

The short version
A mixture-of-experts Transformer routes each token through only a subset of alternative feed-forward blocks, so the model can have many total parameters without activating all of them for every token. The "experts" are not necessarily topic specialists. This 2024 explanation uses Mixtral 8x7B as its concrete example; its GPT-4 parameter discussion is explicitly unconfirmed.
- This means that the model tries to predict the next token, or next word, of a sentence you send as the input prompt.
- First, obviously, you’ll have your text and need to get your embeddings, which are the numbers the model understands.
- This attention mechanism has made a lot of noise since the paper Attention is All You Need in 2017.
Watch the full video!
What you know about Mixture of Experts is wrong. We are not using this technique because each model is an expert on a specific topic. In fact, each of these so-called experts is not an individual model but something much simpler.
Thanks to Jensen, we can now assume that the rumour of GPT-4 having 1.8 trillion parameters is true…
1.8 trillion is 1,800 billion, which is 1.8 million million. If we could find someone to process each of these parameters in a second, which would basically be to ask you to do a complex multiplication with values like these, it would take them 57,000 years! Again, assuming you can do that in a second. If we do this all together, calculating one parameter per second with 8 billion people, we could achieve this in 2.6 days. Yet, transformer models do this in milliseconds.
This is thanks to a lot of engineering, including what we call a “mixture of experts.”
Unfortunately, we don’t have much detail on GPT-4 and how OpenAI built it, but we can dive more into a very similar and nearly as powerful model by Mistral called Mixtral 8x7B.
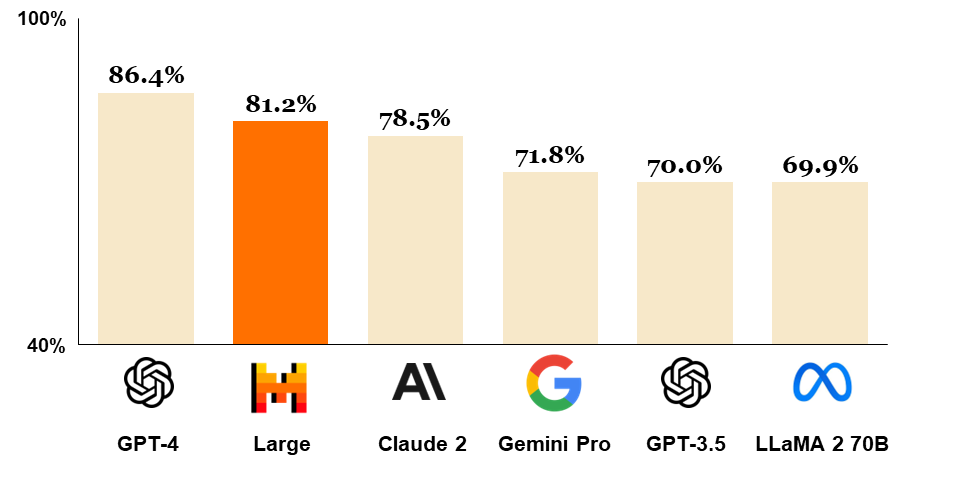
Image credit: Mistral AI blog.
By the way, if you don’t know about Mistral yet, you should definitely consider following their work! Mistral is a French startup building state-of-the-art language models, and they are quite promising and actually quite open to sharing their advances compared to some other known companies. And if keeping up with all those different companies and research seems hard, well, you can easily stay up-to-date with all these new advancements by subscribing to the channel or my newsletter linked below!
But what exactly is a mixture of experts? As I said, it is not multiple experts as most people say. Even though the model is called Mixtral 8x7B, it’s not 8 times a 7-billion-parameter model, and likewise for GPT-4. Even though we assume it has 1.8 trillion parameters, which has never been confirmed by OpenAI, there are no 8 experts of 225 billion parameters. It’s actually all just a single model.
