

Key takeaways
- But first, we also need some “context” to understand what they did.
- They have shown using the Infini-attention mechanism performs even better the more context we give it, instead of worsening the results.
- The bigger window you can have, the more words you can send, the more context it can grasp and thus.
Watch the full video
Context window. These two words might have been the most sought-after and anticipated in large language model research papers and announcements by OpenAI, Anthropic, or Google. Well, thanks to Google’s most recent paper called Infini-attention, context windows are no longer a problem. Let’s see how they accomplished this. But first, we also need some “context” to understand what they did.

Infini-attention paper image.
Context window is a fancy way of saying how many words you can send to an LLM simultaneously. The bigger window you can have, the more words you can send, the more context it can grasp and thus, the better the understanding of your question will be to give an appropriate answer.
We want to send the model as much information as possible and let it figure out how best to meet our needs. The problem is that the language models’ performances dramatically decrease along with the context increases. Often time, the more words it sees, the worse the results. If you give GPT-4 a book page and ask a question about a character you know is present on the page, it will answer perfectly. But if you give it the whole book, it might not be able to understand the question. The model is basically overwhelmed. I guess it’s the same for us. Imagine having to study a whole book for an exam, and the first question expects you to remember a very specific detail on page 24. It’s quite a complex task!
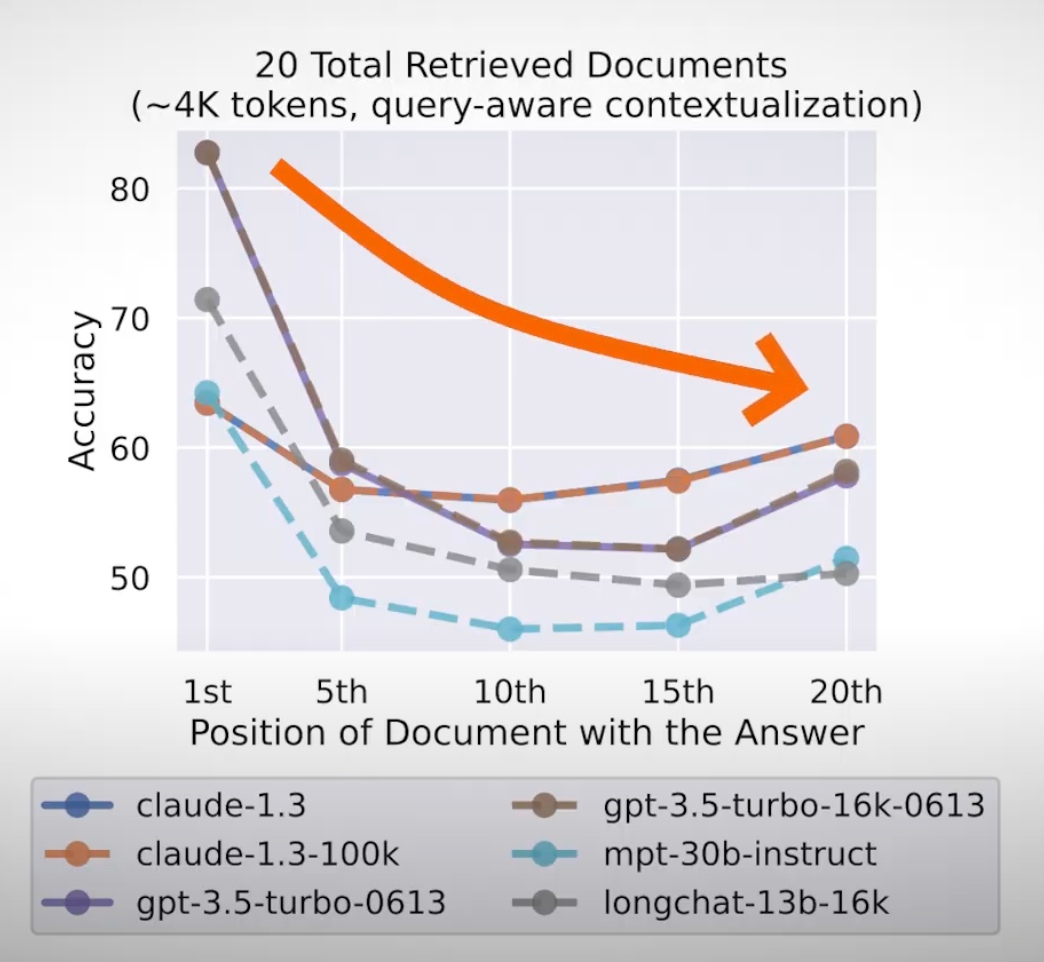
Performance degrades significantly when models must access and use information located in the middle of its input context. Image from the Lost in the Middle paper.
