OpenAI’s DALL·E: Text-to-Image Generation Explained
OpenAI just released the paper explaining how DALL-E works! It is called “Zero-Shot Text-to-Image Generation”.


It uses a transformer architecture to generate images from a text and base image sent as input to the network. But it doesn’t simply take the image, the text, and sends it to the network. First, in order to be “understood” by the transformer architecture, the information needs to be modeled into a single stream of data. This is because using the pixels of the images directly would require way too much memory for high-resolution images.

Instead, they use a discrete variational autoencoder called dVAE that takes the input image and transforms it into a 32 x 32 grid, giving as a result 1024 image tokens rather than millions of tokens for a high-resolution image. Indeed, the only task of this dVAE network is to reduce the memory footprint of the transformer by generating a new version of the image. Of course, this has some drawbacks, while it saves the most important features, it also sometimes loses fine-grain details, making it impossible to use for fine-grain applications that are based on very precise characteristics of the images. You can see it as a kind of image compressing step. The encoder and decoder in the dVAE are composed of classic convolutions and ResNet architectures with skip connections.
If you never heard of variational autoencoders before, I strongly recommend you to watch the video I made explaining them.
And this dVAE network was also shared in OpenAI’s GitHub, with a notebook to try it yourself, and implementation details in the paper, the links are in the references below!
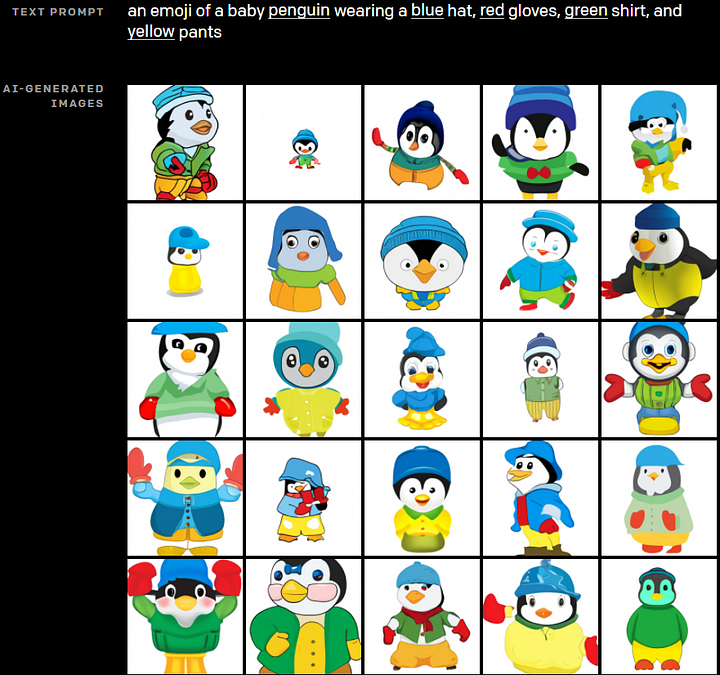
These image tokens produced by the discrete VAE model are then sent with the text as inputs to the transformer model. Again, as I described in my previous video about Dall-E, this transformer is a 12-billion parameter sparse transformer model.
Without diving too much into the transformer’s architecture, as I already covered in previous videos, they are a sequence-to-sequence model that often uses encoders and decoders.
In this case, it only uses a decoder since it takes the generated image by the dVAE and the text as inputs. Each of the 1024 image tokens that were generated by the discrete VAE has access to all text tokens and using self-attention, it can predict an optimal image-text pairing.
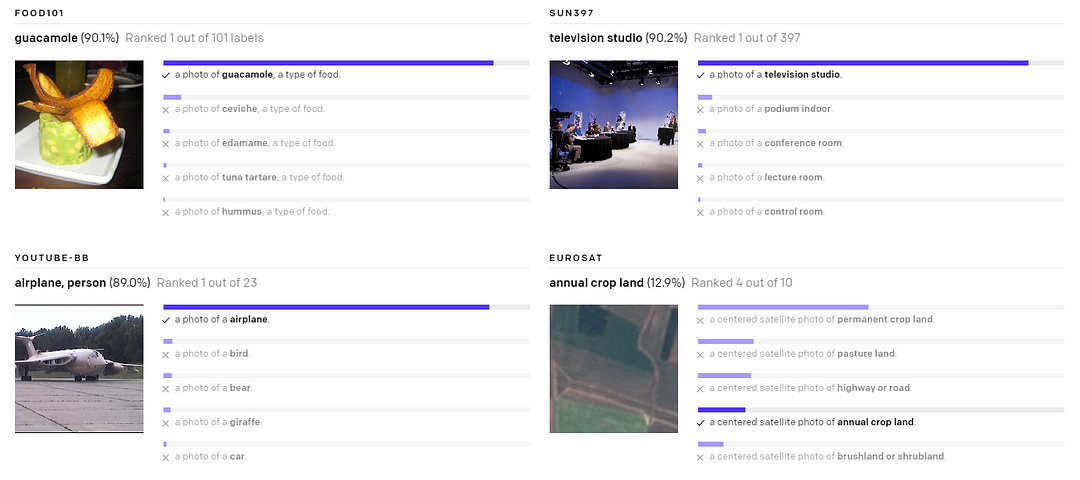
Then, it is finally fed into a pretrained contrastive model. Which is in fact the pretrained CLIP model that OpenAI published in early January. It is used to optimize the relationship between an image and a specific text. Given an image generated by the transformer and the initial caption, CLIP assigns a score based on how well the image matches the caption. The CLIP model was even used on Unsplash images to help you find the image you are looking for as well as finding a specific frame in a video from the text input.
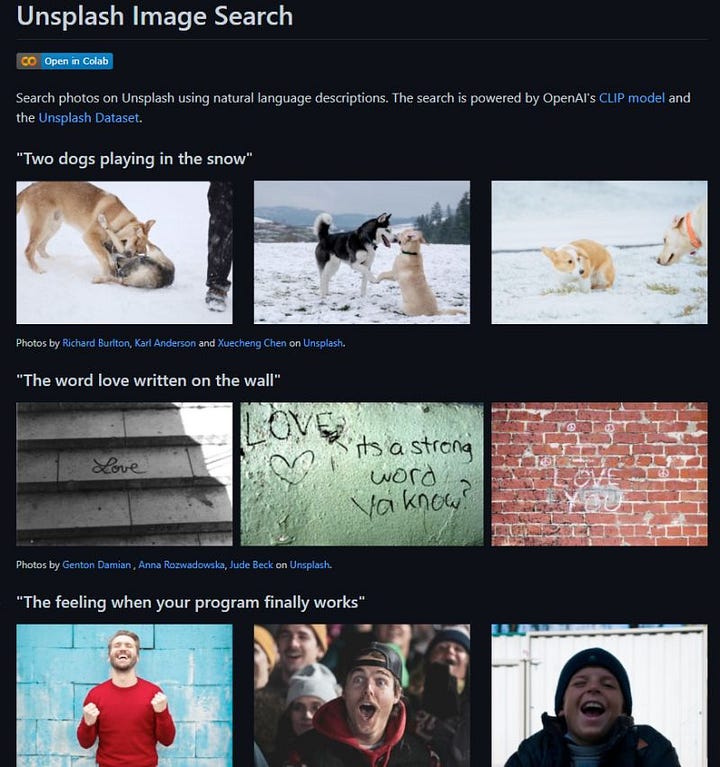
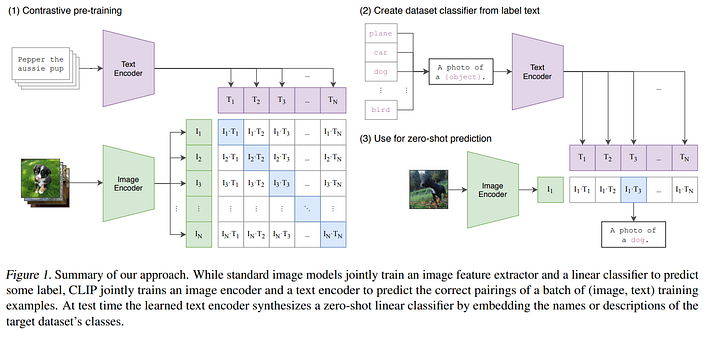
Of course, in our case we already have an image generated and we just want it to match the text input. Well, CLIP still gives us a perfect measure to use as a penalty function to improve the results of the transformer’s decoder iteratively during training. CLIP’s capabilities are very similar to the “zero-shot” capabilities of GPT-2 and GPT-3. Similarly, CLIP was also trained on a huge dataset of 400 million text-image pairs. This zero-shot capability means that it works on image and text samples that were not found in the training dataset, which are also referred to as unseen object categories.

