

Key takeaways
- This means you can help it segment unknown objects through prompts without retraining the model, which is called zero-shot transfer.
- Then, for the text, it is simple; we use CLIP as always, a model able to encode text similar to how images are encoded.
- Other than data, which most models use anyways, let’s see how the model works and how it implements prompting into a segmentation task because this is all related.
Watch the video!

Segmentation examples from the SAM model.
Segmentation is the ability to take an image and identify the objects, people, or anything of interest. It’s done by identifying which image pixels belong to which object, and it’s super useful for tons of applications where you need to know what’s going on, like a self-driving car on the road identifying other cars and pedestrians.
We also know that prompting is a new skill for communicating with AIs.
What about promptable segmentation?
Promptable segmentation is a new task that was just introduced with an amazing new AI model by Meta; SAM. SAM stands for Segment Anything Model and is able to segment anything following a prompt.
Today we’re releasing the Segment Anything Model (SAM) — a step toward the first foundation model for image segmentation.
SAM is capable of one-click segmentation of any object from any photo or video + zero-shot transfer to other segmentation tasks ➡️ https://t.co/qYUoePrWVi pic.twitter.com/zX4Rxb5Yfo
— Meta AI (@MetaAI) April 5, 2023
How cool is that?!

Segmentation example from the SAM model.
In one click, you can segment any object from any photo or video!
It is the first foundation model for this task trained to generate masks for almost any existing object. It’s just like ChatGPT for segmenting images, a very general model pretty much trained with every type of image and video with a good understanding of every object. And similarly, it has adaptation capabilities for more complicated objects like a very specific tool or machine. This means you can help it segment unknown objects through prompts without retraining the model, which is called zero-shot transfer. “Zero-shot” as in it has never seen that in training.
To answer the second question of why it is that good, we must go back to the root of all current AI systems: data. It is that good because we trained it with a new data set, which I cite, is “the largest ever segmentation dataset”.
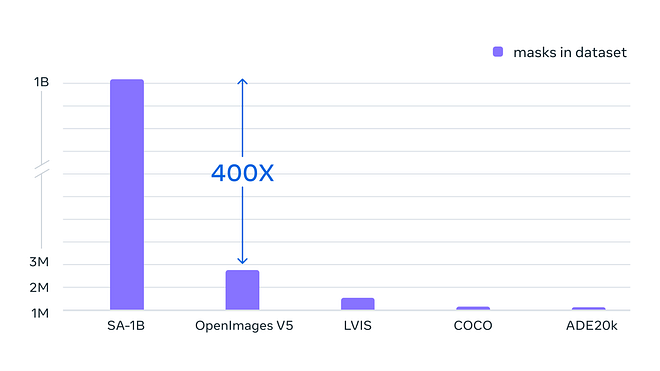
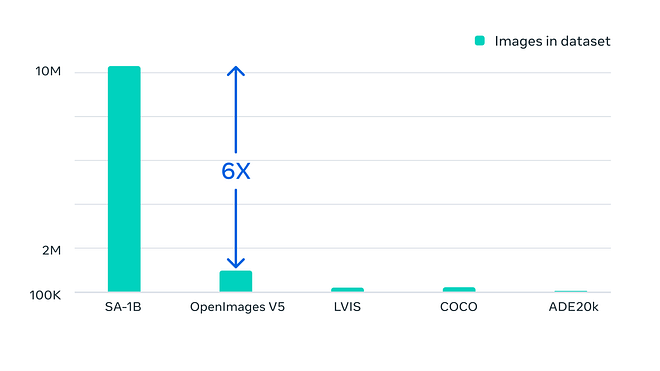
Dataset statistics for Segment Anything 1 Billion. Image from Meta’s blog post.
Indeed, the dataset called Segment Anything 1 Billion was built specifically for this task and is composed of 1.1 billion high-quality segmentation masks from 11 million images. That represents approximately 400 times more masks than any existing segmentation dataset to date.
This is enormous and of super high quality with really high-definition images.
And that’s the recipe for success. Always more data and good curation.
Other than data, which most models use anyways, let’s see how the model works and how it implements prompting into a segmentation task because this is all related.
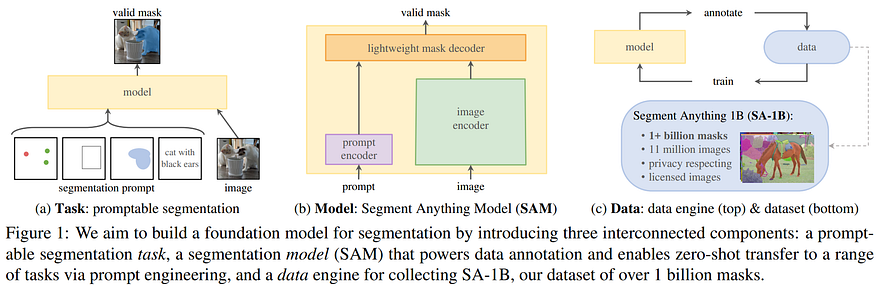
Image from Meta’s paper.
