Agents got good enough to be both useful and dangerous. They now can do more than generating text, or token. Useful enough that people started letting them write serious code, make real tool calls, and operate across long tasks. Dangerous enough that if you wrapped them in nothing but a loop and a dream, they would confidently make the same stupid mistake again and again. Even I am guilty of letting Claude Code loop for way too long sometimes before actually looking into what it was doing as I was doing something else in parallel.
That’s really where harness engineering came from. It came from pain. It came from people realizing that once the model is capable enough, the bottleneck stops being “can it generate code?” and becomes “can I make it behave reliably inside a real system?”
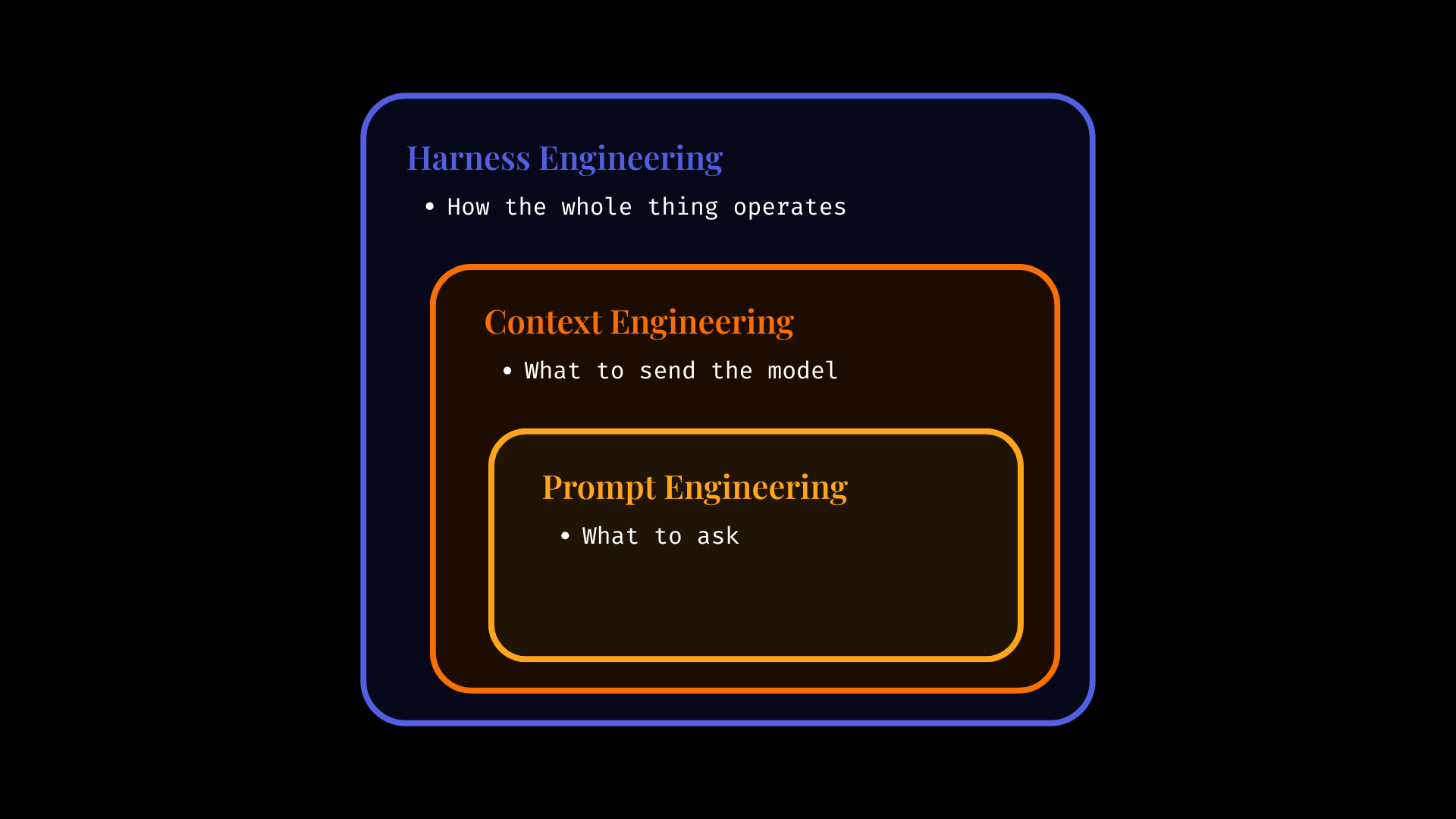
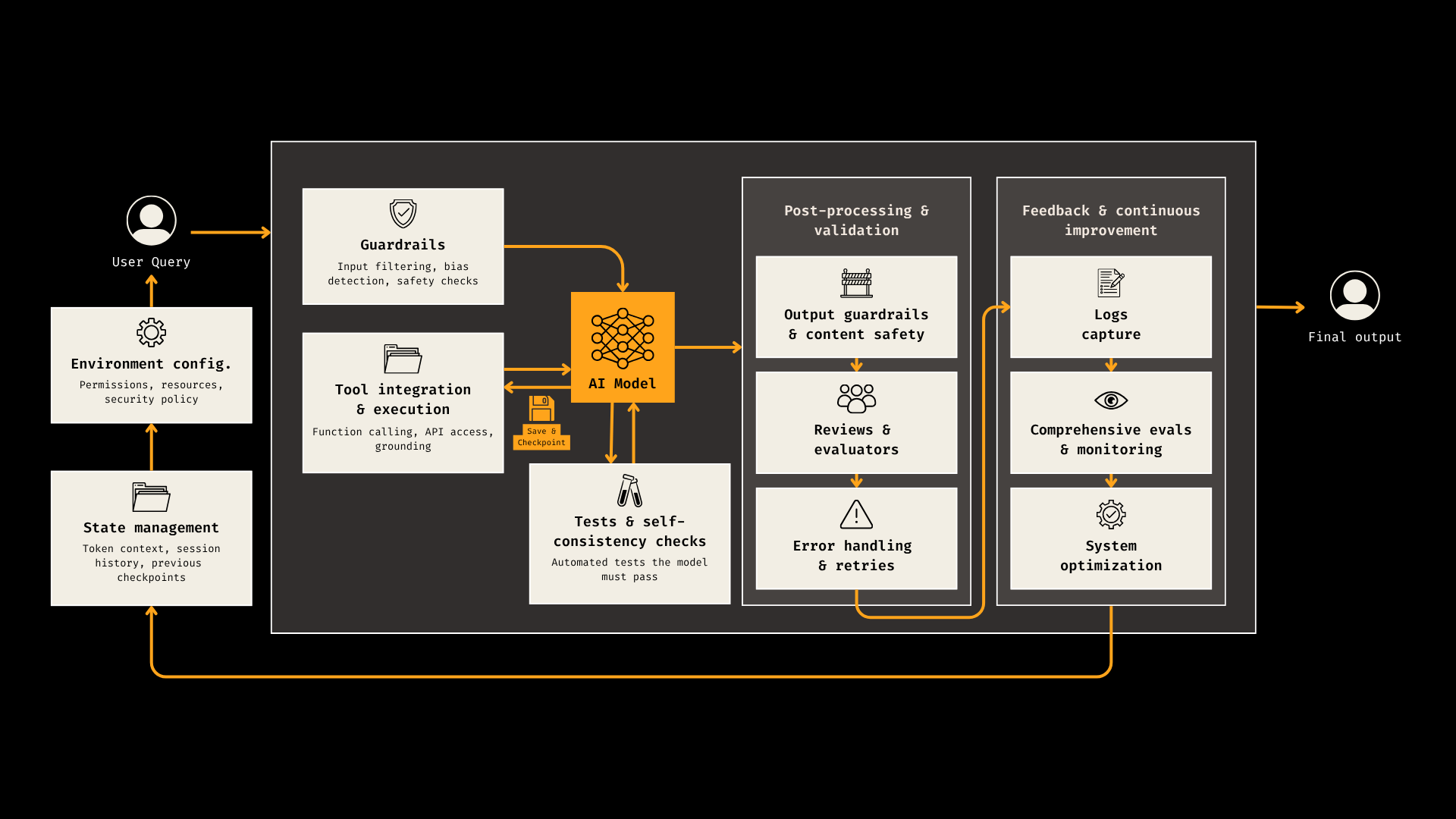
The cleanest way to think about it is this. Prompt engineering is what to ask. Context engineering is what tosend the model so that it can answer confidently. Harness engineering is how the whole thing operates. Not just the words in the prompt, not just the tokens in context, but the environment around the model. The tools it can use. The permissions it has. The state it carries forward. The tests it has to pass. The logs you capture. The retries, checkpoints, guardrails, reviews, and evals that stop the system from drifting into nonsense. Context engineering lives inside that. It matters a lot. But it is not the whole story. A bigger context window does not magically turn a flaky agent into a reliable system.
The model is the engine. You can’t do much without it, but when you buy a car, it comes with it. You work on what you can bring value. Context is part of the fuel, oil changes and dashboard information. It’s the things you can easily optimize and control. The harness is the rest of the car. Steering, brakes, lane boundaries, maintenance schedule, warning lights, and the fact that the doors shouldn’t fall off on the highway. If you only focus on the engine and fuel, you can still build a terrible car.
This started becoming obvious around December 2025. Karpathy talked about this inversion where his workflow went from mostly manual coding with a bit of agent help to mostly agent driven coding with manual edits. That sounds like the story should be “wow, the models won.” But that’s not really the story. The story is that the moment agents got coherent enough to do a lot, everyone also discovered how brittle they were in real environments. They would claim a feature was done without running tests or even without really having implemented the feature. They would lose the plot over long tasks. They would make local fixes that broke architectural boundaries. They would get stuck in loops making tiny edits forever, which also stimulated a lot of research around compaction that I’d be happy to talk about in an upcoming article if you’d like. Let me know!