The model is just overwhelmed with too much information and lots of useless information. The key insights are diluted with tons of irrelevant pages. Plus, it needs to process all that extra information for nothing! This costs actual money through GPU memory. Not only that, but models like GPT-4 actually have a hard limit on the number of words based on the implementation of the model’s architecture, especially for the attention mechanism, that we covered numerous times on the channel. Plus, the model might not have been trained to see so much data in one go. So it can give its attention to a few words or sentences (pun intended), but a whole book might be too much. It might just be used for a couple of sentences. It’s just like giving a thousand-word book to a kid who used to read comics.

Attention visualized.
The attention mechanism is one of the main blockages to increasing the context window of our language models. This type of network layer allows us to understand the context between our words. It will learn the relationships between words to understand if we are talking about an actual bank or the side of a river. Through millions of sentence examples like this, this attention mechanism will learn to take the proper context from sentences to understand each of the word’s meanings. For example, here to focus on the fact that someone is sitting on this bank, which might be doable but complicated for an actual bank. Even harder if we are talking about a ‘bank of words’!


Words vs. tokens.
So, the more we expand that sentence, the harder the task becomes and the more computation we need as we compare each word with all others. By the way, for simplicity, I refer to words here, but it actually works with tokens, which are just number representations of our words, or rather parts of words, to make this comparison mathematically possible. Since we are intelligent beings, we get that through the context of the sentence, but as a machine, it has to calculate it with vectors and math.
