The First General-Purpose Visual and Language AI: LLaVA
LLaVA: Bridging the Gap Between Visual and Language AI with GPT-4


Watch the video!
GPT-4 is powerful, but did you know that some AIs are built entirely thanks to it? Yes, GPT-4 is so good that it can be used to generate good enough data to train other AI models. And not any model but better models than itself! Liu et al. just used GPT-4 to create a general-purpose language vision model called LLaVA, the first general-purpose model that understands and follows visual and language-based instructions. Basically, a model that has an almost perfect understanding of text and images at the same time. So you can ask it anything about any image. Since GPT-4 is not able to see images yet, but is incredibly good with text, we can send it the captions of our image and ask it to produce different types of outputs like questions for Q&A, a more detailed description of the image or even reasoning questions and answers about the image caption. So this is what the authors did. They gave a role and personality to the GPT-4 model and asked it to generate various types of data all based on the initial caption they had for each image.

Here’s what the instructions given to GPT-4 looked like in the LLaVA case to build the best dataset possible to allow the language model to understand the image as deeply as possible. Going from asking to describe the image in a concise way to an exhaustive description or even a thorough analysis of it.

These user-generated prompts and GPT-4-generated answers will populate a good dataset full of different questions and answers and descriptions of our images, allowing us to train our multimodal AI, so an AI that can process images and text to then send the questions along with the image and try to re-generate the answer GPT-4 initially gave us. Once you have this kind of dataset built, thanks to GPT-4 and your initial pool of image-caption pairs, you can enter the next step for building a powerful image and text model almost automatically with a new technique called visual instruction tuning.
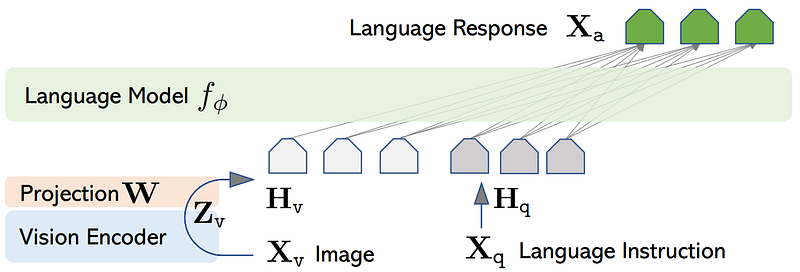
Visual instruction tuning is pretty straightforward. You use your image along with the questions you asked GPT-4 to train a new model to answer this question without the image caption. So it needs to understand the image itself to answer the question instead of the caption, which was used by GPT-4. To do that, we need something that can understand images AND text and combine its understanding of the question with the image to answer it.
Instead of starting from scratch, we can use two already powerful models; one for language and another for vision. In the case of LLaVA, they decided to use LLaMA as their base large language model that they want to train to understand images and text together. LLaMA is a recent large language model published by Meta with amazing text understanding capabilities with the advantage of being somewhat open-source, meaning that the researchers could adapt it to their new task involving images, a process called fine-tuning. Something you cannot do with GPT-4. Since LLaMA only understands text, they need to translate their images into something it can understand. Fortunately for us, a powerful model named CLIP can do that, having been trained on a lot of image-caption pairs, focusing strictly on converting the image into the same representation as our text, so number matrices called embeddings that are similar for the same image and caption pair. This part of the model translating the image embeddings into text-like embeddings is trained along with the language model. Then, you can combine your text instructions with your new text-like image representation and send that to the LLaMA model, which will be trained to give the right answer.

The only parts not being trained are the GPT-4 model we initially used to generate our dataset and the CLIP image encoder model to generate our image embeddings. We train the LLaMA model and the image-to-text conversion, a single linear layer with simple learned weights.
And voilà! This is how they built LLaVA, a powerful multimodal model combining both CLIP and LLaMA, as well as the power of GPT-4 to very efficiently build a powerful multimodal AI for image and text! The researchers were pretty clever, not reinventing the wheel and using powerful pre-existing methods, fine-tuning only LLaMA and the image-to-text embedding conversions.

What is even cooler is that all their work is open-source, which they keep updating. They also shared a demo for anyone to try online for free if you’d like to see LLaVA’s capabilities for yourself. I hope you’ve enjoyed this overview of the recent LLaVA model, and I invite you to read their paper for more information on the dataset generation using GPT-4, as well as their visual instruction tuning process. This is one of the first models being built with the help of GPT-4, and I believe more and more are to come with powerful agents and models combining forces. This is another example of how AI is democratizing an industry, allowing researchers to have access to large and complex datasets that would be incredibly costly and time-demanding to build. As one would say, “What a time to be alive!”.
I will see you next time with another amazing paper!
References
- Liu et al., 2023: Visual Instruction Tuning, https://arxiv.org/pdf/2304.08485.pdf
- Code: https://github.com/haotian-liu/LLaVA
- Demo: https://llava-vl.github.io/