

Watch the video
As if taking a picture wasn’t a challenging enough technological prowess, we are now doing the opposite: modeling the world from pictures. I’ve covered amazing AI-based models that could take images and turn them into high-quality scenes. A challenging task that consists of taking a few images in the 2-dimensional picture world to create how the object or person would look in the real world. You can easily see how useful this technology is for many industries like video games, animation movies, or advertising. Take a few pictures and instantly have a realistic model to insert into your product. The results have dramatically improved upon the first model I covered in 2020, called NeRF. And this improvement isn’t only about the quality of the results. NVIDIA made it even better.
Not only that the quality is comparable, if not better, but it is more than 1’000 times faster with less than two years of research. This is the pace of AI research: exponential gains in quality and efficiency. A big factor that makes this field so incredible. You will be lost with the new techniques and quality of the results if you miss just a couple of days, which is why I first started writing these articles and why you should follow my work! ;) Just look at those 3D models…

Results using Instant Nerf.
These cool models only needed a dozen pictures, and the AI guessed the missing spots and created this beauty in seconds. Something like this took hours to produce with NeRF. Let’s dive into how they made this much progress on so many fronts in so little time.
Inverse Rendering
Instant NeRF attacks the task of inverse rendering, which consists of rendering a 3D representation from pictures, a dozen, in this case, approximating the real shape of the object and how light behaves on it so that it looks realistic in any new scene.
Here NeRF stands for neural radiance fields. I will only do a quick overview of how NeRFs work as I have already covered this kind of network in multiple videos, which I invite you to watch for more detail and a better understanding.

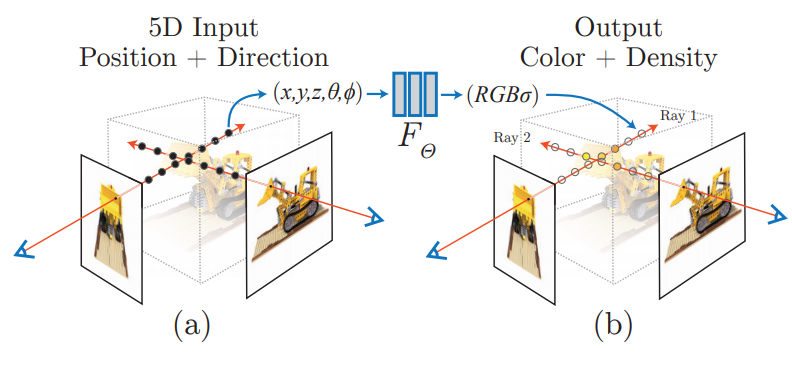
Neural radiance fields. Image from NeRF paper.
Quickly, NeRFs are a type of neural network. They take images and camera settings as inputs and learn how to produce an initial 3D representation of the objects or scenes in the pictures, fine-tune this representation using learned parameters from a supervised learning setting. This means that we need a 3D object and a few images of it at different known angles to train it, and the network will learn to re-create the object. To make the results as best as possible, we need a picture from multiple viewpoints, like the one above, to be sure we capture all, or most, sides of the objects. And we train this network to understand general objects’ shapes and light radiance. We are asking it to learn how to fill the missing parts based on what it has seen before and how light reacts to them in the 3D world.

Results using Instant Nerf.
Basically, it would be like asking you to draw a human without giving any detail on the hands. You’d automatically assume the person has five fingers based on your knowledge. This is easy for us as we have many years of experience behind the belt, and one essential thing current AIs are lacking: our intelligence. We can create links where there are none and do many unbelievable things. On the opposite side, AI needs specific rules, or at least examples to follow, which is why we need to give it what an object looks like in the real world during its training phase to improve.
Then, after such a training process, you only feed the images with the camera angles at inference time, and it produces the final model in a few hours…
Did I say a few hours?
I’m sorry I was still in 2021. It now does that in a few seconds.
This new version by NVIDIA called Instant NeRF is indeed 1’000 times faster than its NeRF predecessor from a year ago. Why? Because of multi-resolution hash grid encoding. Multi what? Multi-resolution hash grid encoding. They explained it very clearly with this sentence;
We reduce this cost with a versatile new input encoding that permits the use of a smaller network without sacrificing quality, thus significantly reducing the number of floating point and memory access operations. [1]
In short, they change how the NeRF network will see the inputs, so our initial 3D model prediction, makes it more digestible and information-efficient to use a smaller neural network while keeping the quality of the outputs the same. Keeping such high quality using a smaller network is possible because we are not only learning the weights of the NeRF network during training but also the way we are transforming those inputs beforehand.
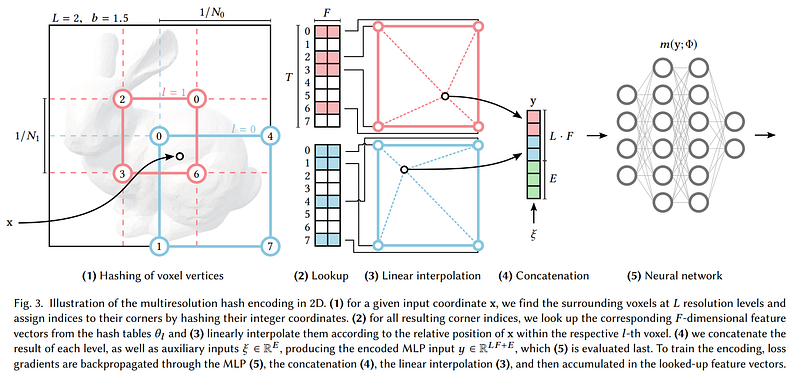
Image from the paper.
So the input is transformed using trained functions, here step 1 to 4, compressed in a hash table to focus on valuable information extremely quickly, and then sent to a much smaller network in step 5 as the inputs are, similarly, much smaller now. They are storing the values of any type in a table with keys indicating where they are stored for super-efficient parallel modifications and removing the lookup time for big arrays during training and inference. This transformation and the much smaller network is why Instant NeRF is so much faster and why it made it into this article.
And voilà! This is how NVIDIA is now able to generate 3D models like these in seconds! Watch more results in the video!
If this wasn’t cool enough, I said that it can store values of any type, which means that this technique can not only be used with NeRFs but also with other super cool applications like gigapixel images that become just as incredibly efficient.

Results using Instant Nerf.
Of course, this was just an overview of this new paper attacking this super interesting task in a novel way. I invite you to read their excellent paper for more technical detail about the multi-resolution hash grid encoding approach and their implementation. A link to the paper and their code is in the references below.
I hope you enjoyed the article, and if you did, please consider supporting my work on YouTube by subscribing to the channel and commenting on what you think of this summary. I’d love to read what you think!
References
- NVIDIA’s blog post: https://blogs.nvidia.com/blog/2022/03/25/instant-nerf-research-3d-ai/
- NVIDIA’s video: https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.mp4
- Paper: Thomas Muller, Alex Evans, Christoph Schied and Alexander Keller, 2022, “Instant Neural Graphics Primitives with a Multiresolution Hash Encoding”, https://nvlabs.github.io/instant-ngp/assets/mueller2022instant.pdf
- Project link: https://nvlabs.github.io/instant-ngp/
- Code: https://github.com/NVlabs/instant-ngp
- My Newsletter (A new AI application explained weekly to your emails!): /newsletter/