How LLMs Know When to Stop Talking?
Understand how LLMs like GPT-4 decide when they have effecrtively answered your question


Watch the video!
Introduction
A few days ago, I had a random thought: How does ChatGPT decide when it should stop answering? How does it know it has given a good enough answer? How does it stop talking?
Two scenarios can make the model stop generating: ‘EOS tokens’ (<|endoftext|>) and ‘Maximum Token Lengths.’ We will learn about them, but we must first take a small detour to learn more about tokens and GPT’s generation process…
Tokens
LLMs don’t see words. They have never seen a word. What they see are called tokens. In the context of LLMs like GPT-4, tokens are not strictly whole words; they can also be parts of words, common subwords, punctuations or even parts of images like pixels. For example, the word “unbelievable” might be split into tokens like “un”, “believ”, and “able.” We break them down into familiar components based on how often they are repeated in the training data, which we call the tokenization process

But we still have words, and models don’t know words… We need to transform them into numbers so that the model can do math operations on them, as it has no clue what a word is. It only knows about bits and numbers. Here, we use what we call a model dictionary. This dictionary is basically just a huge list of all possible tokens that we have decided at the precedent step. We can now represent our words into numbers by simply taking their indices in our dictionary. By the way, Karpathy made an amazing video covering the whole tokenization process from scratch if you’d like to learn more about it.

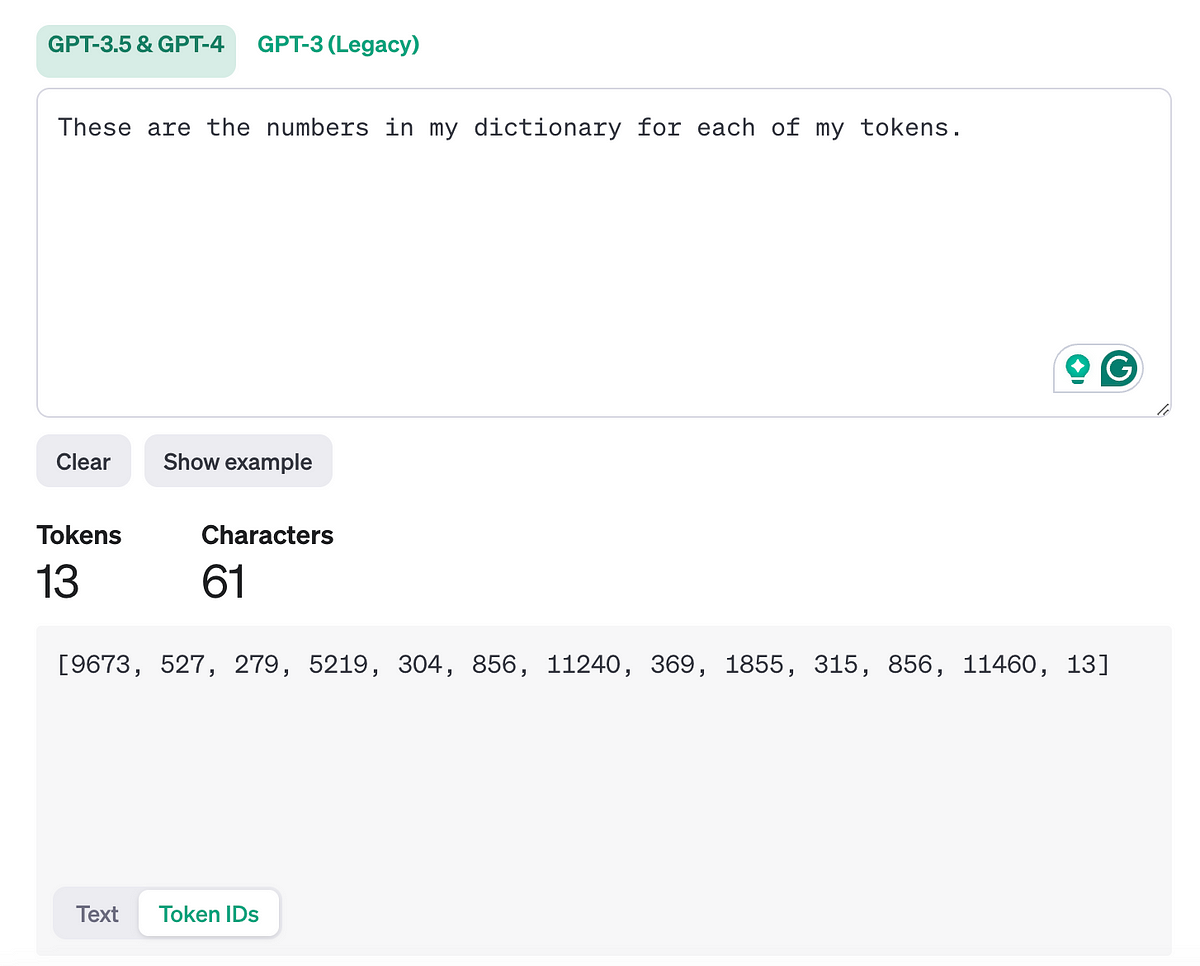
This tokenization process has two reasons. First, splitting words into common words helps reduce the model’s vocabulary size, which makes processing more efficient. Second, it allows the model to generate and interpret text at a more granular level, enhancing its ability to understand and produce nuanced language.
The generation process
We now have our question transformed into a list of tokens. But what does GPT-4 do with these tokens? It uses them to generate one new token at a time and does so statistically. This means it will generate the next token or word that makes the most sense based on all that was sent and generated previously.
If you ask why you should subscribe to the channel, it will answer based on what makes most sense from its training data, here the internet, which in this case seems to be by giving a list of reasons to subscribe.

