Infinite Nature: Fly into an image and explore the landscape
The next step for view synthesis: Perpetual View Generation, where the goal is to take an image to fly into it and explore the landscape!


(optional) You can watch the video about this article at the end!
This week's paper is about a new task called "Perpetual View Generation," where the goal is to take an image to fly into it and explore the landscape. This is the first solution for this problem, but it is extremely impressive considering we only feed one image into the network, and it can generate what it would look like to fly into it like a bird. Of course, this task is extremely complex and will improve over time. As two-minute papers would say, imagine in just a couple of papers down the line how useful this technology can be for video games or flight simulators!
I'm amazed to see how well it already works, even if this is the paper introducing this new task. Especially considering how complex this task is. And not only because it has to generate new viewpoints like GANverse3D is doing, which I covered in a previous article, but it also has to generate a new image at each frame, and once you pass a couple of dozen frames, you will have close to nothing left from the original image to use. And yes, this can be done over hundreds of frames while still looking a lot better than current view synthesis approaches.
Let's see how they can generate an entire bird-view video in the wanted direction from a single picture and how you can try it yourself right now without having to set up anything!
To do that, they have to use the geometry of the image, so they first need to produce a disparity map of the image. This is done using a state-of-the-art network called MiDaS, which I will not enter into, but this is the output it gives. This disparity map is basically an inverse depth map, informing the network of the depths inside the scene.
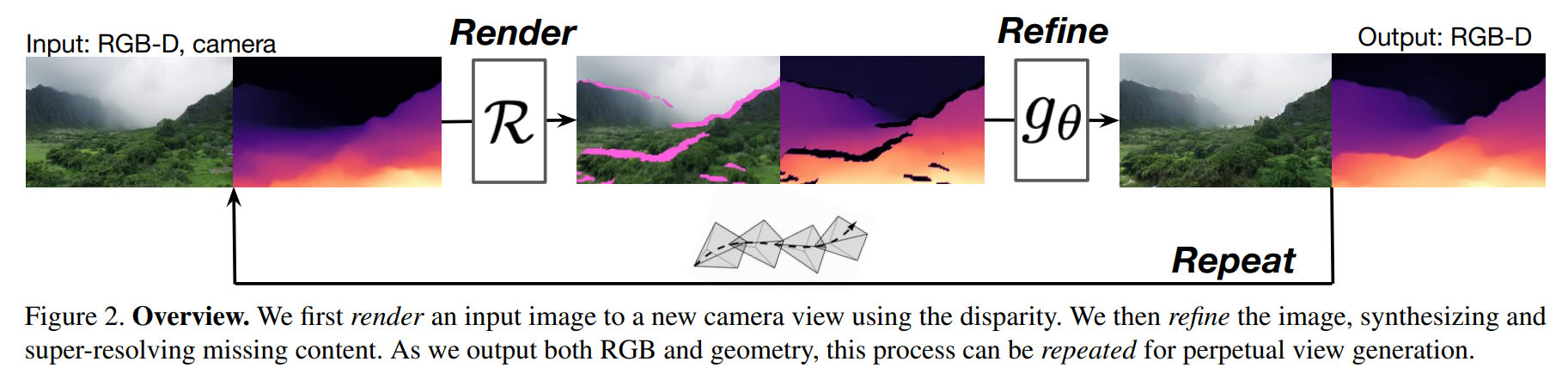
Then, we enter the real first step of their technique, which is the renderer.
The goal of this renderer is to generate a new view based on the old view.
This new view will be the next frame, and as you understood, the old view is the input image. This is done using a differentiable renderer. Differentiable just because we can use backpropagation to train it, just like we traditionally do with the conventional deep nets, you know. This renderer takes the image and disparity map to produce a three-dimensional mesh representing the scene that you can see in figure 3 (left) below. Then, we simply use this 3D mesh to generate an image from a novel viewpoint, P1 in this case. This gives us this amazing new picture that looks just a bit zoomed, but it is not simply zoomed in. There are some pink marks on the rendered image and black marks on the disparity map, as you can see in figure 2 above. They correspond to the occluded regions and regions outside the field of view in the previous image used as input to the renderer since this renderer only generates a new view but is unable to invent unseen details. This leads us to quite a problem, how can we have a complete and realistic image if we do not know what goes there? Well, we can use another network that will also take this new disparity map and image as input to 'refine' it (figure 3, right).