Finally, the overall architecture was trained using 250 million text-image pairs taken from the internet, mostly from Wikipedia and it basically learns to generate a new image based on the given tokens as inputs, just like we described earlier in the article. This was possible because transformers make the use of more parallelization possible during training making it way faster while producing more accurate results, being powerful natural language tools as well as powerful computer vision tools when used with a proper encoding system.
Of course, this was just an overview of this new paper by OpenAI. I strongly recommend reading this Dall-E paper and the CLIP paper to have a better understanding of this approach.
Watch more examples and a complete explanation
If you like my work and want to stay up-to-date with AI technologies, you should definitely follow me on my social media channels.
- Subscribe to my YouTube channel.
- Follow my projects on LinkedIn and here on Medium.
- Learn AI together, join our Discord community, share your projects, papers, best courses, find Kaggle teammates, and much more!
References
- A. Ramesh et al., Zero-shot text-to-image generation, 2021. arXiv:2102.12092 [cs.CV]
- Code & more information for the discrete VAE used for DALL·E: https://github.com/openai/DALL-E
- DALL·E paper: https://arxiv.org/pdf/2102.12092.pdf
- OpenAI CLIP paper & code: https://openai.com/blog/clip/
- CLIP used on Unsplash images search: https://github.com/haltakov/natural-language-image-search