

Watch the video
Text-to-Image models like DALLE or stable diffusion are really cool and allow us to generate fantastic pictures with a simple text input. But would it be even cooler to give them a picture of you and ask it to turn it into a painting? Imagine being able to send any picture of an object, person, or even your cat, and ask the model to transform it into another style like turning yourself into a cyborg of into your preferred artistic style or adding it to a new scene.

Basically, how cool would it be to have a version of DALLE we can use to photoshop our pictures instead of having random generations? Having a personalized DALLE, while making it much more simple to control the generation as “an image is worth a thousand words”. It would be like having a DALLE model that is just as personalized and addictive as the TikTok algorithm.
Well, this is what researchers from Tel Aviv University and NVIDIA worked on. They developed an approach for conditioning text-to-image models, like stable diffusion I covered last week, with a few images to represent any object or concept through the words you will send along your images. Transforming the object of your input images into whatever you want.

Examples from the paper.
Of course, the results still need work, but this is just the first paper tackling such an amazing task that could revolutionize the design industry. As a fantastic YouTuber colleague would say: just imagine two more papers down the line.
So how can we take a handful of pictures of an object and generate a new image following a text-conditioned input to add the style or transformation details?
To answer this complex question, let’s have a look at what Rinon Gal and his team came up with. The input images are encoded into what they call a pseudo-word that you can then use within your text generation. Thus the paper name, “an image is worth one word”. But how do they get this pseudo-word and what is it?
They start with three to five images of a specific object. They also use a pre-trained text-to-image model (image below, right). In this case, they use latent diffusion, the model I covered not even a week ago which takes any kind of inputs like images or text and generates new images out of them. You can see it as a cooler and Open-Source DALLE. If you haven’t watched my video yet, you should pause this one, learn about this model and come back here. You’ll love the video and learn about the hottest architecture of the moment!
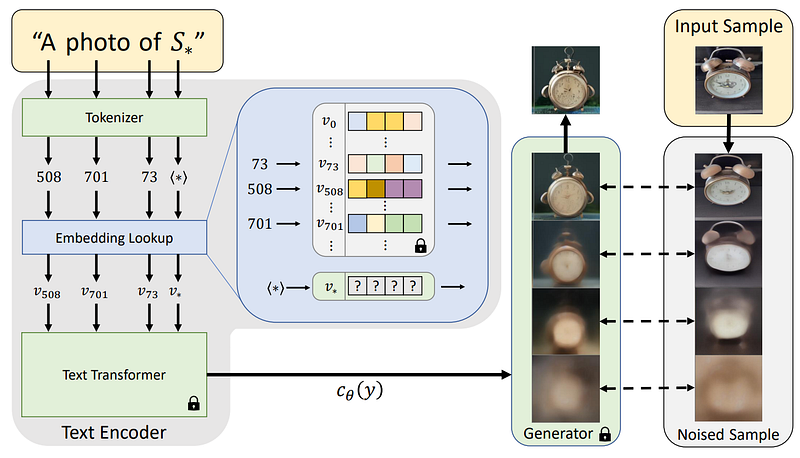
Overview of the model. (right) is the fixed pre-trained X-to-image generator and (left) the text encoder to be trained. Image from the paper.
So you have your input images and the base model for generating images conditioned on inputs such as text or other images. But what do you do with your 3–5 images of your object? And how do you control the model’s results so precisely that your object appears in the generations?
This is all done during the training process of your second model: the text encoder (image above, left). Using your pre-trained and fixed image generator model, latent diffusion in this case, already able to take a picture and reconstruct it, you want to teach your text encoder model to match your pseudo-word to your encoded images, or, in other words, your representations taken from your five images. So you will feed your images to your image generator network and train your text encoder in reverse to find out what fake words, or pseudo-word, would best represent all your encoded images.
Basically, find out how to correctly represent your concept in the same space as where the image generation process I described in my previous video happens. Then, extract a fake word out of it to guide future generations. This way, you can inject your concept into any future generations and add a few words to condition the generation even further using the same pre-trained text-to-image model. So you will simply be training a small model to understand where your images lie in the latent space to convert them into a fake word to use in the regular image generation model. You don’t have to touch the image generator model, and that’s quite a big deal considering how expensive they are to train!
And voilà! This is how you can teach a DALLE-like model to generate image variations of your preferred object or perform powerful style transfers.

Examples from the paper.
Of course, this is just an overview of this new method tackling a very very interesting task and I invite you to read their paper linked below for a deeper understanding of the approach and challenges.
It’s a very complicated task and there are still a lot of limitations like the time it takes to understand such a concept in a fake word, which is roughly 2 hours. It is also not yet capable of completely understanding the concept but is pretty damn close. There are also a lot of risks in having such a product accessible that we need to consider. Imagine being able to embed the concept of a specific person and generate anything involving the person. This is quite scary and this kind of technology is just around the corner. I’d love to hear your thoughts in the comments section or discuss this on our Discord server.
Thank you for reading and I will see you next week with another amazing paper!
References
►Paper: Gal, R., Alaluf, Y., Atzmon, Y., Patashnik, O., Bermano, A.H., Chechik, G. and Cohen-Or, D., 2022. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. https://arxiv.org/pdf/2208.01618v1.pdf
►Code: https://textual-inversion.github.io/
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/