

The short version
Make-A-Video is a 2022 Meta research model that adapts text-to-image generation to produce short videos from text. It learns appearance from paired text-image data and motion from unlabeled video, adds temporal convolution and attention to the spatial model, then uses interpolation and upscaling to create more frames at higher resolution. The clips can still flicker or deform.
Watch the video
Meta AI’s new model make-a-video is out and in a single sentence: it generates videos from text. It’s not only able to generate videos, but it’s also the new state-of-the-art method, producing higher quality and more coherent videos than ever before!
You can see this model as a stable diffusion model for videos. Surely the next step after being able to generate images. This is all information you must’ve seen already on a news website or just by reading the title of the article, but what you don’t know yet is what it is exactly and how it works.
Make-A-Video is the most recent publication by Meta AI, and it allows you to generate a short video out of textual input, just like this.

A dog wearing a Superhero outfit with red cape flying through the sky. Video generated with Make-A-Video by Singer et al. (Meta AI), 2022.
So you are adding complexity to the image generation task by not only having to generate multiple frames of the same subject and scene, but it also has to be coherent in time. You cannot simply generate 60 images using DALLE and generate a video. It will just look bad and nothing realistic.
You need a model that understands the world in a better way and leverages this level of understanding to generate a coherent series of images that blend well together. You basically want to simulate a world and then simulate recordings of it. But how can you do that?
Typically you would need tons of text-video pairs to train your model to generate such videos from textual inputs, but not in this case. Since this kind of data is really difficult to get and the training costs are super expensive, they approach this problem differently.
Another way is to to take the best text-to-image model and adapt it to videos, and that’s what Meta AI did in a research paper they just released. In their case, the text-to-image model is another model by Meta called Make-A-Scene, which I covered in a previous article if you’d like to learn about it. But how do you adapt such a model to take time into consideration? You add a spatial temporal pipeline for your model to be able to process videos.
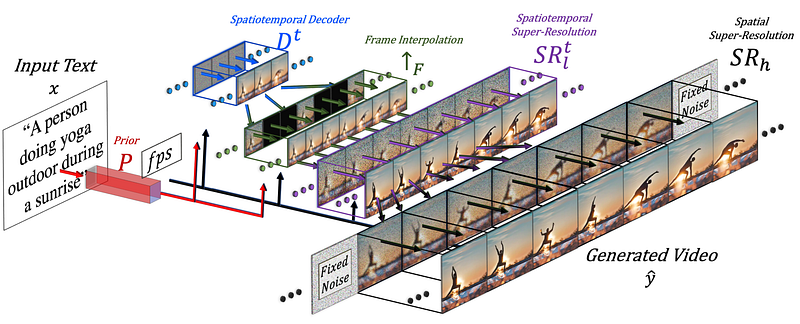
Overview of the approach. Image from Singer et al. (Meta AI), 2022.
This means that the model will not only generate an image but, in this case, 16 of them in low-resolution to create a short coherent video in a similar manner as the text-to-image model but adding 1D convolution along with the regular 2D one. This simple addition allows them to keep the pre-trained 2D convolutions the same and add a temporal dimension that they will train from scratch, re-using most of the code and model’s parameters from the image model they started from.
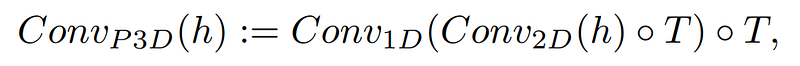
Addition of the 1-dimensional convolutional module after the regular 2-dimensional convolution module used in the text-to-image approach.
We also want to guide our generations with text input, which will be very similar to image models using CLIP embeddings. A process I go into detail in my stable diffusion video if you are not familiar with the approach. But they will also be adding the spacial dimension when blending the text features with the image features, doing the same thing: keeping the attention module I described in my make-a-scene video and adding a 1-dimensional attention module for temporal considerations — copy-pasting the image generator model and duplicating the generation modules for one more dimension to have all our 16 initial frames.
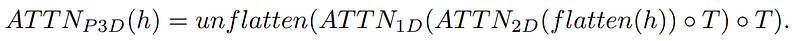
Addition of the 1-dimensional attention module after the regular 2-dimensional attention module used in the text-to-image approach.
But 16 frames won’t take you far for video. We need to make a high-definition video out of those 16 main frames. It will do that by having access to previous and future frames and iteratively interpolating from them both in terms of temporal and spatial dimensions at the same time. So basically generating new and larger frames in between those 16 initial ones based on the frames before and after them, which will facilitate making the movement coherent and overall video fluid. This is done using a frame interpolation network which I also described in other videos, but will basically take the images we have and fill in gaps generating in-between information. It will do the same thing for the spatial component, enlarging the image and filling the pixel gaps to make it more high definition.
So, to summarize, they fine-tune a text-to-image model for video generation. This means they take a powerful model already trained and adapt and train it a little bit more to get used to videos. This technique will simply adapt the model to this new kind of data, thanks to the spatial temporal module additions we discussed, instead of having to re-train it all, which is incredibly costly. This re-training will be done with unlabeled videos just to teach the model to understand videos and video frame consistency, which makes the dataset-building process much simpler. Then, we use once again an image-optimized model to improve spatial resolution and our last frame interpolation component to add more frames to make the video fluent.
And voilà!

Clown fish swimming through the coral reef. Video generated with Make-A-Video by Singer et al. (Meta AI), 2022.
Of course, the results aren’t perfect yet, just like text-to-image models, but we know how fast the progress goes.
This was an overview of how Meta AI successfully tackled the text-to-video task in this great paper. All the links are in the description if you’d like to learn more about their approach. A PyTorch implementation is already being developed by the community as well, so stay tuned for that if you’d like to implement it yourself (link below)!
Thank you for watching the whole video and I will see you next time with another amazing paper!
References
► Meta’s blog post: https://ai.facebook.com/blog/generative-ai-text-to-video/
►Singer et al. (Meta AI), 2022, “MAKE-A-VIDEO: TEXT-TO-VIDEO GENERATION WITHOUT TEXT-VIDEO DATA”, https://makeavideo.studio/Make-A-Video.pdf
►Make-a-video (official page): https://makeavideo.studio/?fbclid=IwAR0tuL9Uc6kjZaMoJHCngAMUNp9bZbyhLmdOUveJ9leyyfL9awRy4seQGW4
► Pytorch implementation: https://github.com/lucidrains/make-a-video-pytorch
FAQ
What does Meta's Make-A-Video do?
It generates a short video from a text description by extending text-to-image learning with temporal motion.
Does training require a massive paired text-video dataset?
The method reduces that dependence by learning appearance from text-image data and motion from unlabeled videos.
How are the first video frames generated?
The model creates a low-resolution sequence, then applies spatial and temporal processing to improve it.
Why is video generation harder than image generation?
Every frame must look plausible while objects, identity, motion, and camera behavior remain coherent over time.
What limitations should viewers expect?
Short generated clips can still contain flicker, deformations, inconsistent motion, and weak physical understanding.