LLM Weaknesses 101: What They Really Learn
What LLMs really learn...


Watch the video!
In the last video, we went through the basics of training large language models and, really, machine learning as a whole. If you didn’t catch every detail, don’t worry — you weren’t supposed to. The goal wasn’t to make you an AI research scientist in twenty minutes but to give you just enough context to see where everything fits together. We touched on transformers, training objectives, and how LLMs don’t learn like humans. That last part is key: these models have unique strengths and weaknesses that make them powerful building blocks in some areas and unreliable in others.
These weaknesses are crucial to understand so you can know where you can build with and use LLM tools safely and appropriately in your workflows and what techniques you can use to address these issues. LLMs are not plug-and-play geniuses; they often need extra work to be practical in real-world applications.
Now, let’s take a closer look at what these models actually “learn,” where they fail, and what we can do about it.
What Does the LLM Actually Learn?
We’ve seen that transformers spend their entire training cycle obsessively predicting the next token, but what precisely is being learned? Inside these models appears a complex internal representation — a high-dimensional vector space, just like the 2 or 3 dimensional graphs we saw in school, but in the order of thousands. They are often called the embedding space — where tokens like “kitten” and “puppy” appear near each other, while “chainsaw” or “fire” wisely stay well away.
This process, developed iteratively during billions of training cycles, creates one of LLM’s standout strengths: semantic understanding of your questions. It doesn’t just retrieve matching keywords but accesses interconnected layers of meaning — grasping context, nuance, and abstract connections. It comfortably handles complex queries, comparing and synthesizing across diverse concepts — far beyond the keyword-bound reach of traditional search engines.
This is all great, but the important bit is that this is not how humans think. The LLM isn’t reasoning. It isn’t forming opinions. It’s just extremely efficient and surprisingly crunches probabilities, which also leads to some of its weaknesses. What we see as “intelligent” responses materialize from a soup of statistical relationships between tokens, stacked together in a way that feels like comprehension. What matters to us is how this system fails and what we can do to make it more reliable. So let’s understand these weaknesses, or limitations, a bit better…
Knowledge Cut-off (Access to Latest Information)
One of the biggest limitations of how neural networks are trained is that it’s a one-shot deal — train once, deploy, and then hope the world doesn’t change too much. Training these models is no small feat either — it takes months of training on GPUs in data centers that cost billions of dollars to build, and once it’s done, that’s it. The model is frozen in time, blissfully unaware of anything that happens afterward.
This setup works just fine for skills that don’t shift much — like detecting sentiment in text or summarizing decades-old news articles. But throw in something fast-moving, like new AI models, medical research, or current events, and suddenly the model is operating with outdated knowledge.
This limitation is called the model’s Knowledge Cut-off, which marks the last point in time when it was trained on new data. This isn’t just an inconvenience; it fundamentally affects how useful the model is in fields where information moves fast.
For example, ask about the latest Super Bowl winner or the newest Mission Impossible movie, and the model might respond with something like this:
generate("Who won the last super bowl?")
generate( "What is last Mission Impossible movie?" )As of my last update in October 2023, the most recent Super Bowl was Super Bowl LVII, which took place on February 12, 2023. The Kansas City Chiefs won that game, defeating the Philadelphia Eagles with a score of 38-35. If you're looking for information beyond that, please check the latest sources.As of October 2023, the last "Mission: Impossible" movie released is "Mission: Impossible – Dead Reckoning Part One," which premiered in July 2023. It is the seventh installment in the franchise and stars Tom Cruise as Ethan Hunt. A sequel, "Mission: Impossible – Dead Reckoning Part Two," is scheduled for release in 2024.
To patch this gap, developers use external resources like web searches, Wikipedia pages, document databases, or structured data formats like PDFs and JSON files. More on this later in the module! It’s not a perfect fix, but it helps keep the model somewhat tethered to reality.
LLMs don’t memorize all Human Knowledge!
Another limitation worth mentioning is that LLMs don’t precisely store knowledge or obscure facts in their parameters, even if it appeared in their training data. They instead absorb broad patterns and generalities from vast amounts of data rather than explicitly memorizing every detail. So, if asked about a niche medical procedure, or a rarely cited historical event, the model often struggles.
On top of this, a lot of key information is locked away in internal corporate data or in the expertise of professional employees. Even if this knowledge existed before the model training cut-off — the AI company’s never got their hands on it and the model never saw it during training.
Hallucinations and Errors
Another obvious limitation with LLMs is they get things wrong. A lot. Sometimes they misinterpret a question. Sometimes they confidently assert nonsense, just like our medical procedure where the model could give something totally false. The main problem is that it doesn’t know its wrong. It doesn’t have the concept of a truth, a fact, and a lie. It just knows words and statistical correlations. We call these lies “hallucinations” — even though it may not be the best word for it. Much of the time, this is ultimately due to the factors we’ve just discussed on the limitations of its memorised knowledge and architecture.
The model isn’t fact-checking itself. It generates each token based purely on what statistically makes the most sense. If its training data contained errors, those errors get baked into its responses. If it has a gap in its knowledge, it won’t admit it — it’ll just interpolate based on patterns.
💡Yes, interpolate, not extrapolate. It cannot extrapolate to new knowledge unless you give it some examples or ways to get it first. It can only take what it has seen and make new connections between them but can’t develop some new paradigm and extrapolate from the data it has seen, just like other AI models before LLMs appeared. Anyways, sorry about this parenthesis, let’s get back to this hallucination issue.
The post-training process with “instruction tuning” and “reinforcement learning from human feedback,” which we also discussed, plays a role here. Models are rewarded for being helpful assistants and following instructions; this can lead them to making up information just to please you!
There are ways to reduce hallucinations, which we’ll cover later in this course, but they never fully go away. That means any LLM-powered system needs safeguards — whether it’s external knowledge retrieval, human oversight, or clear disclaimers.

