MVDream: Creating Lifelike 3D Models from Words
MVDream: A new text-to-3d approach (explained)!


Watch the video:
I’m super excited to share this new AI model with you! We’ve seen so many new approaches to generating text, then generating images only getting better. Then, we’ve seen other amazing initial works for generating videos and even 3D models out of text. Just imagine the complexity of such a task when all you have is a sentence, and you need to generate something that could look like an object in the real world, with all its details. Well, here’s a new one that is not merely an initial step; it’s a huge step forward in 3D model generation from just text: MVDream!

As you can see, it seems like MVDream is able to understand physics. Compared to previous approaches, it gets it. It knows that the view should be realistic with only two ears and not two for any possible views. It ends up creating a very high-quality 3D model out of just this simple line of text! How cool is this? But what’s even cooler is how it works… so let’s dive right into it!
If you look at a 3D model, the biggest challenge is that they need to generate both realistic and high-quality images for each view from where you are looking at it, AND those views have to be spatially coherent with each other, not like the 4-eared Yoda we saw previously or multi-face subjects since we rarely have people from the back in an image dataset, so the model kind of wants to see faces at all cost. One of the main approaches to generating 3D models is to simulate a view angle from a camera and then generate what it should be seeing from this viewpoint. This is called 2D lifting since we generate regular images to combine them into a full 3D scene. Then, we generate all possible views from around the object. That is why we are used to seeing weird artifacts like these since the model is just trying to generate one view at a time and doesn’t understand the overall object well enough in the 3D space. Well, MVDream made a huge step in this direction. They tackled what we call the 3D consistency problem and even claim to have solved it using a technique called score distillation sampling, introduced by DreamFusion, another text-to-3D method that was published in late 2022, which I covered on the channel. By the way, if you enjoy this article and these kinds of new technologies, you should definitely follow me! I cover a new approach every week on the blog!

