

The short version
InfiniteNature-Zero generated a continuous landscape fly-through from one image without training on real videos or paired camera trajectories. The 2022 method sampled virtual camera paths, used a cyclic path back to the source for self-supervised reconstruction, and added adversarial training plus sky refinement. It improved long-range stability and geometric coherence over the earlier setup, while remaining focused on natural scenes.
Watch the video!
Have you ever imagined being able to take a picture and just magically dive into it as if it would be a door to another world?
Well, whether you thought about this or not, some people did, and thanks to them, it is now possible with AI! This is just one step away from teleportation and being able to be there physically. Maybe one day AI will help with that and fix an actual problem too! I’m just kidding, this is really cool, and I’m glad some people are working on it.
This is InfiniteNature… Zero! It is called this way because it is a follow-up on a paper I previously covered called InfiniteNature. What’s the difference? Quality! Just look at that. It is so much better in only one paper.
It’s incredible! You can actually feel like you are diving into the picture, and it only requires one input picture.
How cool is that?! The only thing even cooler is how it works… Let’s dive into it! *see more results in the video above!*
How does InfiniteNature-Zero work…

Learning perpetual view generation from single images. Image and caption from the paper.
It all starts with a single image you send as input. Yes, a single image. It doesn’t require a video or multiple views, or anything else. This is different from their previous paper that I also covered where they needed videos to help the model understand natural scenes during training, which is also why they called this model “InfiniteNature-Zero” because it requires zero videos. Here, their work is divided into three methods used during training in order to get those results…
To start, the model randomly samples two virtual camera trajectories, which will tell you where you are going in the image.
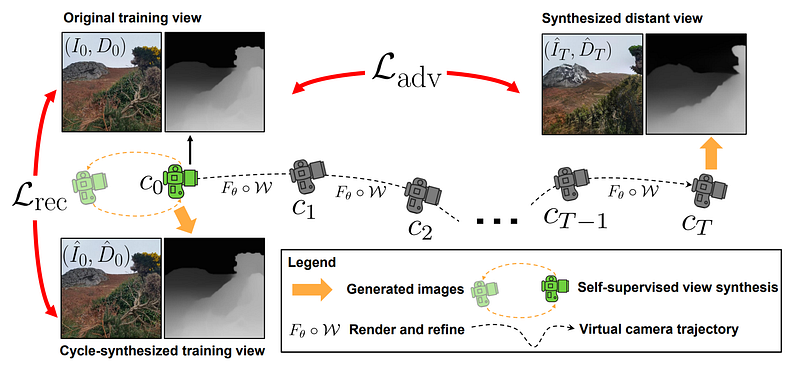
Overview of the approach. Image from the paper
Why two? Because the first is necessary to generate a new view, telling you where to fly into the image to generate a second image, this is the actual trajectory you will be taking.
The second virtual trajectory is used during training to dive and return to the original image to teach the model to learn geometry-aware view refinement during view generation, in a self-supervised way, as we teach it to get back to an image we have in our training dataset. They refer to this approach as a cyclic virtual camera trajectory, as the starting and ending views are the same: our input training image. They do that by going to a virtual or fake sampled viewpoint and returning to the original view afterward, just to teach the reconstruction part to the model. The viewpoints are sampled using an algorithm called the auto-pilot algorithm to find the sky and not skydive into rocks or the ground, as nobody would like to do that.
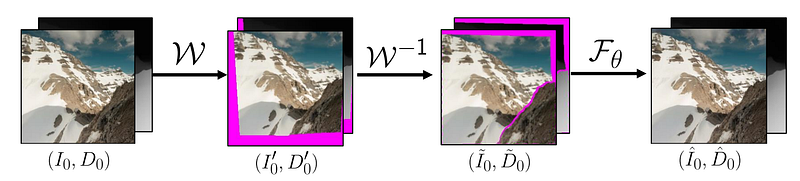
From left to right: input image; input rendered to a virtual “previous” view; virtual view rendered back to the starting viewpoint. Image and caption from the paper.
Then, during training, we use a GAN-like approach using a discriminator to measure how much the new view generated looks like a real image, represented with L_adv here. So yes, GANs aren’t dead yet! This is a very cool application of them for guiding the training when you don’t have any ground truth, for example, when you don’t have infinite images in this case. Basically, they use another model, a discriminator, trained on our training dataset that can say if an image seems to be part of it or not. So based on its answer, you can improve the generation to make it look like an image from your dataset, which supposedly looks realistic!
We also measure the difference between our re-generated initial image and the original one to help the model iteratively get better at reconstructing it, represented by L_rec here.
And we simply repeat this process multiple times to generate our novel frames and create these kinds of videos!
There’s one last thing to tweak before getting those amazing results. They saw that with their algorithm the sky, due to its infinite nature compared to the ground, changes way too quickly. To fix that, they use another segmentation model to find the sky automatically in the generated images and fix it using an intelligent blending between the generated sky and the sky from our initial image so that it doesn’t change too quickly and unrealistically. Another clue that AI isn’t really smart and needs a lot of manual tweaking!

After training with this 2-step process and sky refinement, InfiniteNature-Zero allows you to have stable long-range trajectories for natural scenes as well as accurately generate novel views that are geometrically coherent.
And voilà! This is how you can take a picture and dive into it as if you were a bird! I invite you to read their paper for more details on their method and implementation, especially regarding how they achieved to train their model in such a clever way as I omitted some technical details making this possible for simplicity.
By the way, the code is available and linked below if you’d like to try it! Let me know if you do and send me the results! I’d love to see them.
Thank you for reading and I hope you’ve enjoyed this article. I will see you next week with another amazing paper!
References
FAQ
How is InfiniteNature-Zero different from the earlier method?
It learns perpetual landscape generation from unpaired single images rather than requiring real camera-trajectory training videos.
What does the model generate from one picture?
It creates a long forward camera path with new views that remain visually and geometrically connected.
Why reconstruct the initial image during training?
Comparing the regenerated view with the source provides a learning signal for geometry and appearance.
What does sky refinement improve?
It stabilizes distant sky regions that otherwise reveal seams or drift during a long generated trajectory.
What is the main quality goal?
The generated views should remain stable, geometrically coherent, and plausible over a long virtual flight.