Indeed, the dataset was built using the model itself iteratively (figure above, c)). As you can see here on the right, they use the model to annotate the data, further train the model and repeat. This is because we cannot simply find images with masks around objects on the internet.
Instead, we start by training our model with human help to correct the predicted masks. We then repeat with less and less human involvement, primarily for the objects that the model didn’t see before.
[
Louis-François Bouchard’s Weekly AI Digest | Substack
](https://louisbouchard.substack.com/)
But where is prompting used? It is used to say what we want to segment from the image.
As we’ve talked in my recent podcast episode with Sander Schulhoff, founder of learn prompting, a prompt can be anything. In this case, it’s either text or spatial information like a rough box or just a point on the image, basically asking what you want or showing it.
Then, we use an image encoder, as with all segmentation tasks, and a prompt encoder, as shown in the figure above, b). The image encoder will be similar to most I already covered on the channel, where we take the image and extracts the most valuable information from it using a neural network.
Here, the novelty is our prompt encoder. Having this prompt encoder separated from our image encoder is what makes the approach so fast and responsive since we can simply process the image once and then iterate prompts to segment multiple objects, as you can see by yourself in their online demo.
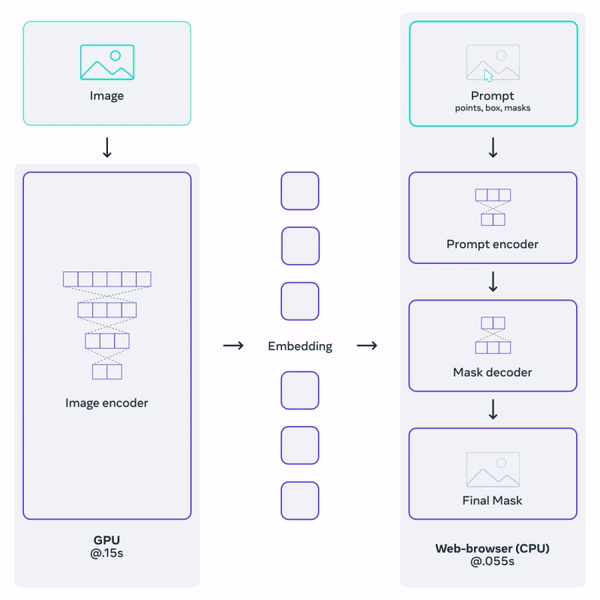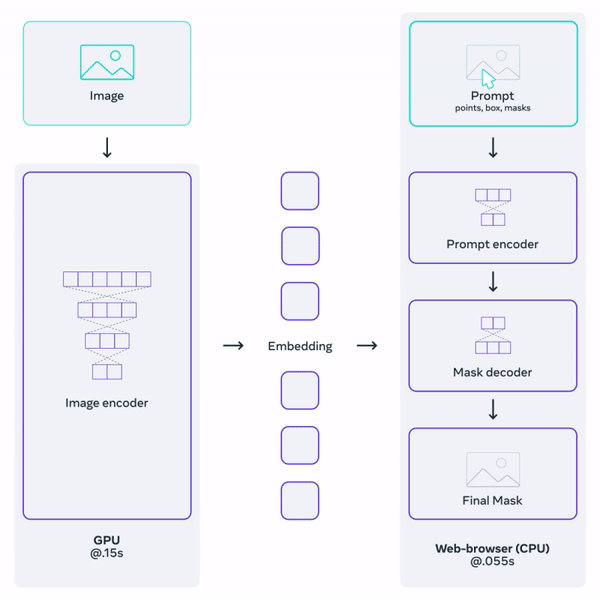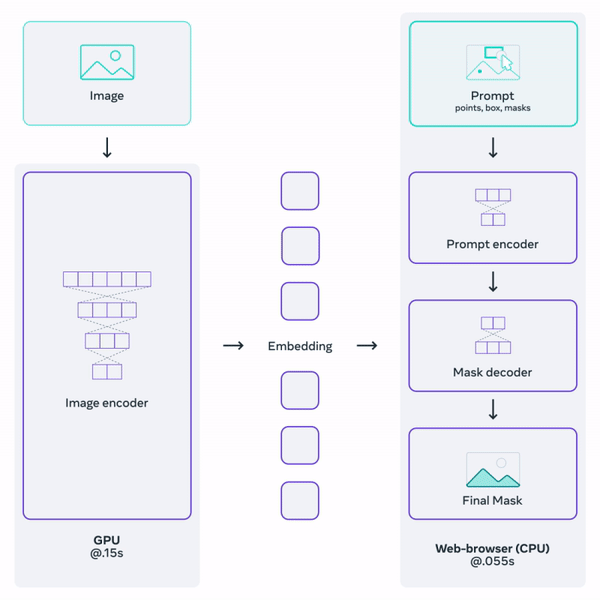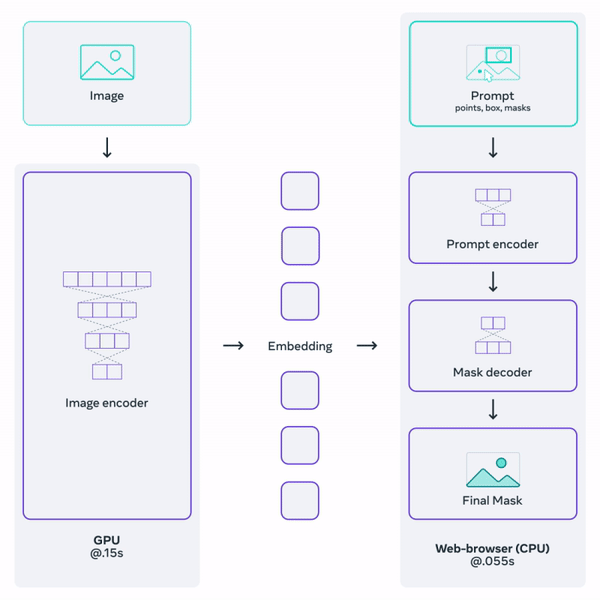
Overview of the Segment Anything Model. Image from Meta’s blog post.
The image encoder is another Vision transformer or ViT that you can learn more about in my vision transformer video if you’d like. It will produce our image embeddings, which are our extracted information.
Then, we will use this information along with our prompts to generate a segmentation.
But how can we combine our text and spatial prompts to this image embedding? We represent the spacial prompts through the use of positional encodings, basically giving the spatial information as is. Then, for the text, it is simple; we use CLIP as always, a model able to encode text similar to how images are encoded. CLIP is amazing for this application since it was trained with tons of image-caption pairs to encode both similarly. So when it gets a clear text prompt, it is a bridge for comparing text and images.