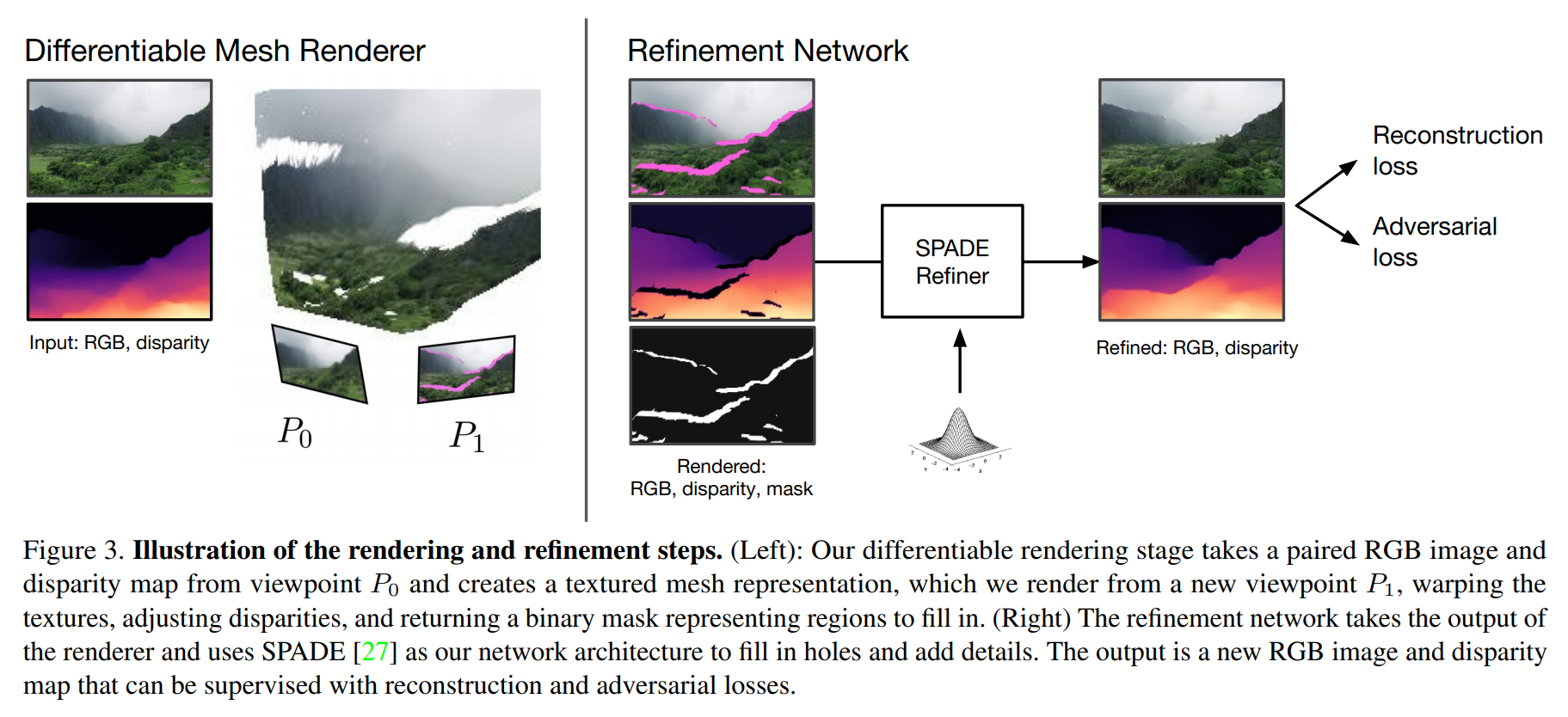
This other network (shown on the right) called SPADE is also a state-of-the network, but for conditional image synthesis. Here, it is a conditional image synthesis network because we need to tell our network some conditions, which in this case are the pink and black missing parts. We basically send this faulty image to the second network to fill in holes and add the necessary details. You can see this SPADE network as a GAN architecture where the image is first encoded into a latent code that will give us the style of the image. Then, this code is decoded to generate a new version of the initial image, simply filling the missing parts with new information following the same style present in the encoded information.
And voilà! You have your new frame and its reverse depth map. You can now simply repeat the process over and over to get all future frames, which now looks like this. Using this output as input in the next iteration, you can produce an infinity of iterations, always following the wanted viewpoint and the precedent frame context!
As you know, such powerful algorithms frequently need data and annotation to be trained on, and this one isn't the exception. To do so, they needed aerial footage of nature taken from drones, which they took from youtube, manually curated, and pre-processed them to create their own dataset. Fortunately for other researchers wanting to attack this challenge, you don't have to do the same thing since they released this dataset of aerial footage of natural coastal scenes used to train their algorithm. It is available for download on their project page, which is linked in the references below.
As I mentioned, you can even try it yourself as they made the code publicly available, but they also created a demo you can try right now on google colab. The link is in the references below. You just have to run the first few cells like this, which will install the code and dependencies, load their model, and there you go. You can now free-fly around the images they have and even upload your own! Of course, all the steps I just mentioned were already there.
Simply run the code and enjoy!
Watch more example in the video:
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
Paper: Liu, A., Tucker, R., Jampani, V., Makadia, A., Snavely, N. and Kanazawa, A., 2020. Infinite Nature: Perpetual View Generation of Natural Scenes from a Single Image, https://arxiv.org/pdf/2012.09855.pdf
Project link: https://infinite-nature.github.io/
Code: https://github.com/google-research/google-research/tree/master/infinite_nature
Colab demo: https://colab.research.google.com/github/google-research/google-research/blob/master/infinite_nature/infinite_nature_demo.ipynb#scrollTo=sCuRX1liUEVM
MiDaSL: Ranftl et al., 2020, Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer, https://github.com/intel-isl/MiDaS
SPADE: Park et al., 2019, Semantic Image Synthesis with Spatially-Adaptive Normalization, https://github.com/NVlabs/SPADE