

Watch the video!
Have you ever tuned in to a video or a TV show and the sound was like this…
Where the actors are completely inaudible, or something like this…
Where the music is way too loud. Well, this problem, also called the cocktail party problem, may never happen again. Mitsubishi and Indiana University just published a new model as well as a new dataset tackling this task of identifying the right soundtrack. For example, if we take the same audio clip we just ran with the music way too loud, you can simply turn up or down the audio track you want to give more importance to the speech than the music.
The problem here is isolating any independent sound source from a complex acoustic scene like a movie scene or a youtube video where some sounds are not well balanced. Sometimes you simply cannot hear some actors because of the music playing or explosions or other ambient sounds in the background. Well, if you successfully isolate the different categories in a soundtrack, it means that you can also turn up or down only one of them, like turning down the music a bit to hear all the other actors correctly as we just did. From someone that isn’t a native English speaker, this would be incredibly useful when listening to videos with loud background music and actors or speakers with a strong accent I am not used to.
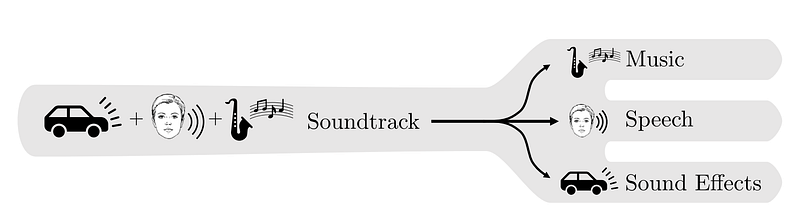
Separating a soundtrack into music, speech, and sound effects. Image from Petermann, D. et al., (2021).
Just imagine having these three sliders in a youtube video to manually tweak them. How cool would that be! It could also be incredibly useful for translations or speech-to-speech applications where we could just isolate the speaker to improve the task’s results.
Here, the researchers focused on the task of splitting a soundtrack into three categories: music, speech, and sound effects. Three categories that are often seen in movies or TV shows. They called this task the cocktail fork problem, and you can clearly see where they got the name from. And I will spoil you with the results: they are quite amazing, as we will hear in the next few seconds. But first, let’s look at how they receive a movie soundtrack and transform it into three independent soundtracks.
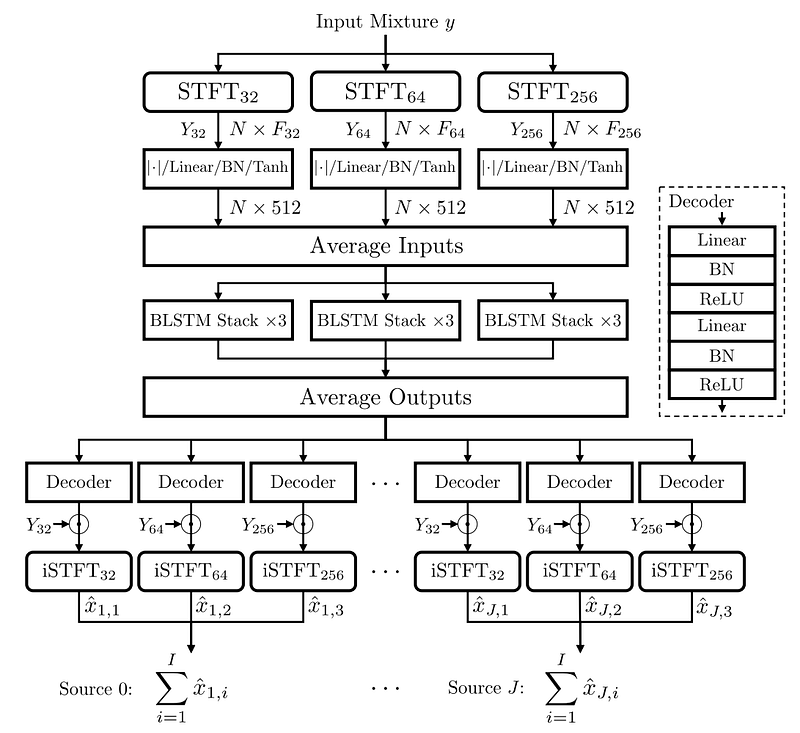
Overview of the model. Image from Petermann, D. et al., (2021).
This is the architecture of the model. You can see the input mixture y, which is the complete soundtrack at the top, and at the bottom, all of our three output sources, x. Which I repeat are the speech, music and other sound effects separated.
The first step is to encode the soundtrack using a Fourier transform on different resolutions called STFT or short-time Fourier transform. This means that the input, which is a soundtrack having frequencies over time, is first split into shorter segments. For example, here, it is either split with 32, 64, or 256 milliseconds windows.