To better understand that, we need to go into what makes transformer models work…
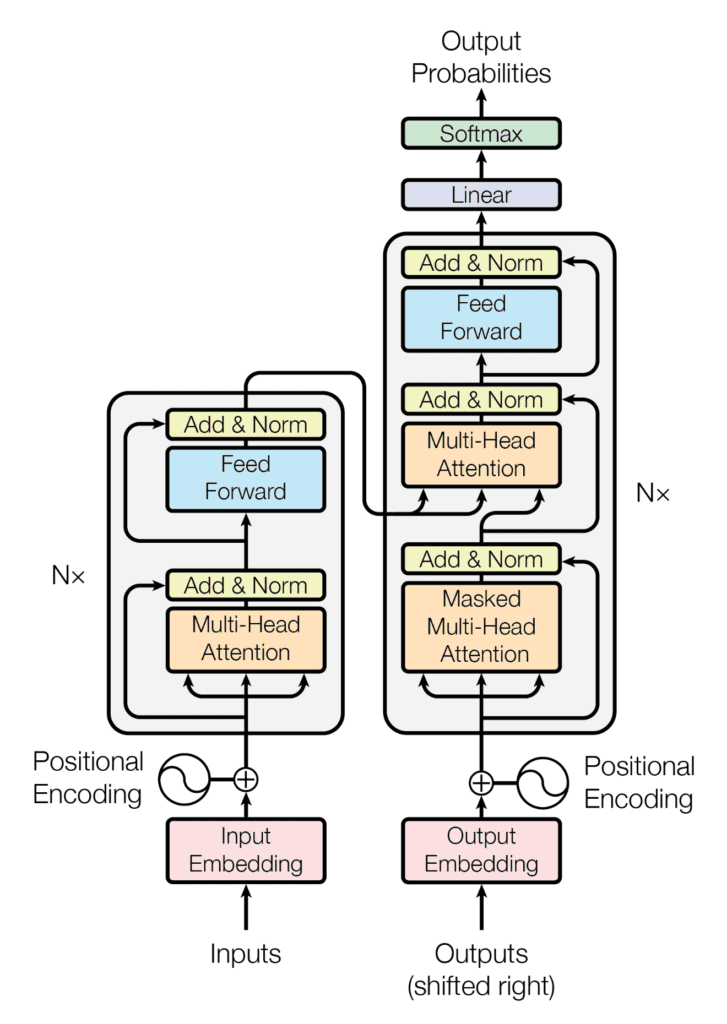
The Transformer architecture. Image from Attention is All you Need (Google).
Even though you’ve probably seen this image a lot, what we actually use is something more like this: a decoder-only transformer.
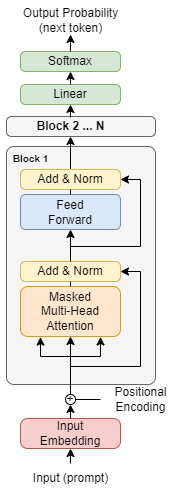
Decoder-only transformer. Image from Attention is All you Need (Google).
This means that the model tries to predict the next token, or next word, of a sentence you send as the input prompt. It does that word by word, or token by token, to construct a sentence that statistically makes the most sense based on what it has seen during its training.
Now, let’s dive into the most important parts. First, obviously, you’ll have your text and need to get your embeddings, which are the numbers the model understands. You can see this as a large list of around a thousand values representing various attributes about what your input sentence or word means. One could be how big it is, and the other could be its colour, another could be if it can be eaten or not, etc., just various attributes that the embedding model learns by itself to represent our world with just one or two thousand numerical values. This is done for each token, which is a piece of text, part of code, part of an image or whatever, transformed into this list of numbers.
But this information is just numbers in a large list. We just lost all our contextual information, we just have a bunch of words represented in numbers, so we add positional information, basically, just syntactic information, to help better understand the sentence or text sent, showing globally and locally where each word is. So, each token ends up being represented by even more values inside the network. It’s really not that efficient compared to directly understanding language. In the Mixtral case, each list for the tokens has 4096 values. It’s already quite big, and we send many of those at the same time! We now have all our text correctly represented into many lists of these 4000 numbers. Now, what does a model like GPT-4 or Mixtral do with that?