This math is hard to do in a split second super efficiently, especially if we expand the text to a book or even multiple textbooks. Well, Google made the use of the attention mechanism much more manageable for such large contexts of millions of words thanks to their new paper and approach: Infini-attention.

Infini-attention modifies the standard attention mechanism by dividing the calculation into two distinct parts: one for local information, focusing on nearby words, and another for long-range relations, connecting words that are significantly farther apart in the text.
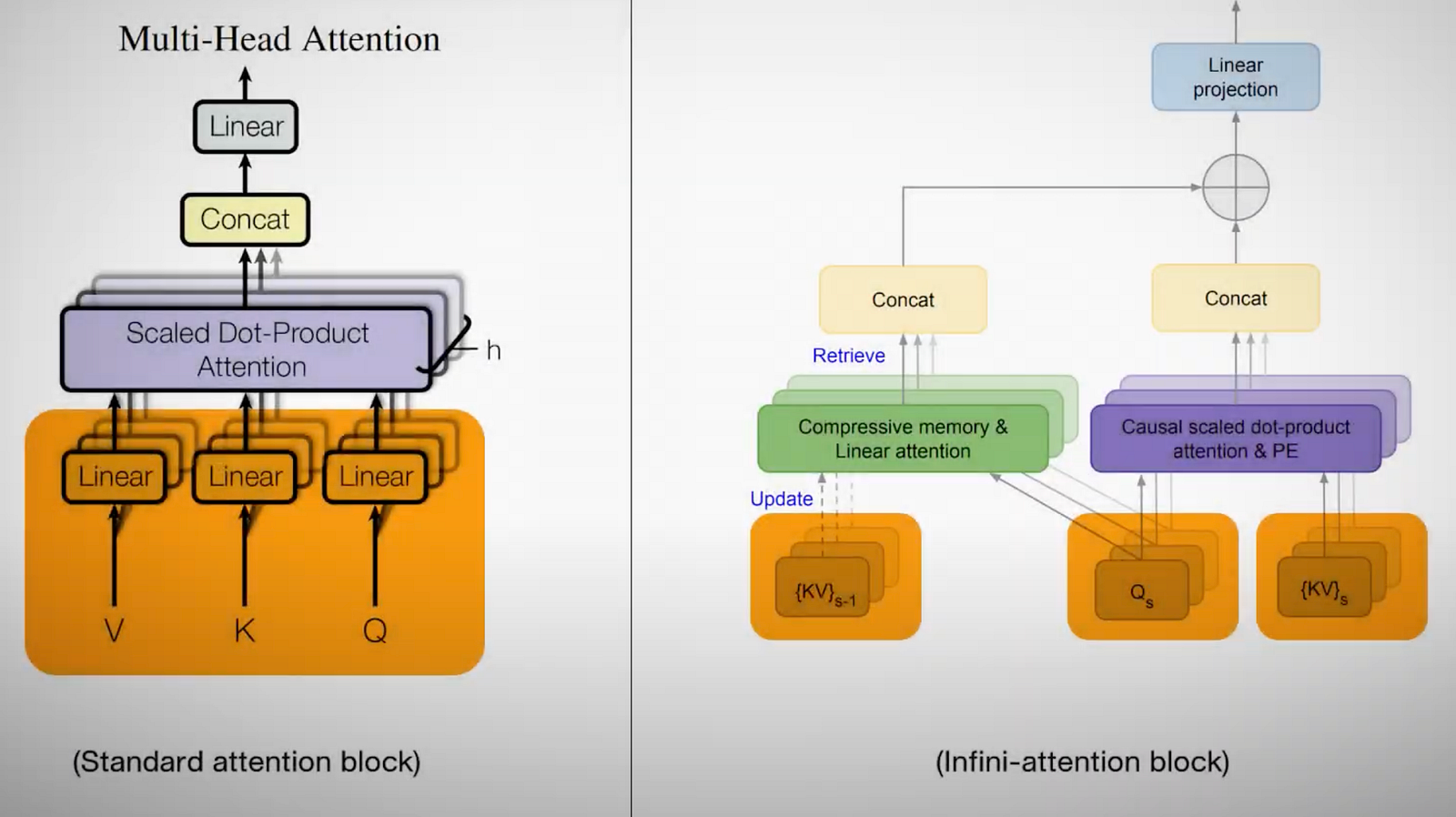
Attention process (left) and the infinite-attention process (right) with a distinct attention block for long and short ranges. Image adapted from the Lost in the Middle paper.
A major enhancement of this model is its ability to transform the computational cost from quadratic to linear with respect to sequence length. This is achieved through key modifications to the attention mechanism, including the introduction of compressive memory.
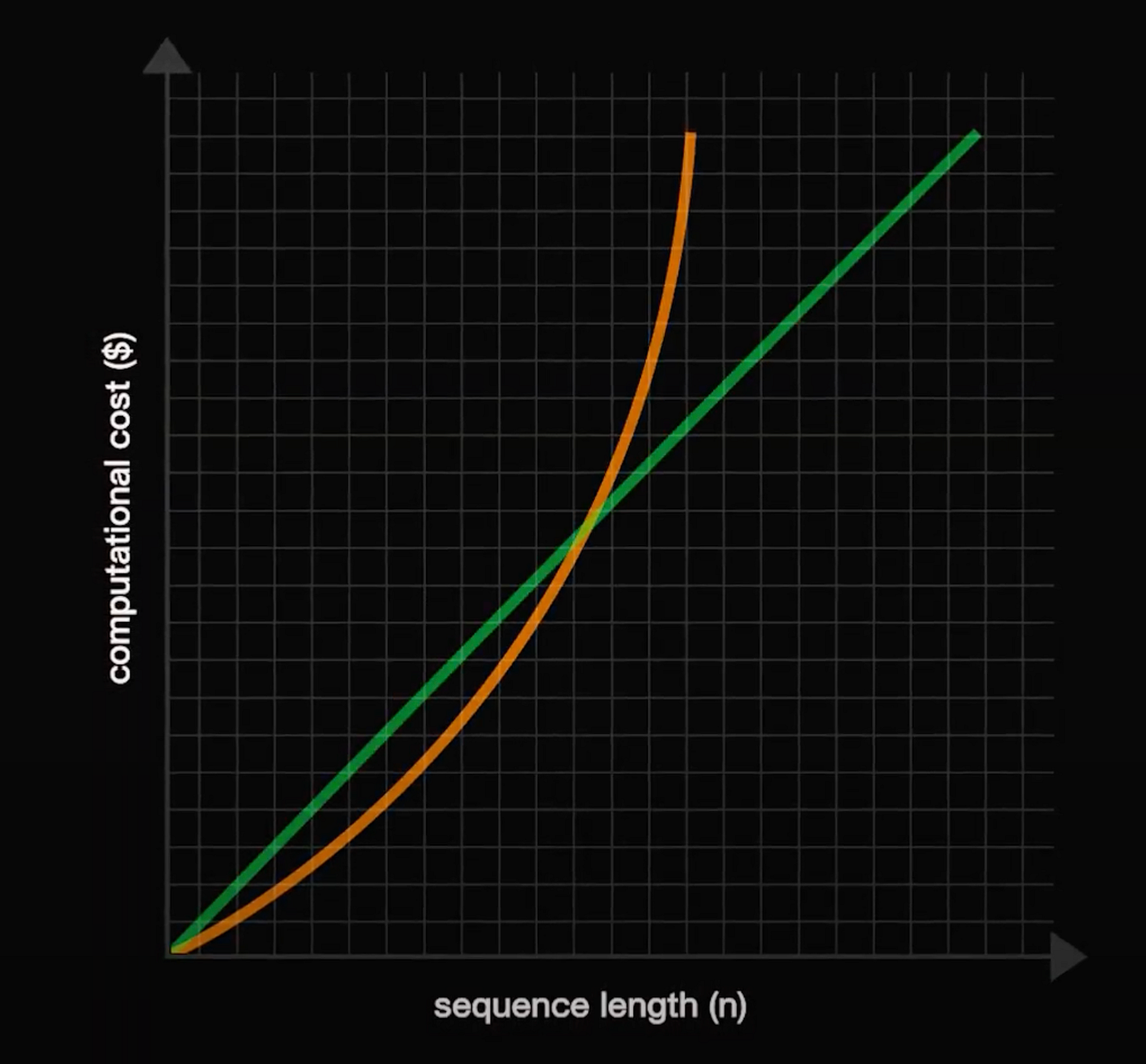