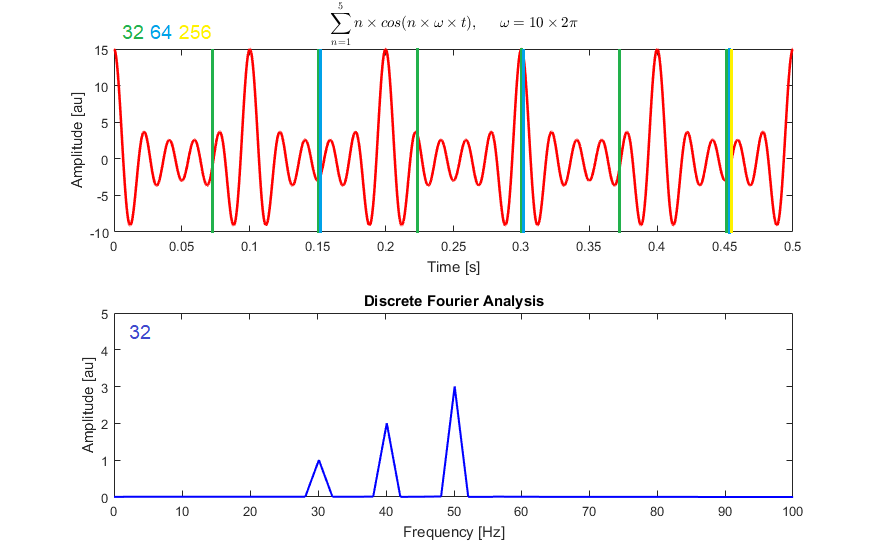
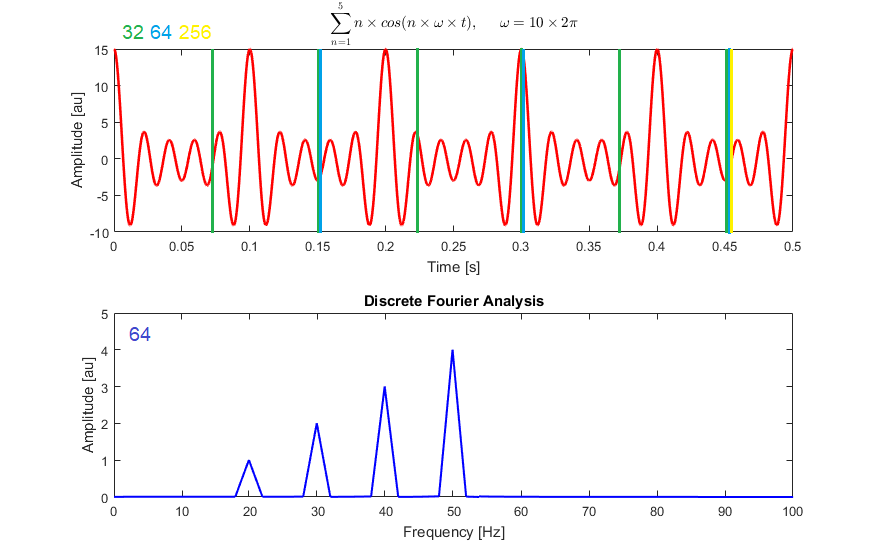
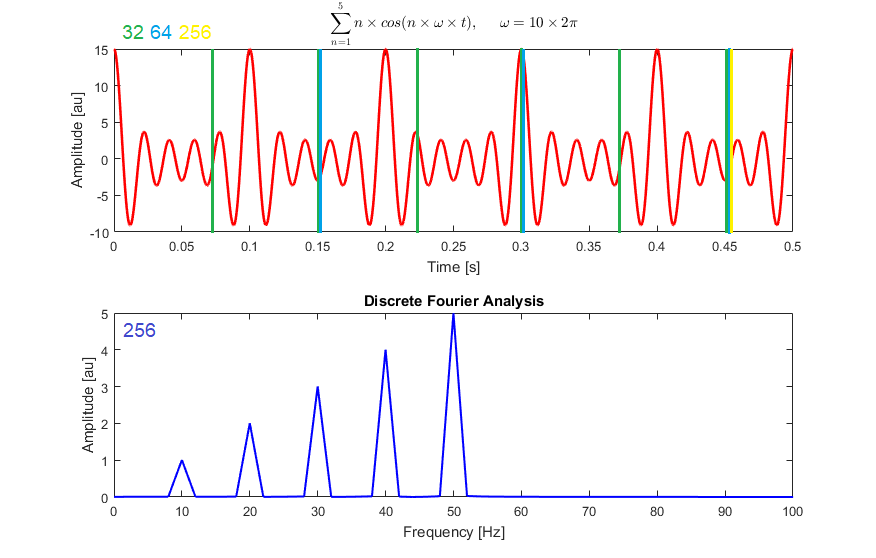
Then, we compute the Fourier transform on each of these shorter segments sending eight milliseconds at a time for each window or segment. This will give the Fourier spectrum of each segment analyzed on different segment sizes for the same soundtrack, allowing us to have short-term and longer-term information on the soundtrack by emphasizing specific frequencies from the initial input if they appear more often in a longer segment, for example. This information initially represented in time-frequency is now replaced by the Fourier phase and magnitude components, or Fourier spectrum, which can be shown in a spectrogram similar to this.
