
The short version
NLLB-200 is a 2022 multilingual translation system that handles 200 languages in one encoder-decoder model, with particular attention to low-resource languages. Meta built paired data using language identification and sentence mining, then used language conditioning and sparsely gated mixture-of-experts layers to balance transfer and interference. The code, models, and datasets were released, but the reported performance comparisons belong to that 2022 research snapshot.
Watch the video
GPT-3 and other language models are really cool. They can be used to understand pieces of text, summarize them, transcript videos, create text-to-speech applications, and more, but all have a shared big problem: they only work well in English. This language barrier hurts billions of people willing to share and exchange with others without being able to.
Once again, AI can be used for that, too. Meta AI’s most recent model, called “No Language Left Behind” does exactly that: translates across 200 different languages with state-of-the-art quality. You can see it as a broader and more powerful version of google translate.
Indeed, a single model can handle 200 languages. How incredible is that?
We find it difficult to have great results strictly in English while Meta is tackling 200 different languages with the same model, and some of the most complicated and less represented ones that even google translate struggles with. This is a big deal for Facebook, Instagram, and all their applications, obviously, but also for the research community as they open-sourced the code, models, datasets used, and training procedure. A super cool initiative from a big company to advance multi-lingual research.
Typically, using an AI model to translate text requires a huge amount of paired text data, such as French-English translations, so that the model understands how both languages relate to each other and how to go from one to the other, and vice-versa. This means the model requires to see pretty much every possible sentence and text to have good results and generalize well in the real world: something quite impossible for most smaller languages and extremely pricy and complicated to have for most languages at all. We typically train such a model to perform translation from one language to the other, in a single direction, not between 200 languages all at once, requiring a new model each time we want to add a new language.
So how did Meta scale one model to hundreds of languages?
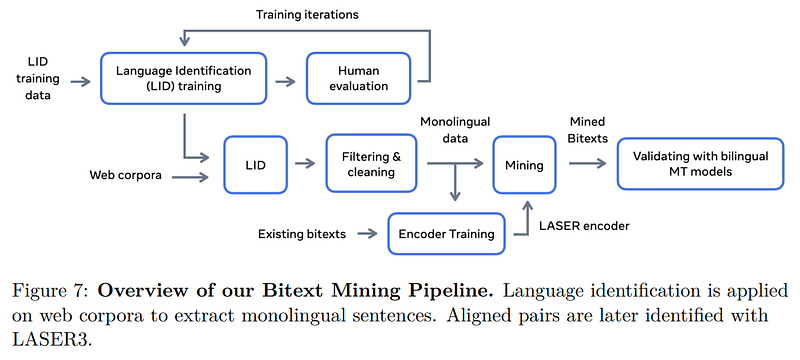
Image from the paper.
First, they built an appropriate data set. Meta created an initial model able to detect languages automatically, which they call their language identification system. It then uses another language model based on Transformers to find sentence pairs for all the scrapped data. These two models are only used to build the 200 paired-languages datasets we need to train the final language translation model: NLLB200.
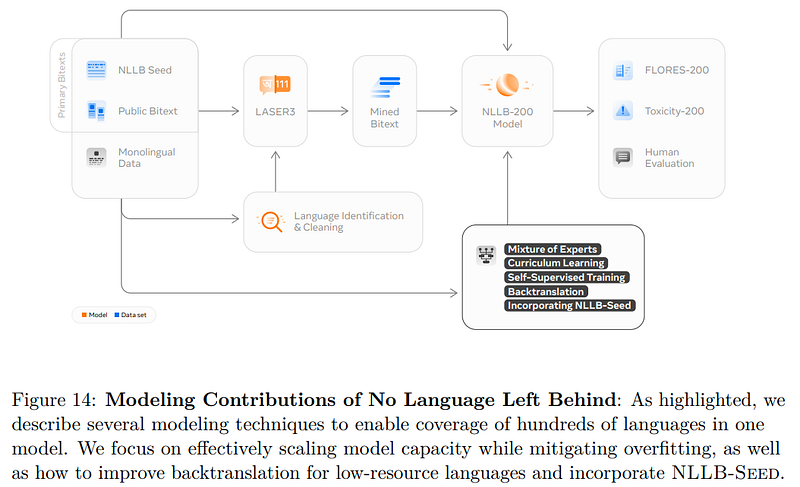
Image from the paper.
