How OpenAI Reduces risks for DALL·E 2
DALL·E 2 Pre-Training Mitigations


Watch the video
You’ve all seen amazing-looking images like these, entirely generated by an artificial intelligence model. I covered multiple approaches on my channel, like Craiyon, Imagen, and the most well-known, Dall-e 2.

Most people want to try them and generate images from random prompts, but the majority of these models aren’t open-source, which means we, regular people like us, cannot use them freely. Why? This is what we will dive into in this article.
I said most of them were not open-source.
Well, craiyon is, and people have generated amazing memes using it.

You can see how such a model can become dangerous: allowing anyone to generate anything. Not only for the possible misuses regarding the generations but also for the data used to train such models, coming from random images on the internet, pretty much anything, with questionable content and producing some unexpected images. This training data could also be retrieved through inverse engineering of the model, which is most likely unwanted.
OpenAI also used this to justify not releasing the Dall-e 2 model to the public. Here, we will look into what they are investigating as potential risks and how they are trying to mitigate them. I’ll go through an article they wrote covering their data pre-processing steps when training Dall-e 2.
So what does OpenAI really have in mind when they say that they are making efforts to reduce risks?
First, and the most obvious one, is that they are filtering out violent and sexual images from the hundreds of millions of images on the Internet. This is to prevent the model from learning how to produce violent and sexual content or even return the original images as generations.
It’s like not teaching your kid how to fight if you don’t want him to get into fights. It might help, but it’s far from a perfect fix! Still, I believe it is necessary to have such filters in our datasets, and definitely helps in this case.
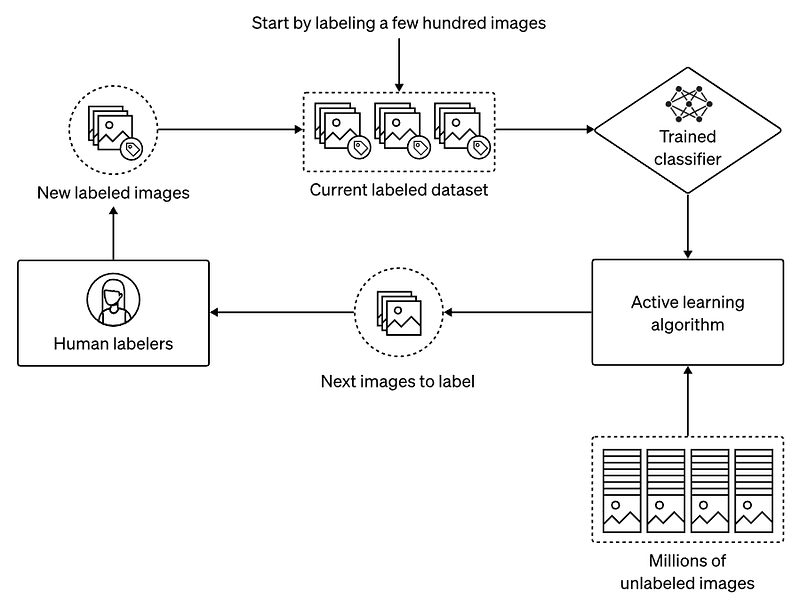
But how do they do that exactly? They build several models trained to classify data to be filtered or not by giving them a few different positive and negative examples and iteratively improve the classifiers with human feedback. Each classifier went through our whole dataset deleting more images than needed, just in case, as it is much better for the model to not see bad data in the first place rather than trying to correct the shot afterward. Each classifier will have a unique understanding of which content to filter and will all complement themselves, ensuring good filtering. If by good, we mean no false negative images going through the filtering process.
Still, it comes with downsides. First, the dataset is clearly smaller and may not accurately represent the real world, which may be good or bad depending on the use case. They also found an unexpected side-effect of this data filtering process: it amplified the model’s biases towards certain demographics. Introducing the second thing OpenAI is doing as a pre-training mitigation: reduce the biases caused by this filtering.

For example, after filtering, one of the biases they noticed was that the model generated more images of men and fewer of women compared to models trained on the original dataset. They explain that one of the reasons may be that women appear more often than men in sexual content — which may bias their classifiers to remove more false positive images containing women from the dataset, creating a gap in the gender ratio that the model observes in training and replicates.
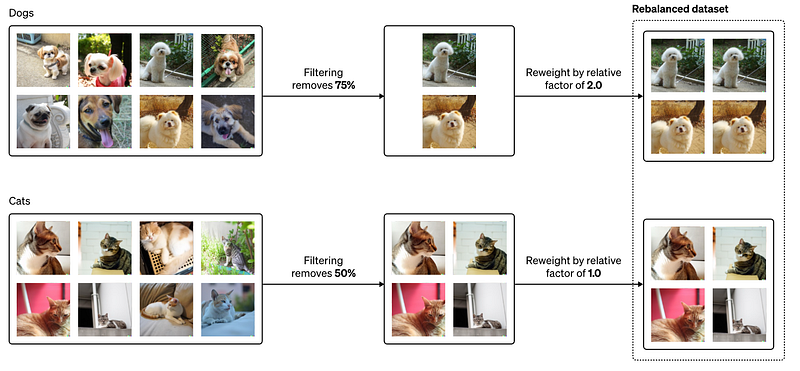
To fix that, they re-weight the filtered dataset to match the distribution of the initial pre-filter dataset. Here’s an example they cover using cats and dogs where the filter would remove more dogs than cats, so the fix would be to double the training loss for images of dogs, which would be like sending two images of dogs instead of one and compensating for the lack of images. This is once again just a proxy for actual filtering bias, but it still reduces the image distribution gap between the pre-filtered and the filtered dataset.
The last issue is an issue of memorization, something the models seem to be much more powerful than I am. As we said, it is possible to regurgitate the training data from such image generation models, which is not wanted in most cases. Here, we also want to generate novel images and not simply copy-paste images from the internet.
But how can we prevent that? Just like our memory, you cannot really decide what you remember and what goes away. Once you see something, it either sticks, or it doesn’t.
They found that, just like humans learning a new concept, if the model sees the same images numerous times in the dataset, it may accidentally know it by heart at the end of its training and generate it exactly for a similar or identical text prompt.
This one is an easy and reliable fix: just find out which images are too similar and delete the duplicates. Easy? Hmm, doing this would mean comparing each image with every other image, meaning hundreds of quadrillions of image pairs to compare. Instead, they simply start by grouping similar images together and then compare the images with all other images within the same and a few other clusters around it, immensely reducing the complexity while still finding 97% of all duplicate pairs.
Again, another fix to do within the dataset before training our Dall-e model.
OpenAI also mentions some next steps they are investigating, and if you’ve enjoyed this article, I definitely invite you to read their in-depth article to see all the details of this pre-training mitigation work. It is a very interesting and well-written article.
Let me know what you think of their mitigation efforts and their choice to limit the model’s access to the public. Leave a comment or join the discussion in our community on Discord!
Thank you for reading until the end!
I will see you next week with another amazing paper,
Louis
References
- OpenAI’s article: https://openai.com/blog/dall-e-2-pre-training-mitigations/
- Dalle 2 video: https://youtu.be/rdGVbPI42sA
- Craiyon’s video: https://youtu.be/qOxde_JV0vI
- Use Craiyon: https://www.craiyon.com/