Quadratic (orange) vs. linear (green) lines.
Initially, Infini-attention processes text in segments rather than the entire context simultaneously, calculating local attention within these individual segments.
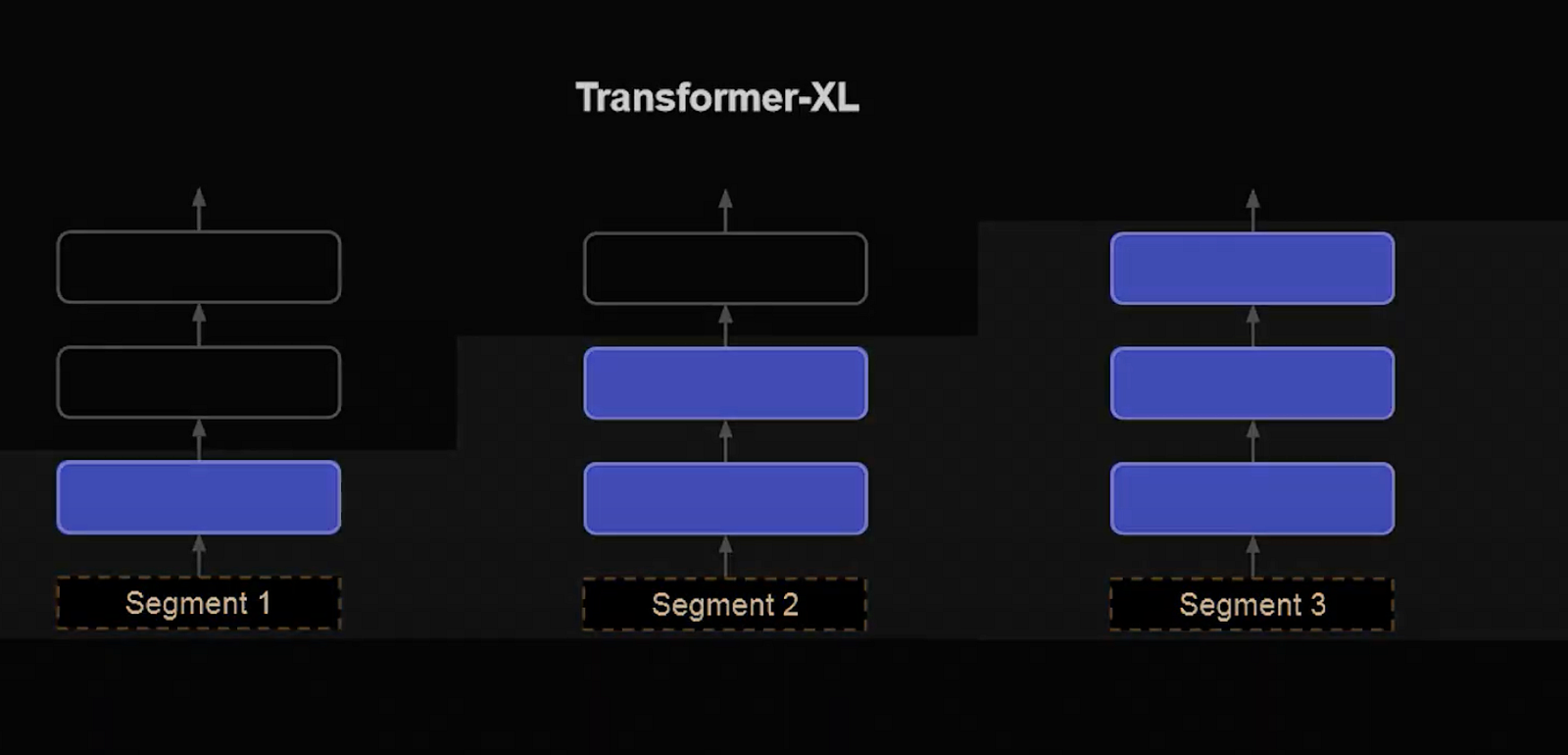
Original Transformer-XL sequencing for long inputs.
Beyond merely processing individual segments, the model compresses information from past segments into a memory state, readily accessible for future needs. This method enables the efficient integration of long-range context into each local calculation, which significantly enhances scalability and density of data processing.
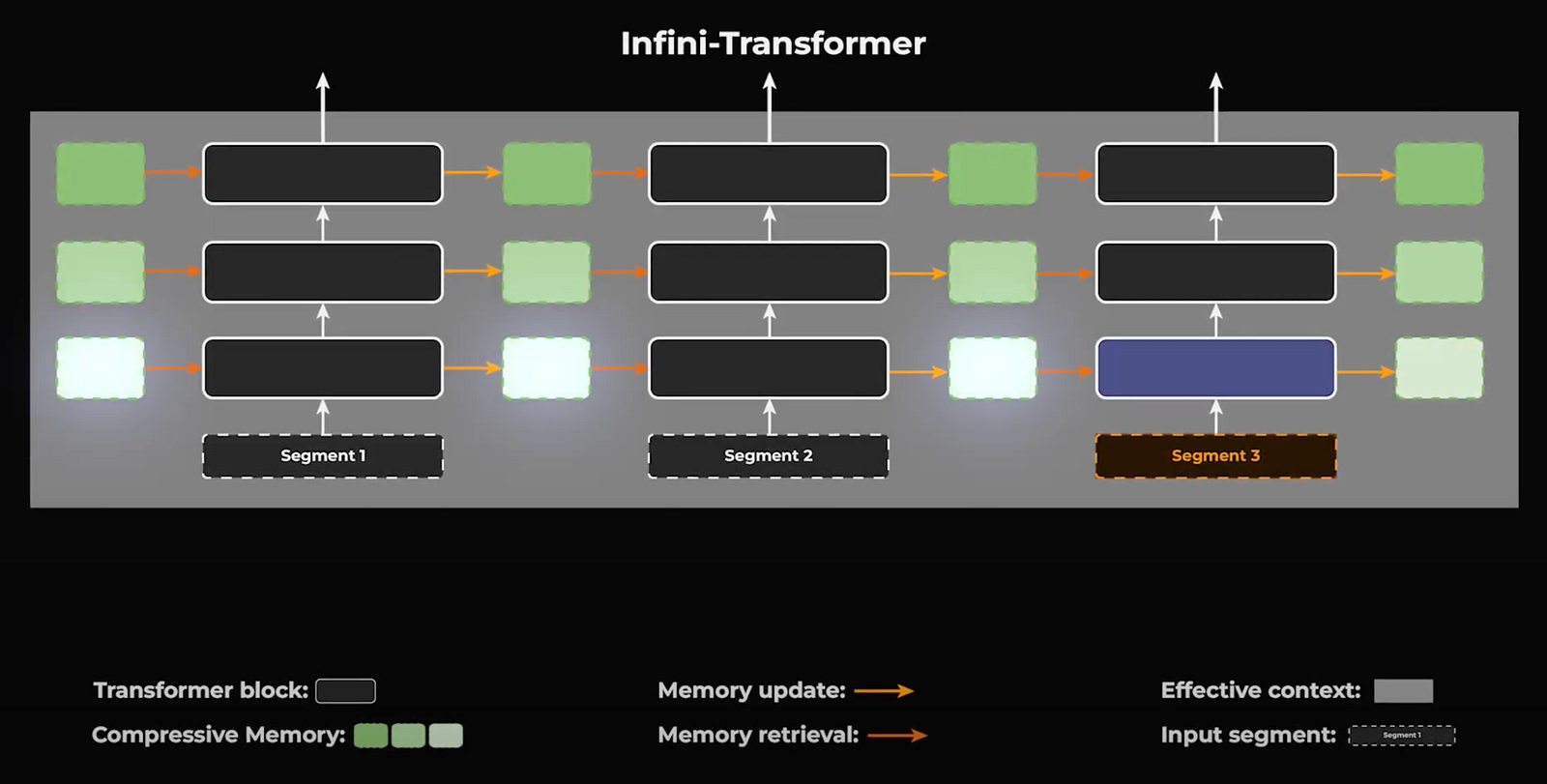
Infini-Transformer sequencing for long inputs with compressive memory updates and retrieval.
This approach means that instead of continually recalculating the relevance of older data every time new input is processed, the model efficiently stores this information in a compressed form. When the context from these past segments becomes relevant again, the model can quickly retrieve it from this compressed memory state. Thus, when the model processes a new segment of text, it does not start from scratch. It retrieves relevant information from the compressive memory states based on the current input queries, pulling the most pertinent historical data to the forefront. This ensures that even distant but relevant details are considered in every new step.
After processing each segment, the model updates its memory states, incorporating new data and selectively discarding less pertinent information. This keeps the memory efficient and manageable, optimizing both performance and resource utilization.
And voilà! By managing memory in this way, Infini-attention achieves a balance between depth of context and computational efficiency, which is crucial for tasks involving large volumes of text or where historical context significantly influences current decisions.
They have shown using the Infini-attention mechanism performs even better the more context we give it, instead of worsening the results.