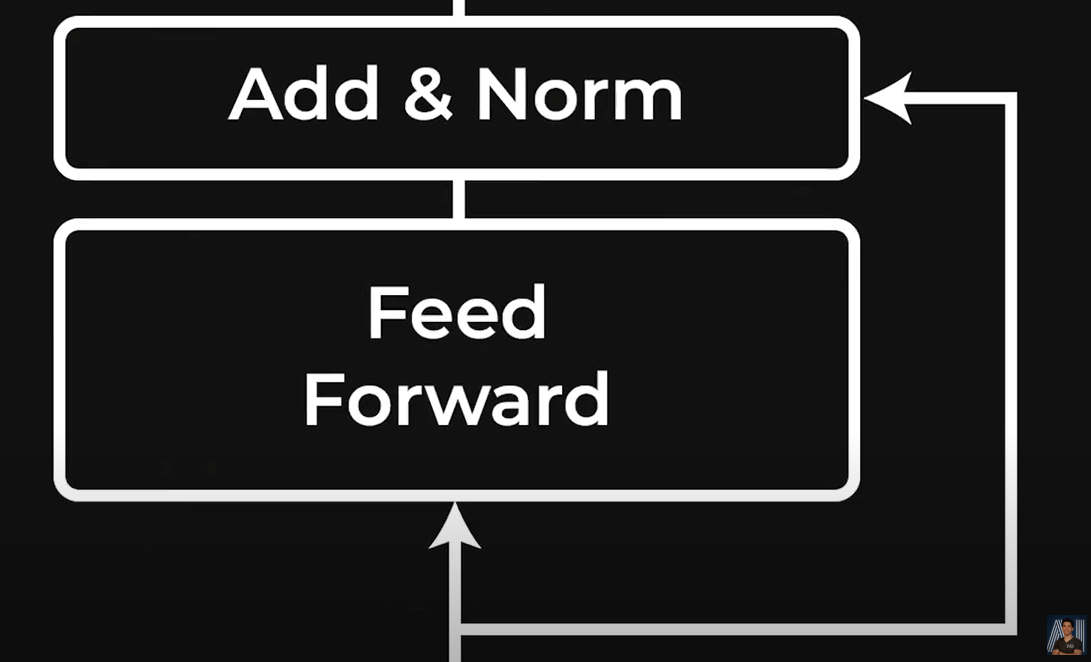
Feed Forward layer in the Transformer bock.
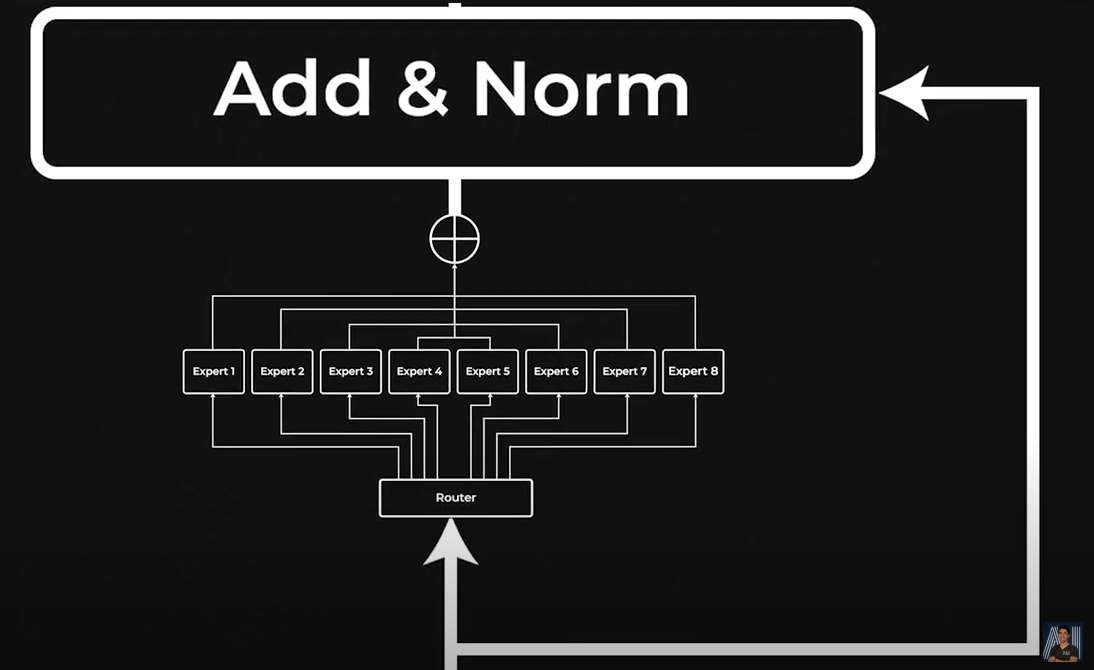
Feed Forward layer replaced by the experts in the Transformer bock.
It understands it, and then repeat this process many times, done inside one essential part: the transformer block, which was introduced in the famous Attention Is All You Need paper.
Inside this block, we have the two crucial components of all those models like GPT-4, Gemini, or Mixtral: An attention step and a feed forward step. Both have their own role.