An example of ChatGPT simply accepting a wrong fact as it cannot tell the truth from a lie, and its reinforcement training taught it to apologize and follow the user’s feedback.
To understand this concept better, take a look at this; when we ask, “What is the name of the Towards AI developed largest open-source model, and what is its size?” the GPT-4o model confidently responds that Towards AI developed Grok.
However, the Grok model was developed by xAI, which is a 314 Billion Parameters LLM (Grok 1). In fact, Towards AI has not released an open-source model (yet) while xAI has already released Grok-3.

This issue is not unique to ChatGPT or OpenAI. Similar LLMs, like Claude, Llama, Gemini, and Mistral, also exhibit this behavior.
LLMs don’t grasp chronology particularly well
Additionally, LLMs don’t grasp chronology particularly well. Transformers and the attention mechanism processses information in parallel and relies heavily on positional embeddings to provide some sense of order, yet this is a crude substitute for a genuine understanding of time or cause-and-effect relationships. LLMs frequently jumble timelines or confuse event sequences, which you may have experienced already. Just try to get a good 6-month training plan for a marathon, and you’ll see what I mean.
Biases
Another issue is LLMs can also absorb biases lurking within their training data. These biases usually originate in datasets that lack sufficient linguistic and cultural diversity, or datasets steeped in historical stereotypes and outdated assumptions — such as much of the internet! If the training data persistently portrays women in subordinate roles or repeats harmful stereotypes — perhaps depicting certain ethnic groups as inherently violent or dishonest — then the model, being a statistical echo chamber, naturally learns to replicate those viewpoints.
These are outputs from the “GPT-4o-mini” model. The responses clearly echo traditional gender stereotypes, automatically associating occupations like “engineer” and “construction worker” with men, and “nurse” or “social worker” predominantly with women. Biases inherent can creep unnoticed into the model’s outputs without intention or awareness.