Now comes the interesting part: the multi-language translation model. Of course, it is a Transformer based encoder-decoder architecture. This means Meta’s new model is very similar to GPT-3, and takes a text sentence, encodes it in order to decode it, and produces a new text sentence, ideally a translation version of what we sent it.
Image from the paper.
What’s new is the modifications they’ve done to the model to scale up to so many different languages instead of being limited to one. The first modification is adding a variable identifying the source language of the input, taken from the language detector we just discussed. This will help the encoder do a better job for the current input language. Then, we do the same thing with the decoder giving it which language to translate to. Note that this conditioned encoding scheme is very similar to CLIP, which encodes images and text similarly. Here, in ideal conditions, it will encode a sentence similarly whatever the language.
They use Sparsely Gated Mixture of Experts models to achieve a more optimal trade-off between cross-lingual transfer and interference and improve performance for low-resource languages. Sparsely Gated Mixture of Experts are basically regular models but only activate a subset of model parameters per input instead of involving most if not all parameters every time. You can easily see how this is the perfect kind of model for this application. The Mixture of Experts is simply an extra step added in the Transformer architecture for both the encoder and decoder, replacing the feed-forward network sublayer with N feed-forward networks, each with input and output projections, and the Transformer model automatically learns which subnetwork to use for each language during training.
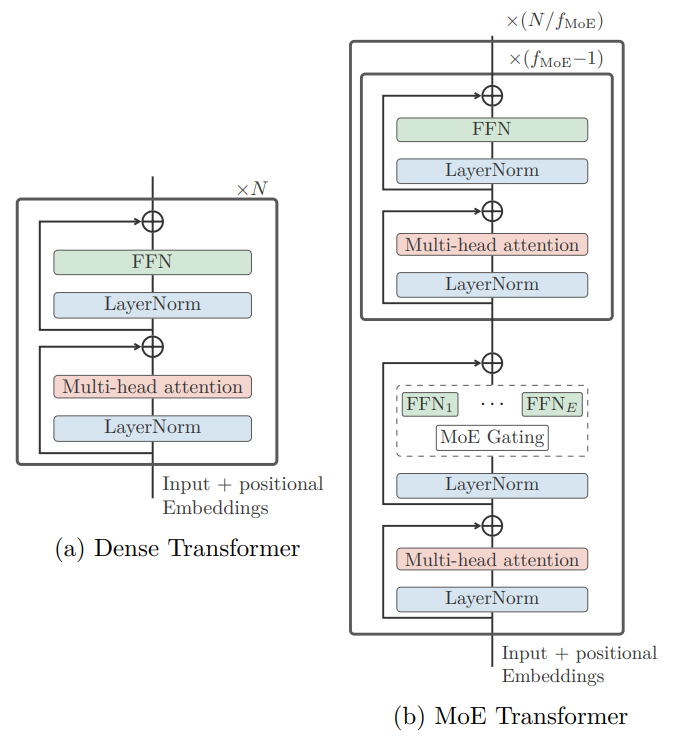
Image from the paper.
They also do multiple small tweaks to the architecture itself. Still, the use of mixture of experts models and source language encodings are certainly the most important changes differentiating this new model from uni-lingual models like GPT-3. I strongly invite you to read their amazing and detailed paper if you are interested in all the internal details of the architecture.
I hope you enjoyed this article, and please let me know if you implement this model yourself or contribute to the multi-lingual research in the comments below. I’ll also take this opportunity to invite you to share your creations or anything you do that involves AI in our Discord community.
Thank you for reading, and I will see you next time, with another amazing paper!
References
►Meta’s Video: https://www.youtube.com/watch?v=uCxSPPiwrNE
►Research paper: https://research.facebook.com/publications/no-language-left-behind
►Code: https://github.com/facebookresearch/fairseq/tree/nllb
►My Newsletter (A new AI application explained weekly to your emails!): /newsletter/
FAQ
What is No Language Left Behind?
NLLB-200 is Meta's multilingual translation model designed to translate directly across roughly 200 languages.
Why are low-resource languages difficult for translation models?
They have fewer high-quality parallel sentences, digital sources, and standardized evaluation datasets.
How were missing language pairs expanded?
Supporting models mined and filtered translated sentence pairs to build the dataset used for NLLB-200.
How does the translation model process a sentence?
It encodes source-language tokens into a representation and decodes that representation into the target language.
Why does one multilingual model help?
Related languages can share learned representations, improving coverage without training a separate system for every pair.