So there are a couple of things here to understand:
First, the model started generating words that would make the most sense, reformulating the question as we’ve seen in school and following up with “for several reasons” and a colon (“:”). This is because, in its training data, most questions similar to this one were answered with such bullet lists, so it just copied this style.
What’s funny is that it doesn’t think like us. It works the other way around. We think about the question and figure out that we should probably give a bullet list of a couple of reasons to subscribe and then enumerate them. In GPT’s case, it already started generating its response without this mental plan of what to answer. When it generated this colon mark, it figured, “damn, I just said I’d give several reasons and put a colon; I should probably now start enumerating things!” and so it starts.
But then, how did it know how many bullet points to generate and finish generating? Remember, there’s no plan. It’s just creating one word at a time based on all previous ones. It doesn’t know what’s to come and when it has properly answered, so it should stop typing. That’s what we are going to answer now…
As we’ve said, there are two potential scenarios for making a model stop generating…
Scenario 1: The EOS (End-of-Text) Token
The first scenario is the usual one. When it has answered your question, this is thanks to a special token called EOS, or <|endoftext|>. GPT-4, like many large language models, uses this special token to determine when to stop generating text. Imagine teaching a child to recognize the end of a chapter in a book. When it sees phrases like “to conclude” or “to recap”, the child will assume we are towards the end. Well, that’s similar to how GPT-4 learns to stop generating text.
During its training, each piece of text typically concludes with an EOS token, effectively teaching the model to recognize this as a natural stopping point and the text before it, leading to this ending — just like the final dot of a chapter, if you’d like. For instance, when you ask a simple question like ‘What is the capital of France?’, the model generates a response and then places the EOS token right after ‘Paris,’ signalling the completion of the answer.
It’s as simple as that. During training, all of the examples we give it have this EOS token at the end. It essentially learns to stop generating by itself based on its training data. Nothing else. There’s no given length, no maximum, no minimum. It all works thanks to how we trained it, and this special EOS token, which is just like any other punctuation mark to it, just another number, but this one is just for the model to know it is over.
This leads us to our second scenario making it stop generating: What if we ask it to be more brief or more detailed, or manually set the token length limit on OpenAI’s platform?
Scenario 2: Maximum Token Length
When you set a maximum token limit or ask for it textually, GPT-4 uses its extensive training on texts of various lengths to gauge how to distribute content appropriately within this constraint. For instance, if you ask the model to explain a complex concept like quantum mechanics briefly, it plans its response to convey the most critical information before reaching the token limit, often utilizing an introductory sentence followed by key points, ensuring clarity and brevity.

Again, that’s because it’s how humans generate concise summaries or build clear and dense PowerPoints. However, if the question is too broad or complex relative to the token limit, the model might end up providing an answer that feels incomplete, like this one.

As we see, it’s not always perfect, but it keeps on improving. Pretty straightforward and feels like magic, right? It’s just all based on teaching these machines to imitate human-like interactions and answering as we would given the same context thanks to amazing engineering works and curated training data. Nothing magic, nothing too fancy. It’s pure mimicking, statistics, and one important token telling it’s time to wrap.
<|endoftext|>