

Watch the video
Neural Rendering. Neural Rendering is the ability to generate a photorealistic model in space just like this one, from pictures of the object, person, or scene of interest. In this case, you’d have a handful of pictures of this sculpture and ask the machine to understand what the object in these pictures should look like in space. You are basically asking a machine to understand physics and shapes out of images. This is quite easy for us since we only know the real world and depths, but it’s a whole other challenge for a machine that only sees pixels.

Novel view synthesis using the model (NeROIC). Gif from the project page.
Then, you might ask, why do we want to do this? I’d say that the answer is pretty obvious. To me, there are so many cool applications from having an app that could simply take a few pictures of an object and perfectly synthesize the 3D model to put it in images, in 3D scenes, or even in video games.
This is really promising, but for these models to be realistic, lighting is another challenge that comes with these applications.
It’s great that the generated model looks accurate with realistic shapes, but what about how it blends in the new scene? And what if the lighting conditions vary in the pictures taken and the generated model looks different depending on the angle you look at it? This would automatically seem weird and unrealistic to us. These are the challenges Snapchat and the University of Southern California attacked in this new research.
Now, let’s see how they tackled the lighting and realism challenges that come with creating a virtual object out of images. The technique builds upon neural radiance fields, which are largely used for reconstruction with many models such as NeRF that we already covered in previous articles. Typically, neural radiance fields need images taken in the same ideal conditions but this isn’t what we want here.

NeRF approach. Image from the paper.
Their approach starts with NeRF, and as I said, I already covered it on my channel, so I won’t cover it again, but feel free to take a break and read my article to better understand how NeRF works. In short, NeRF is a neural network that is trained to infer the color, opacity, and radiance of each pixel using the images as inputs and guess the missing pixels for the small parts of the object that aren’t present in the images. But this approach doesn’t work for large missing parts or different lighting conditions as it can only interpolate from the input images. Here, we need something more to extrapolate from it and make assumptions on what should appear here and there or how these pixels should look like under this lighting, etc.
Many approaches build upon NeRF to fix this but always require more inputs from the user, which is not what we want and is hard to have in many cases, especially when we want to build a good dataset to train our model on. In short, these models do not really understand the object nor the environment the object is in.
Camera parameters and NeRF model generation. Image from the paper.
So we always come back to the lighting problem… Here, their goal is to use this architecture in online images. Or, in other words, images with varying lighting, cameras, environments, and poses. Something NeRF can hardly do with realism.
The only few things they will need, other than the images of the object themselves, are a rough foreground segmentation and an estimation of the camera parameters, which can both be obtained with other models available. The foreground estimation is basically just a mask that tells you where the object of interest is on your image, like this:


