

Watch the video (and hear the results!)
We’ve seen image inpainting, which aims to remove an undesirable object from a picture. The machine learning-based techniques do not simply remove the objects, but they also understand the picture and fill the missing parts of the image with what the background should look like.

Image inpainting example from LaMa.
As we saw, the recent advancements are incredible, just like the results, and this inpainting task can be quite useful for many applications like advertisements or improving your future Instagram post. We also covered an even more challenging task: video inpainting, where the same process is applied to videos to remove objects or people.

Image inpainting example from STTN.
The challenge with videos comes with staying consistent from frame to frame without any buggy artifacts. But now, what happens if we correctly remove a person from a movie and the sound is still there, unchanged? Well, we may hear a ghost and ruin all our work.
This is where a task I never covered on my channel comes in: speech inpainting. You heard it right, researchers from Google just published a paper aiming at inpainting speech, and, as we will see, the results are quite impressive. Okay, we might rather hear than see the results, but you get the point. It can correct your grammar, pronunciation or even remove background noise. All things I definitely need to keep working on, or… simply use their new model… Listen to the examples in my video or in the project’s website!
p.s. there’s also a big surprise at the end of the video that the thumbnail and title may have spoiled, which you surely want to take a look at!
Let’s get into the most exciting part of this article: how these three researchers from Google created SpeechPainter, their speech inpainting model. To understand their approach, we must first define the goal of speech inpainting.
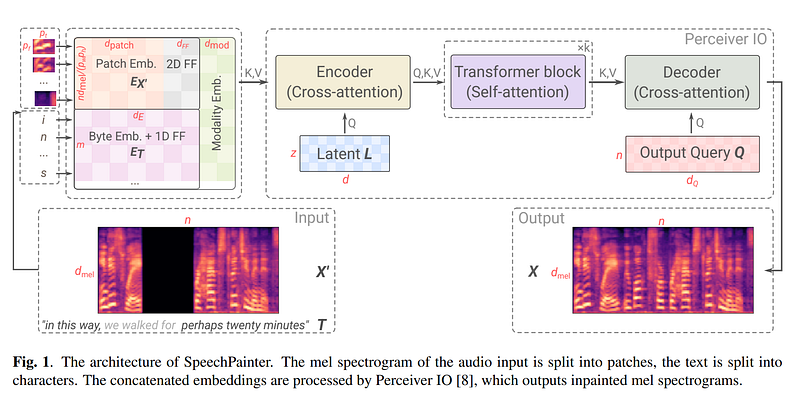
SpeechPainter model based on Perceiver IO. Image from the paper.
Here, we want to take an audio clip and its transcript and inpaint a small section of the audio clip. The text you see on the bottom left is the transcript of the audio track, with the light gray part being removed from the audio clip and inpainted by the network.
The model not only performs speech inpainting, but it does that while maintaining the speaker’s identity and recording environment following a line of text. How cool is that?! Again, take a second to listen to the examples in the video or on the author’s project website!
Now that we know what the model can do, how does it achieve that? As you suspect, this is pretty similar to image inpainting where we replace missing pixels in an image. Instead, we replace missing data in an audio track following a specific transcript. So the model knows what to say and its goal is to fill the gap in the audio track following the text and imitating the person’s voice and overall atmosphere of the track to feel real.
SpeechPainter model based on Perceiver IO. Image from the paper.
Since image and speech inpainting are similar tasks, they will use similar architectures. They used a model called Perceiver IO, shown above. It will do the same as with an image where you would encode your image, extract the most useful information and performs modifications, and decode it to reconstruct another image with what you want to achieve. In the inpainting example, the new image would simply be the same but with some pixels changed.
In this case, instead of pixels coming from an image, the Perceiver IO architecture can work with pretty much any type of data, including mel spectrograms, which are basically our voiceprints representing our audio track using frequencies. Then, this spectrogram and the text transcript are encoded, edited, and decoded to replace the gap in the spectrogram with what should appear. As you see above, this is just like generating an image, and we use the same process as in image inpainting, but the output and input data are spectrograms, or, basically, images of the soundtrack.
If you are interested in learning more about the Perceiver IO architecture, I’d strongly recommend watching Yannic Kilcher’s video about it.
They trained their model on a speech dataset, creating random gaps in the audio tracks and trying to fill in the gaps. Then, they used a GAN approach for training to further improve the realism of the results.
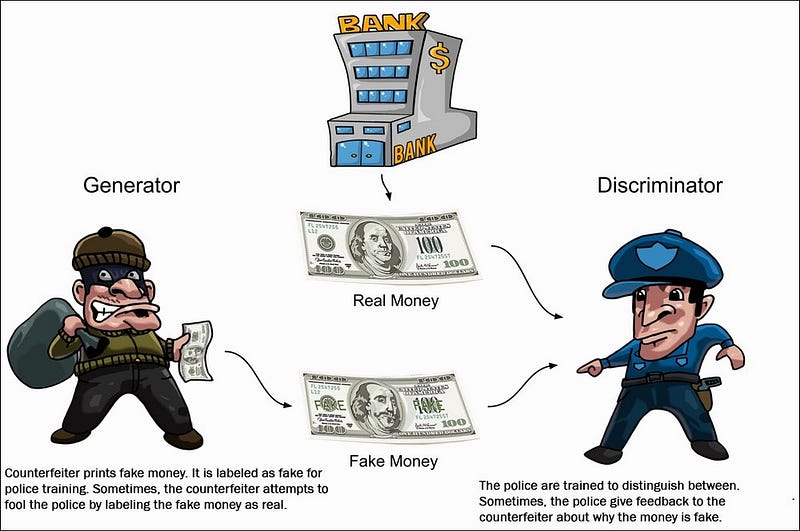
Generator and Discriminator clearly explained. Image from Packt; Principles of GANs.
Quickly, with GANs, there will be the model we saw, called a generator, and another model called a discriminator. The generator will be trained to generate the new data, in our case, the inpainted audio track. Simultaneously, the discriminator will be fed samples from the training dataset and generated samples and will try to guess if the sample was generated, called fake, or real from the training set. Ideally, we’d want to have our discriminator be right half of the time so that it basically chooses randomly, meaning that our generated samples sound just like a real one. The discriminator will then penalize the generator model in order to make it sound more realistic.
And voilà! You end up with a model that can take speech and its transcript to correct your grammar or pronunciation or even fill in gaps following your voice and track’s atmosphere. This is so cool.
So you just have to train this model once on a general dataset and then use it with your own audio tracks as it should, ideally, be able to generalize and work quite well! Of course, there are some failure cases, but the results are pretty impressive, and you can listen to more examples on their project page linked below.
Thank you for reading, watch the video to hear the examples!
Register to GTC22 for free (don’t forget to leave a comment and subscribe to enter the giveaway, steps in the video!): https://nvda.ws/3upUQkF
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
References
- Borsos, Z., Sharifi, M. and Tagliasacchi, M., 2022. SpeechPainter: Text-conditioned Speech Inpainting. https://arxiv.org/pdf/2202.07273.pdf
- Listen to all the examples: https://google-research.github.io/seanet/speechpainter/examples/