3D Models from Text! DreamFusion Explained
How AI generates 3d models from only text!


Watch the video
We’ve seen models able to take a sentence and generate images.
Then, other approaches to manipulate the generated images by learning specific concepts like an object or particular style.
Last week Meta published the Make-A-Video model that I covered, which allows you to generate a short video also from a text sentence. The results aren’t perfect yet, but the progress we’ve made in the field since last year is just incredible.
This week we make another step forward.
Here’s DreamFusion, a new Google Research model that can understand a sentence enough to generate a 3D model of it.
You can see this as a DALLE or Stable Diffusion but in 3D.
How cool is that?! We can’t really make it much cooler.
But what’s even more fascinating is how it works. Let’s dive into it.
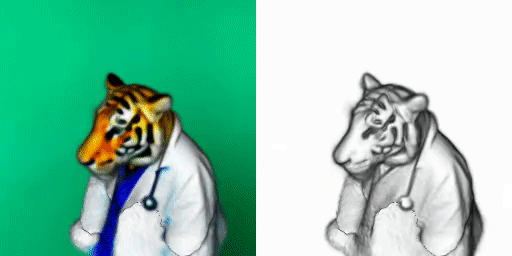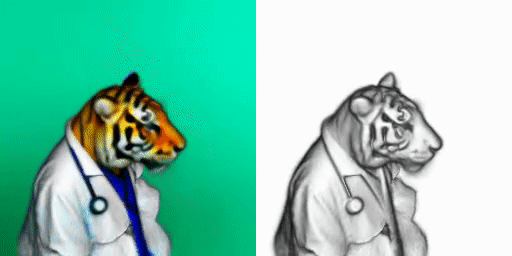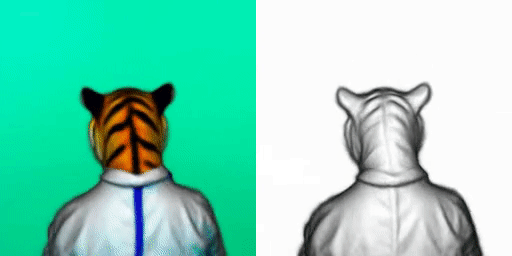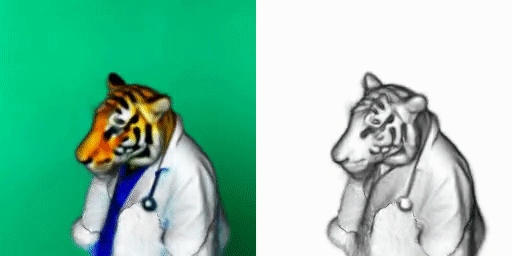
If you’ve been following my work, DreamFusion is quite simple.
It basically uses two models I already covered: NeRFs and one of the text-to-image models. In their case, it is the Imagen model, but any would do, like stable diffusion.
As you know, if you’ve been a good student and watched the previous videos, NeRFs are a kind of model used to render 3D scenes by generating neural radiance fields out of one or more images of an object.

But then, how can you generate a 3D render from text if the NeRF model only works with images?
Well, we use Imagen, the other AI, to generate image variation from the wanted text!
And why do we do that instead of directly generating 3D models from text? Because it would require huge datasets of 3D data along with their associated captions for our model to be trained on, which would be very difficult to have. Instead, we use a pre-trained text-to-image model with much less complex data to gather, and we adapt it to 3D! So it doesn’t require any 3D data to be trained on, only a pre-existing AI for generating images! It’s really cool how we can reuse powerful technologies for new tasks like this when interpreting the problem differently.
So if we start from the beginning: we have a NeRF model.
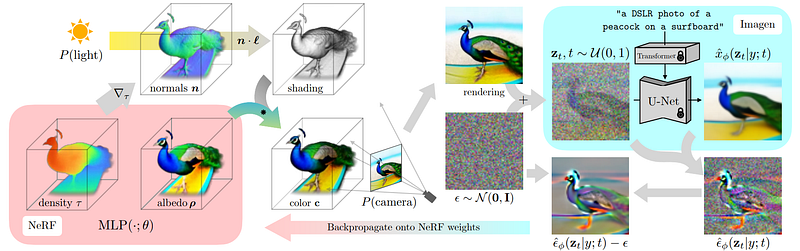
As I explained in previous videos, this type of model takes images to predict the pixels in each novel view, creating a 3D model by learning from image pairs of the same object with different viewpoints. In our case, we do not start with images directly. We start with the text and sample a random view orientation we want to generate. Basically, we are trying to create a 3D model by generating images of all possible angles a camera could cover, looking around the object, and guessing the pixels’ colours, densities, light reflections, etc. Everything needed to make it look realistic.
Thus, we start with a caption and add a small tweak to it depending on the random camera viewpoint we want to generate. For example, we may want to generate a front view, so we would append “front view” to the caption.
On the other side, we use the same angle and camera parameters for our initial, not trained, NeRF model to predict the first rendering.
Then, we generate an image version guided by our caption and initial rendering with added noise using Imagen, our pre-trained text-to-image model, which I further explained in my Imagen video if you are curious to see how it does that.
So our Imagen model will be guided by the text input as well as the current rendering of the object with added noise. Here, we add noise because this is what the Imagen model can take as input. It needs to be part of the noise distribution it understands. Then, we use the model to generate a higher-quality image. Add the image used to generate it, and remove the noise we manually added to use this result to guide and improve our NeRF model for the next step.
We do all that to better understand where in the image the NeRF model should focus its attention to produce better results in the next step.
And we repeat all that until the 3D model is satisfying enough!
You can then export this model to mesh and use it in a scene of your choice!

And before some of you ask, no, you do not have to re-train the image generator model — as they say so well in the paper: it just acts as a frozen critic that predicts image-space edits.
And voilà!
This is how DreamFusion generates 3D renderings from text inputs. If you’d like to have a deeper understanding of the approach, have a look at my videos covering NeRFs and Imagen. I also invite you to read their paper for more details on this specific method.
Thank you for reading the whole article. I invite you to also watch the video at the top of the article to see more examples! I will see you next week with another amazing paper!
References
►Read the full article: https://www.louisbouchard.ai/dreamfusion/
►Poole, B., Jain, A., Barron, J.T. and Mildenhall, B., 2022. DreamFusion: Text-to-3D using 2D Diffusion. arXiv preprint arXiv:2209.14988.
►Project website: https://dreamfusion3d.github.io/
►My Newsletter (A new AI application explained weekly to your emails!): https://www.louisbouchard.ai/newsletter/