Anthropic was one of the clearest early signals here. Their long running agents post was basically a blueprint for a world where agents work in shifts, across sessions, without native memory between context windows. So instead of pretending the model will just remember everything, they externalized memory into artifacts. A structured feature list. A progress log. Git commits. An init script. They even split roles between an initializer agent and a coding agent. That’s already harness thinking. You stop asking the model to be magically reliable, and you start designing a system that makes reliability more plausible for the agent.
We started coding around LLMs and agents instead of around existing systems.
Then Mitchell Hashimoto gave the thing a name in early February 2026. And honestly, I think his framing is why the term stuck: Every time the agent makes a mistake, don’t just hope it does better next time. Engineer the environment so it can’t make that specific mistake the same way again. Improve AGENTS.md based on actual bad behaviour. Add scripts, linters, checks, and tools so the agent can verify and fix its own work. That is a very important mindset shift because it moves the burden away from waiting for the next model release and back to the builder. You stop saying “this model is dumb.” You start saying “my system allowed this failure mode”. And most importantly, we stop waiting for model providers to further improve models and adapt our tools and setup for it, which can even be done for non-coders with better skill files and prompting in general, iterating with the agents to do better each time you use it. For example, in each of my skills files with Claude Code or Cowork, I added a last step to reflect back on the whole exchange and digest and understand what I liked and didn’t, so that it can tweak its own skill to be better next time. I also sometimes simply ask it to spend some time finding a better way to do the task, and if it works, I ask it to change the skill. It’s saved me tons and tons of tokens and time since I started doing this.
Then OpenAI made the whole thing impossible to ignore. Their report described building an internal product with roughly a million lines of code and zero manually written source code. Same for Claude Code’s creator, who shared a tweet saying all past Claude Code lines were pushed by Claude Code itself. What matters there is not just the headline. It’s what they had to build around the agents to make that possible. Structured repo docs as a real source of truth. AGENTS.md as a map, not a giant wall of text. Layered architecture enforced by linters and tests. Agent to agent review loops before merging. Background cleanup agents fixing drift. That is not just writing prompts. That is infrastructure design. That is software engineering moving one level up.
And this is where the link with context engineering becomes really useful, because I think a lot of people are mixing these two terms up right now. Context engineering is about making the task plausibly solvable for the model in a given moment. What information should be in the window? What should be retrieved? What should be summarized? What should be evicted? That’s real work, and parts of it can be automated by the agent itself. It’s one of the main reasons many systems improved beyond dumb prompting. But a harness decides when that context gets loaded, which tools are available, which actions are allowed, how failures get handled, and what happens before anything gets called “done.”
Your harness is the infrastructure you build around the model.
So context engineering might make sure the model sees the right database schema. Harness engineering is the reason it still has to run the linter, pass the tests, respect permissions, and save progress so it doesn’t forget the objective three turns later. One is what the model sees. The other is how the system behaves.
This also explains why people are talking about progressive disclosure so much. If you dump your entire company brain into one giant AGENTS file, the agent doesn’t become wiser. Usually it becomes worse. More noise, more context rot, more things silently ignored. The better pattern seems to be a short map up front and deeper sources of truth pulled in only when needed. That’s context engineering inside a harness. The harness decides what to surface and when, instead of treating the context window like a landfill.
Now, why does all of this matter beyond people building coding agents all day? Because this is starting to look like the new way software gets built. Not fully, not cleanly, and definitely not safely by default. But the direction is becoming clearer. LangChain showed that by changing only the harness, not the model, they could move a coding agent from outside the Top 30 to Top 5 on Terminal Bench 2.0. Same model, better system. Stripe reportedly has agents producing over a thousand merged pull requests per week, but inside isolated environments, with hard CI limits and escalation rules. Datadog pushed the idea further by treating production telemetry as part of the harness itself. If performance regresses, that signal goes back into the loop. That is not “vibe coding.” That is generate, validate, fix, with observability.
And there’s an even more important implication here. The programmer’s job is shifting. Not disappearing. Shifting. Less time typing every line by hand. More time designing habitats where agents can do useful work without wrecking everything around them. More machine readable documentation. More evals. More sandboxes. More permission boundaries. More structural tests. More logs, traces, and replayability. Prompting is the easiest part. Reliability is the real work.
The honest version, though, is that none of this means agents are magically solved. Memory still breaks. Validation still misses things. Tool use still creates security risk. Harness debt is real, because now your harness becomes its own product with its own bugs and drift. And human attention becomes the real scarce resource. If agents can generate way more output than humans can carefully inspect, then rigor has to move into the system. You cannot review everything manually forever. You need checks you trust. You need environments that fail safely. You need traces that tell you why something went wrong.
So when people ask where LLMs are heading, I think the better answer is this. They’re heading into systems. Into workflows, agents, runtimes, and harnesses, where more of the value comes from orchestration, constraints, and feedback loops than from a prompt screenshot on social media. The future is probably less “one genius model does everything” and more “models operating inside well engineered environments that make them usable.”
And that’s why harness engineering matters. It is not a trendy rename for prompting. It is what shows up when you stop demoing intelligence and start trying to ship it.
Thanks for reading throughout!