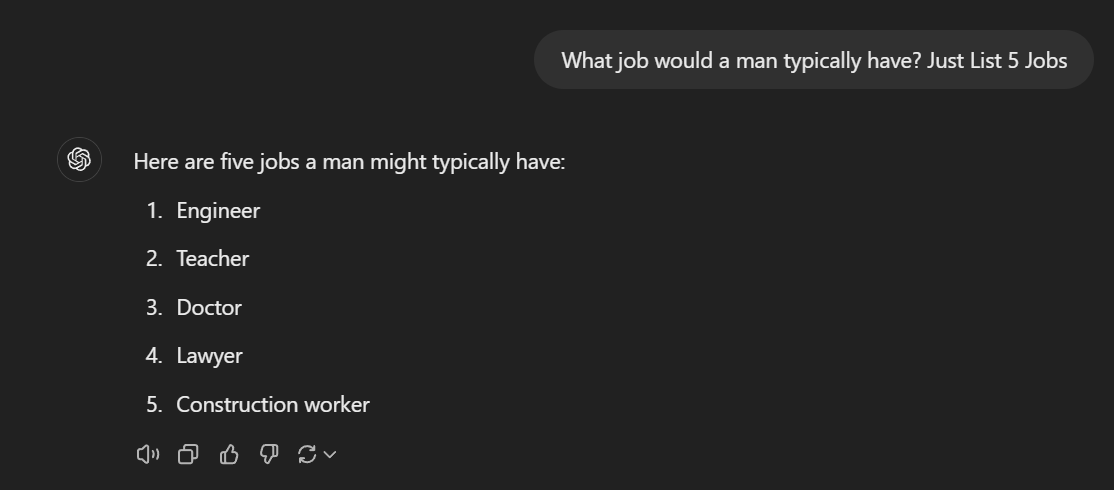

Biases aren’t confined only to sensitive demographics like race or gender. They surface wherever the model has encountered uneven or skewed training data — be it industry norms, regional business practices, or specialized applications. In short, when biased patterns sneak into the data, they’ll probably pop up again, echoed by the model, in whatever responses it generates. Biases are inevitable. Every human has biases; every government has biases. The goal here is to reduce the bad ones and focus on the good biases, like being nice to each other.
Generalization out of Training Data Distribution?
Sometimes, LLMs positively surprise us. They can generate answers that feel creative — applying knowledge in novel ways that go beyond simple memorization. If you ask one to write a pasta recipe in the style of a pirate sea shanty, it’ll do a great job, even though nobody fed it a dataset of pirate-themed recipes.
The model is great at recognizing patterns and combining features from different data sources. But how far does that take us? Can LLMs solve completely new problems that require reasoning beyond what’s in their training set? That’s less clear. It’s still what we call interpolation.
Still, is this real intelligence? I don’t really know, honestly. Much hangs on your personal definition of intelligence. After all, human creativity often similarly involves repurposing bits of knowledge from disparate fields.
A key test is whether LLMs can generate correct answers for concepts outside the distribution of their training data. Right now, they struggle. They cannot extrapolate much like humans do. Their reasoning abilities are limited, and their ability to extrapolate is inconsistent. This is why, for now, human oversight remains essential when using LLMs in any high-stakes setting.
Unexpected Failure Modes
Some of the best evidence that LLMs don’t truly understand the world and generalize comes from their weird, counterintuitive failures.
The alien form of intelligence exhibited by LLMs creates a paradox. The same model capable of smoothly articulating complex essays might fail simple tasks that elementary students nail routinely. Because their intelligence is statistical rather than genuinely reflective, subtle misunderstandings and hallucinations can sneak in. Even when an LLM appears highly intelligent, it may harbor fundamental misunderstandings that are not immediately apparent. Users easily fall into overestimating these models’ raw outputs, leading to mistakes that can range from trivially obvious to dangerously subtle.
Take a recent test with OpenAI’s GPT-4o and o1 models. When asked how many “R”s are in the word strawberry, it confidently answered two. When pressed to double-check, it corrected itself: three. That at least shows some progress. But when asked to list their positions, it gave 5, 8, and 9 — which is wrong. The correct positions are 3, 8, and 9.
This isn’t just a typo. It’s evidence of a deeper issue: the model doesn’t actually “see” words the way we do. Its tokenization system means that letter counting is not a simple task, and its statistical approach to generating responses sometimes leads to nonsensical answers.
Another common logic puzzle shows similar flaws: “Sally has three brothers. Each brother has two sisters. How many sisters does Sally have?” Initially, ChatGPT 4o claimed, “Sally has two sisters.” However, when breaking down the logic, it concluded that Sally is one of the two sisters shared with her brothers, leaving only one sister beside her.
This highlights a critical weakness — despite impressive conversational abilities, LLMs often struggle with simple relational reasoning. Even basic tasks can lead to unexpected errors.
One complexity of judging LLM’s ability by anecdotal examples of failure is that the inner workings of an LLM are actually very complex. It may have the capability for more complex reasoning and for finding the correct answer to these logic puzzles — but the highest probability next token chosen for the output is instead hijacked by simpler neural circuits that memorised similar looking, yet different, logical puzzles in the training data. Sometimes different prompting can prime the model in different ways and unlock more careful thinking.
💡Navigating all these paradoxical AI failures requires vigilance and a more advanced understanding of how they work and why they have these failures.
It also underscores why rigorous checks and guardrails remain critical when deploying LLMs, particularly in high-stakes scenarios.
Reducing Shortcomings With RAG, Prompting, Fine-Tuning and Tools
So far in this article, we’ve been pretty harsh on LLMs — maybe enough to leave you questioning why you’ve bothered with a whole course about building with them. The truth is, we genuinely appreciate what these models can do, despite their odd quirks and occasional faceplants. There’s plenty we can do to mitigate their shortcomings and eccentricities, which we’ll get into shortly. But we think it was important to first make sure their peculiarities sink in deeply and to help you conceptualize precisely where and why these issues arise. Understanding the anatomy of these failures isn’t pessimism; it’s a foundation for effectively deploying LLMs in ways that keep their strengths front-and-center while limiting their weaknesses.
Dependability jumps once you add structured prompting, retrieval-augmented generation (RAG), targeted fine-tuning, and tool-calling APIs — which we’ll dive into in the course.
Other advanced techniques include retrieval-augmented generation (RAG) — providing relevant data to the model at scale, specialized fine-tuning — adapting the model parameters to improve performance on specific tasks, and integration with external tools. Many of these techniques are packaged and available directly in chatbots such as ChatGPT or other Generative AI apps built on top of these same models that are customized to specific industries or use cases.
Nevertheless, knowing precisely when to trust an LLM — and when to double-check its output — also remains crucial. This selective skepticism, paired with skilled usage and the right choice of AI model or AI App, can transform a flawed intelligence into an incredibly useful assistant.
Conclusion
Some models or customised applications built on top of them are far more capable and reliable at certain tasks than alternative models. But with new state-of-the-art models and tools coming out daily, keeping on top of the best tool for your task is no easy challenge!
What does that mean for you? It means opportunity. Those gaps are your opportunity: master each weakness, choose the right model, and engineer the glue that melds it with your domain workflows.
Thank you for reading!