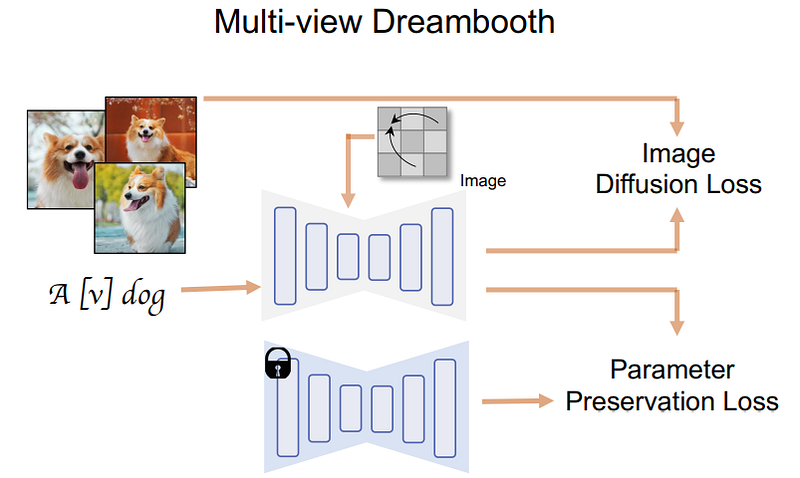
Before entering into the score distillation sampling technique, we need to know about the architecture they are using. In short, it’s just yet another 2D image diffusion model like DALLE, MidJourney, or stable diffusion. More specifically, they started with a pre-trained DreamBooth model, a powerful open-source model to generate images based on stable diffusion.
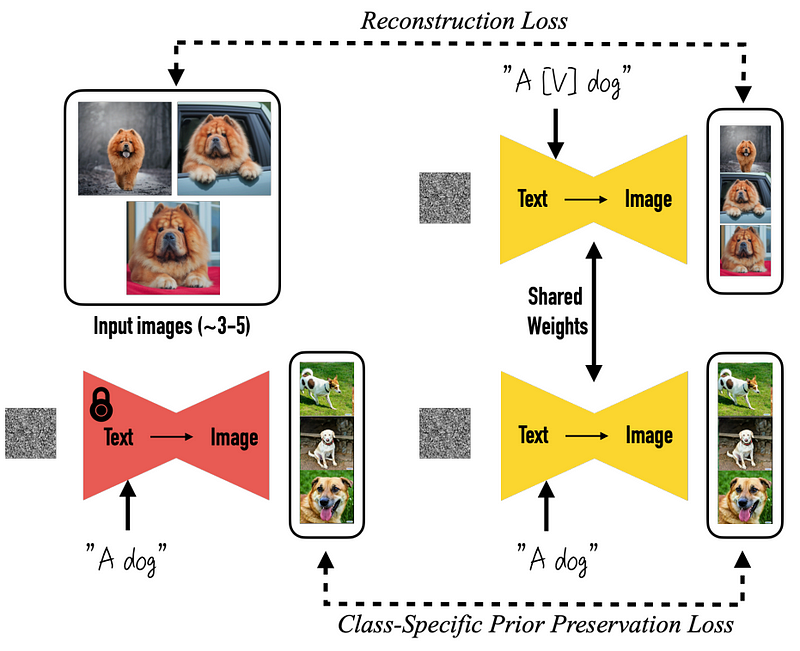
Then, the change they made was to render a set of multi-view images directly instead of only one image, thanks to being trained on a 3D dataset of various objects. Here, we take multiple views from the 3D object that we have in our dataset and use them to train the model to generate them backward. This is done by changing the self-attention block we see here in blue for a 3D one, meaning that we simply add a dimension to reconstruct multiple images instead of one. Below, you can see the camera and timestep that is also being inputted into the model for each view to help the model understand where which image is going and what kind of view needs to be generated. Now, all the images are connected and generated together, so they can share information and better understand the global context. Then, you feed it your text and train the model to reconstruct the objects from the dataset accurately. This is where they apply their multi-view score distillation sampling process.
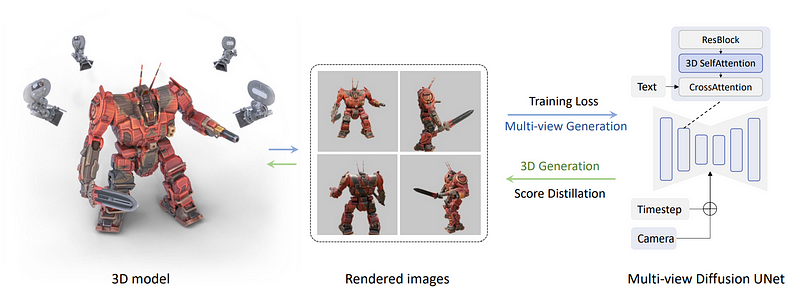
They now have a multi-view diffusion model, which can generate, well, multiple views of an object, but they need it to reconstruct consistent 3D models, not just views. This is often done using NeRF or neural radiance fields, as done with DreamFusion, which we mentioned earlier.
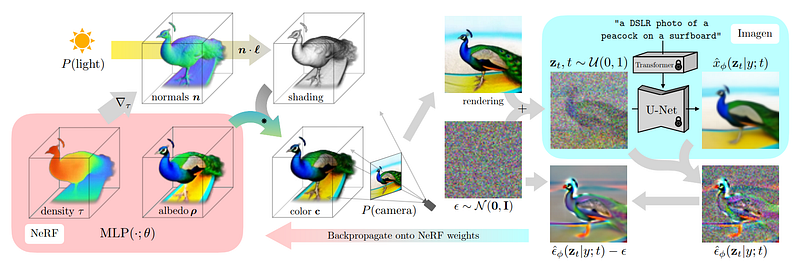
It basically uses the trained multi-view diffusion model that we have and freezes it, meaning that it is just being used and not trained. We start generating an initial image version guided by our caption and initial rendering with added noise using our multi-view diffusion model. We add noise so that the model knows it needs to generate a different version of the image but while still receiving context for it. Then, we use the model to generate a higher-quality image. Add the image used to generate it, and remove the noise we manually added to use this result to guide and improve our NeRF model for the next step. We do all that to better understand where in the image the NeRF model should focus its attention to produce better results in the next step. And we repeat all that until the 3D model is satisfying enough!
And voilà! This is how they took a 2D text-to-image model, adapted it for multi-view synthesis, and finally used it to create a text-to-3D version of the model iteratively! Of course, they added many technical improvements to the approaches they based themselves on, which I did not enter into for simplicity, but if you are curious, I definitely invite you to read their great paper for more information. I also invite you to check out more results in my video or on their project webpage linked below!
There are also still some limitations with this new approach, mainly that the generations are only of 256x256 pixels, which is quite low resolution even though the results look incredible. They also mention that the size of the dataset for this task is definitely a limitation for the generalizability of the approach, following the style from the dataset that is much too small to represent our complex world.
Thank you for watching, and I will see you next time with another amazing paper!
References
- Shi et al., 2023: MVDream, https://arxiv.org/abs/2308.16512
- Project with more examples: https://mv-dream.github.io/
- Code (to come): https://github.com/MV-Dream/MVDream