Image of a TV and its segmentation mask.
What they did differently is that they separate the rendering of the object from the environment lighting in the input images. They focus on two things, which are done in two stages.
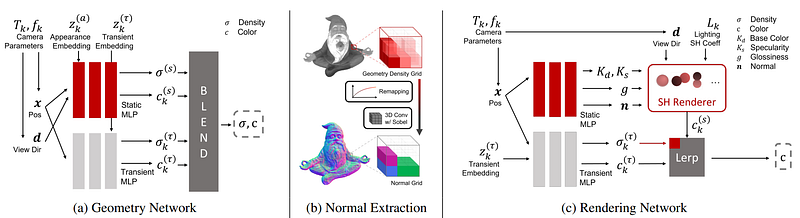
Overview of the model, as we will see below. Image from the paper.
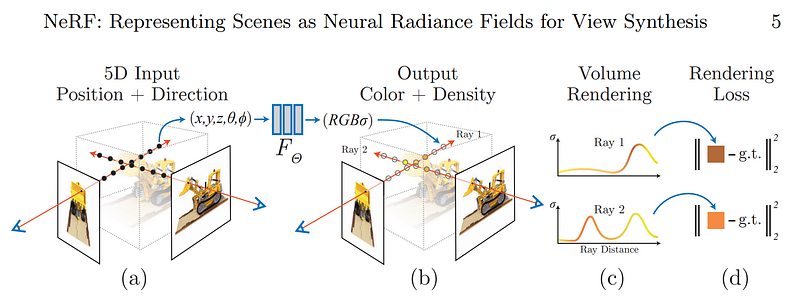
First (a) is the object’s shape, or its geometry, which is the part that is most similar to NeRF, here called the geometry network. It will take the input images, segmentation masks, and camera parameters estimation we discussed, build a radiance field and find a first guess of the density and colors of each pixel, as in NeRF but adapt for varying lighting conditions in the input images. This difference relies on the two branches you see here, splitting the static content from the varying parameters like camera or shadows. This will allow us to teach our model how to correctly isolate the static content from other unwanted parameters like lighting. But we are not finished here.
In (b), we will estimate the surface normals from this learned density field, which will be our textures. Or, in other words, it will take the results we just produce and find how our object will react to light. It will find unbiased material properties of the object at this stage, or at least an estimation of it, using a 3D convolution with a Sobel kernel. It will basically be a filter that we apply in three dimensions to find all edges and how sharp they are, which can look like this on a 2-dimensional image (image below, left) and this on a 3-dimensional rendering (image below, right), giving us essential information about the different textures and shapes of the object.


Sobel filter applied in 2D (left) and surface normal produced using a 3D Sobel filter (right).
The next stage (c) is where they will fix the learned geometry and optimize the normals we just produced using this rendering network, which is very similar to the first geometry network. Here again, there are two branches, one for the material and another for the lighting. They will use spherical harmonics to represent the lighting model and optimize its coefficients during training. As they explain in the paper, with more information if you are interested, spherical harmonics are used here to represent a group of basis functions defined on the sphere surface. We can find on Wikipedia that “each function defined on the surface of a sphere can be written as a sum of these spherical harmonics”. This technique is often used for calculating the lighting on 3D models. It produces highly realistic shading and shadowing with comparatively little overhead. In short, it will simply reduce the number of parameters to estimate but keep the same amount of information.
So instead of learning how to render the appropriate lighting for the whole object from scratch, the model will instead be learning the correct coefficients to use in the spherical harmonics that will estimate the lighting coming out of the surface of each pixel simplifying the problem to a few parameters. The other branch will be trained to improve the surface normals of the object following the same trick using the standard Phong BRDF, which will model the object material properties based on a few parameters to find. Finally, the outputs of the two branches, so the final rendering and lighting will be merged to find the final color of each pixel.
This disentanglement of light and materials is why they are able to apply any lighting to the object and have it react realistically. Remember, this is done using only a couple of images from the internet and could all have different lighting conditions. This is so cool!

And voilà! This is how this new paper from Kuang and collaborators at Snapchat created NeROIC, a neural rendering model for objects from online images!
I hope you enjoyed this short overview of the paper. All the references are linked below as well as the link to the official project, and their code. Let me know what you think of the explanation, the technique, and how you’d use it in the real world!
Thank you for reading, watch the video for more examples!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
References
- Kuang, Z., Olszewski, K., Chai, M., Huang, Z., Achlioptas, P. and Tulyakov, S., 2022. NeROIC: Neural Rendering of Objects from Online Image Collections. https://arxiv.org/pdf/2201.02533.pdf
- Project link with great video demo: https://formyfamily.github.io/NeROIC/
- Code: https://github.com/snap-research/NeROIC
FAQ
What does NeROIC reconstruct?
NeROIC builds a photorealistic neural 3D object from a small collection of ordinary online images.
Why are online image collections difficult to use?
Photos vary in camera, lighting, background, exposure, and object appearance without controlled capture.
Why must a reconstructed object model lighting?
Correct shape alone will not blend naturally into a new scene when illumination and material appearance disagree.
What is the practical benefit of fewer user inputs?
Creators can build usable 3D assets from existing photos without a specialized multi-view scanning session.