The attention mechanism is used to understand the context of the input tokens. How they fit together, understand what’s all that. Simply put, we have our many tokens that each are a list of numbers already. The attention mechanism transforms our lists of numbers by basically merging parts of all our current lists together and learning the best combination possible to understand it. You can see this as re-organizing the information so that it makes sense for its own brain. What the model learns when we say it is training is where to put which numbers for the next step. Giving less importance to useless tokens and more to useful ones. Just like when meeting a new person, you’d ideally give more importance to their own name and less on what they said first, whether it was “Hi, Welcome or Hello.” Remembering the name is more important than which synonym they used, even though my own brain doesn’t agree. Here, attention does the same, simply learning what to give more importance to through many examples.
This attention mechanism has made a lot of noise since the paper Attention is All You Need in 2017, and for a good reason: you almost only need this to understand context. Still, you need something else to end up with those huge powerful models of billions and trillions of parameters. These transformer models are that big because they stack multiple transformer block one on the other. But right now, what we’ve seen is an attention step blending content into a new form. It helps for understanding the context but now we lost our knowledge for each token themselves.
To fix for that, we need some kind of function that can process each of these new transformed token to help the model better understand this specific part of the information. This is called a feed forward network or multi layer perceptron. But the name in’t important. What’s important is that it uses the same function or network that is similar to attention but for one specific token individually to go through all tokens one by one to understand it and transform it for the next step. Here by next step I mean going deeper into the network processing the information further and further, basically going into the next attention layer. It’s just like what our brain does with information entering our ear or eyes until it gets understood and we generate an answer whether it be answering or acting. We process information and transform it into a new form. Transformers do the same.
Fortunately, we can do that step in parallel and not have to wait processing all tokens one by one. Still, it becomes a big compute bottleneck because we need to work with large amounts of numbers in parallel. This is where the mixture of experts and even more specifically the sparse mixture of experts comes in. Our experts here are basically different feed forward networks instead of just one. That’s it. This means they can be smaller and more efficient feed forward layers, and run on different GPUs in parallel, yet have even more parameters in total! It even allows the 8 experts to learn different things and complement each other. Only benefits. In the case of Mixtral, there are 8 experts like this. To make it work, we simply add yet another mini network called a router or gating network where its only job is to learn to which expert it should send each token.
So a mixture of experts layer replaces only our feed forward layer by 8 of them. This is why it’s not really 8 models but rather 8 times this specific part of the transformer architecture. And this is all to make it more efficient. One last part I mentioned is that we use sparse mixture of experts. Being sparse just means that most values processed are set to zero. In this case, Mixtral decided to go with using only 2 experts out of the 8 for each token. They determined through experimentations that this was the best combination for results and efficiency. So the router basically sends each token to two experts, does that for all tokens, and recombined everything after. Again, simply to make things more efficient.
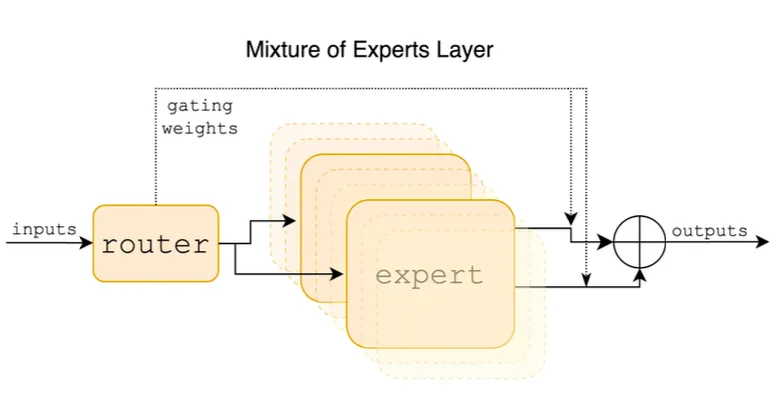
Mixture of Experts Layer. Image by Mistral AI.
That’s it! We simply stack these transformers block together and we end up with a trillion parameter super powerful model called GPT-4, or Mixtral 8x7B in this case. And here, the real number of parameters isn’t 8x7 or 56B. It’s actually smaller, around 47 billion, since it’s only a part of the network that has these multiple experts, and we only need 2 experts at a time for a token transformation, leading to around 13 billion active parameters when we use it! So around a quarter of the total count only.
(Show animation going from this MoE layer back to the transformer left architecture we showed earlier)
Now, why did I start this article saying they were not really experts? Because these 8 “experts” actually are no expert at all. Mistral studied them and concluded that the router sending the tokens to these “experts” did that pretty randomly, or at least, with no observable pattern. Here we see our 8 experts and 8 kind of data whether it be code, mathematics, different languages, etc., and they are, unfortunately, clearly randomly distributed. No expert focused on math or on code. They all helped a bit for everything. So adding those “experts” help, but not in the expected way. It helps because there are more parameters and we can use them more efficiently.