And finally, we need to produce a good segmentation from all those information. This can be done using any decoder, which is, simply put, the reverse network of the image encoder, taking condensed information and re-creating an image, though now we only want to create masks that we put back over the initial image, so it’s much easier than generating a new image as DALLE or MidJourney does. DALLE uses a diffusion model, but in this case, they decided to go for a similar architecture as the image encoder: a vision transformer-based decoder that works really well.
And voilà!
This was a simple overview of how the new SAM model by Meta works! Of course, it is not perfect and has limitations like missing fine structures or sometimes hallucinating small disconnected components.

Image from Meta’s paper.
Still, it’s extremely powerful and a huge step forward, introducing a new, interesting, and highly applicable task. I invite you to read Meta’s great blog post and paper to learn more about the model or try it directly with their demo or code. All the links are in the references below.
I hope you’ve enjoyed this article, and I will see you next time with another amazing paper!
References
►Paper: Kirillov et al., Meta, (2023): Segment Anything, https://ai.facebook.com/research/publications/segment-anything/
►Demo: https://segment-anything.com/demo
►Code: https://github.com/facebookresearch/segment-anything
►Dataset: https://segment-anything.com/dataset/index.html
FAQ
What is the useful lesson from Meta's new Segment Anything Model Explained?
SAM, promptable segmentation and the largest segmentation dataset to date! This means you can help it segment unknown objects through prompts without retraining the.
What should builders do with meta's new Segment Anything Model?
Then, for the text, it is simple; we use CLIP as always, a model able to encode text similar to how images are encoded.
What is the hype trap with meta's new Segment Anything Model?
The risk is reacting to every headline. Most releases matter only after you map them to a real workflow or constraint.
How should builders use meta's new Segment Anything Model?
Other than data, which most models use anyways, let’s see how the model works and how it implements prompting into a segmentation task because this is all related.
When does meta's new Segment Anything Model become useful in practice?
DALLE uses a diffusion model, but in this case, they decided to go for a similar architecture as the image encoder: a vision transformer-based decoder that works really well.
What should beginners understand about meta's new Segment Anything Model?
This was a simple overview of how the new SAM model by Meta works!
What is the common mistake with meta's new Segment Anything Model?
Today we're releasing the Segment Anything Model (SAM), a step toward the first foundation model for image segmentation.