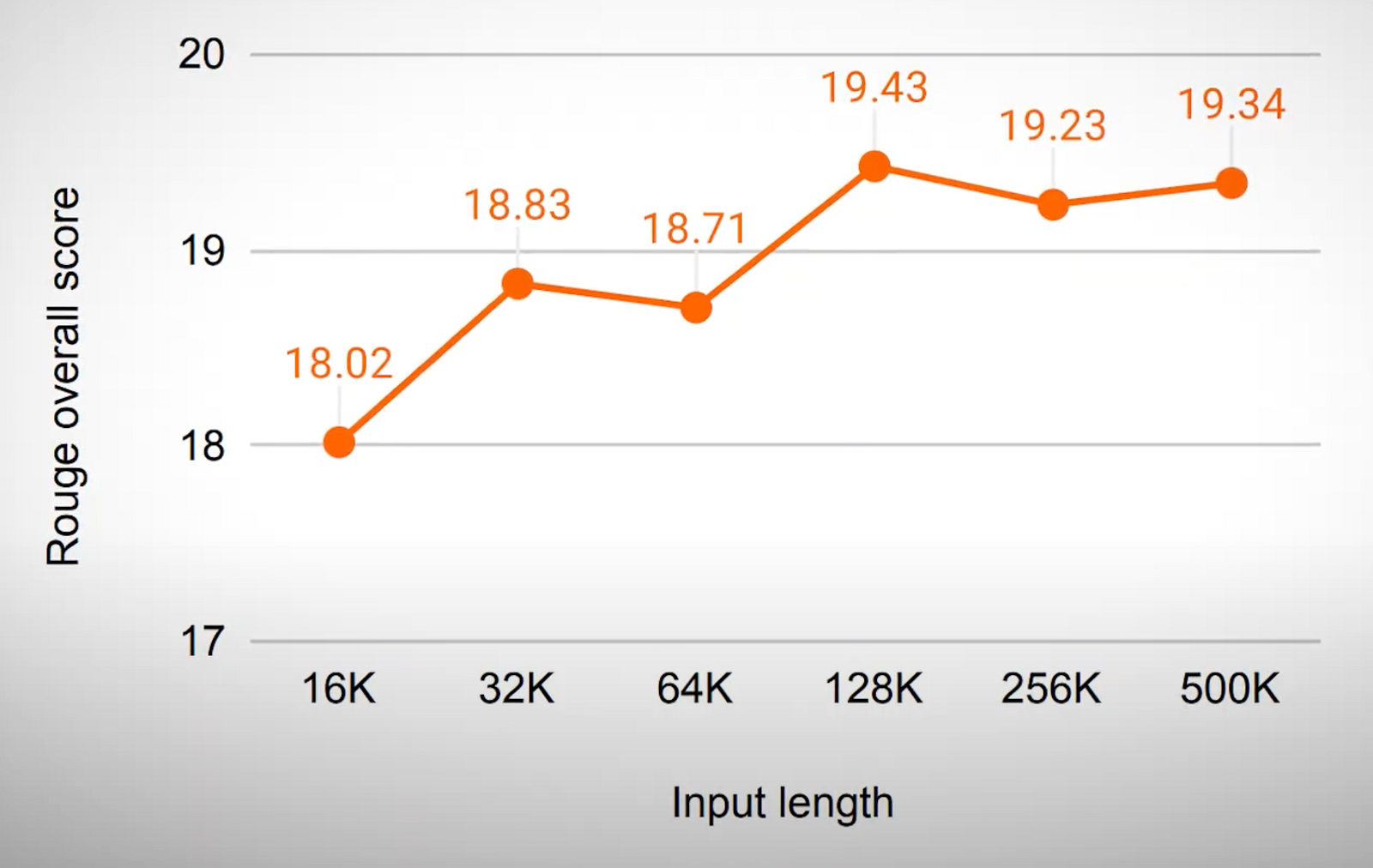
Infini-attention model result w.r.t. input length. Image adapted from the Lost in the Middle paper.
In short, this is a very important work that allows us to give more information to our language model, like full textbooks, so that they give us better and more appropriate answers, which means we work less and less and lose brain cells! Pretty cool, right? I’m just kidding. Well, I hope that I’m kidding and it won’t happen…
Of course, this was just an overview video about this exciting new research paper and approach. The paper is called Leave No Context Behind. I definitely invite you to read it and learn more about this mechanism and language models in general; it’s a very interesting read.
Thank you for reading the whole article, and I will see you in the next one!
FAQ
What is the useful lesson from Google's Infini-Attention?
Infinite Context Window?! But first, we also need some “context” to understand what they did.
What should builders do with google's Infini-Attention?
They have shown using the Infini-attention mechanism performs even better the more context we give it, instead of worsening the results.
What is the hype trap with google's Infini-Attention?
The problem is that the language models’ performances dramatically decrease along with the context increases.
How should builders use google's Infini-Attention?
The bigger window you can have, the more words you can send, the more context it can grasp and thus, the better the understanding of your question will be to give an appropriate answer.
When does google's Infini-Attention become useful in practice?
In short, this is a very important work that allows us to give more information to our language model, like full textbooks, so that they give us better and more appropriate answers.
What should beginners understand about google's Infini-Attention?
Context window is a fancy way of saying how many words you can send to an LLM simultaneously.
What is the common mistake with google's Infini-Attention?
The problem is that the language models’ performances dramatically decrease along with the context increases.