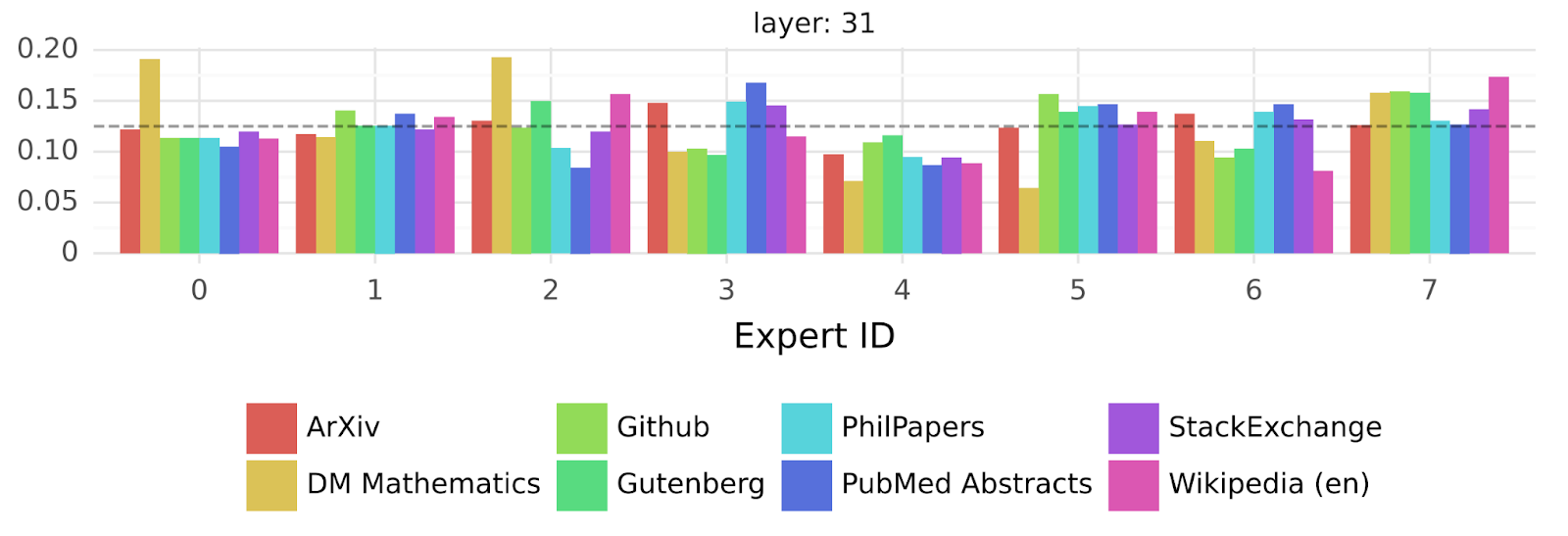
The interesting thing they found is that the same expert seemed to be use when starting a new line generation, which is quite interesting, but not that useful as a conclusion for an analysis!
By the way, the mixture of expert approach is nothing new, as with most techniques we do in AI. This one comes from a while ago. For instance, this is a 2013 paper with an author you should recognize involved at OpenAI, developed on the existing idea of mixture of experts working with such a gating mechanism. We just took this idea to transformers and scaled things up, as we always do!
And voilà! Of course, the overall transformer architecture contains many other important components and is a bit more complicated that what I showed here, but I hope that this Mixture of Experts thing is a bit more clear now and that it broke some beliefs about those being real “experts”, and I especially hope to not see yet another quick calculation multiplying 8 by 7 to find the total amount of parameters for a model!
Thank you for reading the whole article and I’ll see you in the next one with more AI explained!
FAQ
What is a mixture-of-experts language model?
It contains several feed-forward expert networks and routes each token through only a selected subset.
Why use experts instead of activating the whole model?
Sparse routing increases total capacity without paying the full computation cost for every token.
What does the router do?
It scores experts for each token and sends the representation to those expected to process it best.
Does each expert correspond to a clear human topic?
Not necessarily. Specialization emerges during training and may not align with simple labels such as coding or science.
What is a practical MoE tradeoff?
Models gain capacity efficiently, but routing balance, communication, memory, and deployment become more complicated.
Why can't you calculate an MoE model's size by multiplying the number of experts?
The model also has shared layers, and the router activates only some expert blocks for each token, so total and active parameter counts are different.