Short-time Fourier transform. Source: Wikipedia
Note that here we have only an overlapping segment of 0.10 seconds.
It is the same thing in our case but with three segments of different sizes also overlapping.
Then, this transformed representation simply containing more information about the soundtrack is sent into a fully connected block to be transformed into the same dimension for all branches. This transformation is one of the things learned during the training of the algorithm. We then average the results as it was shown to improve the model’s capacity to consider these multiple sources as a whole rather than independently. Here the multiple sources are the transformed soundtrack using differently sized windows.
Don’t give up yet; we just have a few steps left before hearing the final results!
This averaged information is sent into the bidirectional long short-term memory, which is a type of recurrent neural network allowing the model to understand the inputs over time, just like a Convolutional Neural Network understands images over space. If you are not familiar with recurrent neural networks, I invite you to watch the video I made introducing them. This is the second module that is trained during training.
We average the results again and finally send them to each of our three branches that will extract the appropriate sounds for each category. Here the decoder is simply fully connected layers again, as you can see on the right. They will be responsible for extracting only the wanted information from our encoded information. Of course, this is the third and last module that learns during training in order to achieve this. And all these three modules are trained simultaneously!
Finally, we just reverse the first step taking the spectrum data back into time-frequency components. And voilà, we have our final soundtrack divided into three categories!

As I said earlier in the video, this research allows you to turn up or down the volume of each category independently. But an example is always better than words, so let’s quickly hear that on two different clips…
As if it isn’t already cool enough, this separation also allows you to edit specific soundtracks independently to add sound filters or reverb…
They also released a dataset for this new task by merging three separate datasets, one for speech, one for music, and another for sound effects. This way, they created soundtracks from which they already had the real separated audio channels and could train their model to replicate this ideal separation. Of course, the merging or mixing step wasn’t as simple as it sounds. They had to make the final soundtrack as challenging as a real movie scene. This means that they had to make transformations to the independent audio tracks to have a good blend that sounds realistic in order to be able to train a model on this dataset and use it in the real world.
I invite you to read their paper for more technical detail about their implementation and this new dataset they introduced if you’d like to tackle this task as well. If you do so, please let me know and send me your progress. I’d love to see that! Or rather, to hear that! Both are linked in the references below.
Directly from my newsletter: The AI Ethics’ Perspective: the spam detector 2.0

From a philosophical standpoint, I think what’s relevant here is not the noise or the quality of the signal but the selective nature of attention.
Consider all audio signals we perceive every day. When we focus on something, our brain filters out what it takes for irrelevant, repetitive or boring. My geography teacher’s voice, for example, or literally everything out of my daydreaming when I was an adolescent in love.I started thinking our brain acts like a biological spam filter. Through adaptation and evolution, we fine-tuned the process for maximizing surviving chances. For example, we can easily distinguish particular sets of frequencies as the roars of predators or the cries of a baby and almost instantaneously fall into a state of alert when we hear a high volume, high pitch sound that resembles a scream. To what extent are we in control of the anti-spam measures? How accurate is it? Could we outsmart the process to make it more efficient for our times, goals and health?
What if we could smartly automatize the anti-spam process through a Brain-machine interface that can:
- filter or suppress the undesired audio signals just before neurotransmitters process them,
- amplify the otherwise inaudible signals?Volitional attention is deeply connected with consciousness and freedom. Being aware of what’s happening around us and inside us is crucial for our autonomy. Focusing for a long time in the pursuit of mastering some domain through practice, nonetheless, involves cultivating more profound freedom. Moreover, paying attention to someone proves our interest, respect, affection, and commitment.
Then, if we wanted to outsmart attention, who might decide what is worth attention and, maybe most importantly, what is not? And how?
Big Tech and Marketing experts know the value of attention; they are already adopting AI to grab and hold attention to the screen, and sounds are a relevant component. See advertising jingles and audio techniques.If this hypothesis became feasible, the human species would probably evolve into something else. Might it be the first step toward transhumanism? Or toward a no-surprises “Wall-E society” where our expectations are always met?
- Martina
Thank you very much for reading for those of you who are still here, and huge thanks to Anthony Manello, the most recent YouTube member supporting the videos I make!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon.
- Follow me here on my blog or on medium.
- Want to get into AI or improve your skills, read this!
- Learn AI together, join our Discord community, share your projects, papers, best courses, find Kaggle teammates, and much more!
References
- Petermann, D., Wichern, G., Wang, Z., & Roux, J.L. (2021). The Cocktail Fork Problem: Three-Stem Audio Separation for Real-World Soundtracks. https://arxiv.org/pdf/2110.09958.pdf
- Project page: https://cocktail-fork.github.io/
- DnR dataset: https://github.com/darius522/dnr-utils#overview