

The short version
StyleCLIP edits a StyleGAN image from a natural-language instruction by using CLIP to connect words with directions in the generator’s latent space. For a real photograph, the method first encodes the face into that space, then changes the requested attribute while trying to preserve identity and unrelated details. This is a 2021 research method, so read it as historical work.
Watch the video and support me on YouTube:
Researchers used AI to generate images. Then, they could leverage it to take an image and edit it following a specific style, like changing it into a cartoon character or transforming any face into a smiling face. This needed a lot of tweaking and model engineering and many trials and errors before achieving something realistic. There have been many advances in this field, mainly StyleGAN, which has the incredible ability to generate realistic images in pretty much any domain; real-life humans, cartoons, sketches, etc.

StyleGAN application examples I covered in previous articles
StyleGAN is amazing, but it still needs quite a lot of work to make the results look as intended, which is why many people are trying to understand how these images are made, and especially how to control them. This is extremely complicated as the representation in which we edit the images is not human-friendly. Instead of being regular images with three dimensions, red, greed, and blue, it is extremely dense in information and therefore contains hundreds of dimensions with information about all the features the image may contain. This is why understanding and localizing the features we want to change to generate a new version of the same image requires so much work. The keywords here are “of the same image.” The challenge is to edit only the wanted parts and keep everything else the same. If we change the colors of the eyes, we want all other facial features to stay the same.
I recently covered various techniques where the researchers tried to make this control much easier for the user by using only a few image examples or quick sketches of what we want to achieve.
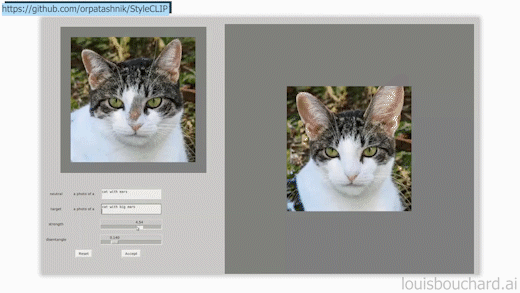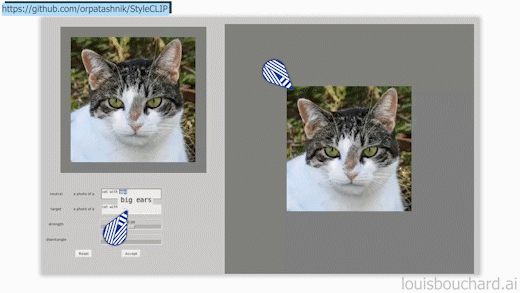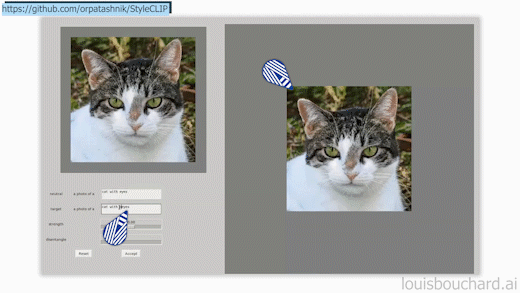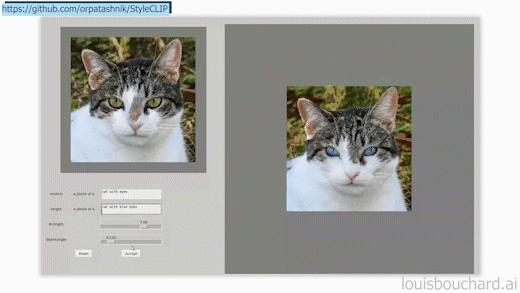
StyleCLIP GUI example, available on StyleCLIP’s GitHub.
Now, you can do that using only text. In this new paper, Or Patashnik et al. created a model able to control the image generation process through simple text input. You can send it pretty much any face transformation and using StyleGAN and CLIP. It will understand what you want and change it.
Then, you can tweak some parameters to have the best result possible, and it takes less than a second.
I mentioned StyleGAN. StyleGAN is NVIDIA’s state-of-the-art GAN architecture for image synthesis or image generation. I made a lot of videos covering it in various applications that you should definitely watch if you are not familiar with it.
(left) CLIP examples from OpenAI’s blog and (right)Unsplash Image Search using CLIP.
Before entering in the details, the only thing left to cover is the other model I talked about that StyleGAN is combined with, which is CLIP. Quickly, CLIP is a powerful language to image model recently published by OpenAI. As we will see, this model is the one in charge of controlling the modifications to the image using only our image and text input. It was trained on a lot of image-text pairs from the Web and can basically understand what appears in an image. Since CLIP was trained on such image-text pairs, it can efficiently match a text description to an existing image. Thus, we can use this same principle in our current model to orient the StyleGAN-generated image to the desired text transformation. You should read OpenAI’s Distill article if you’d like to learn more about CLIP. It is linked in the references below. It has been used to search specific images on Unsplash from text input and other very cool applications. It will become very clear soon how CLIP can be useful in this case. By the way, if you find this interesting, take a second to share the fun and send this article to a friend. It helps a lot!
As I said, the researchers used both these already trained models, StyleGAN and CLIP, to make this happen. Here’s how…
It takes an input image, such as a human face in this case. But it can also be a horse, a cat, or a car… Anything that you can find a StyleGAN model trained on such images with sufficient data. Then, this image is encoded into a latent code using an encoder, just like this, here called w.
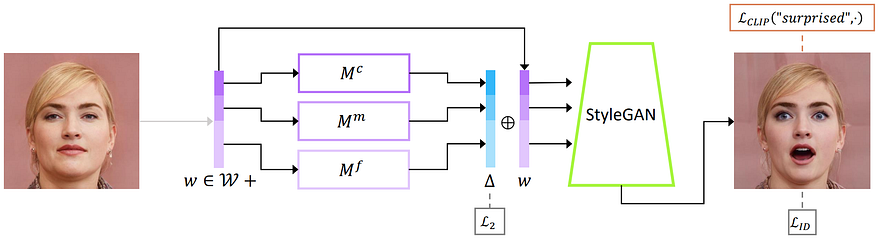
StyleCLIP mapping model. Image from Patashnik, Or, et al., (2021), “Styleclip”.
This latent code is just a condensed representation of the image produced by a convolutional neural network. It contains the most useful information about the image which have been identified during the training of the model.
If this is already too complicated, I’d strongly recommend pausing your reading and watch the short 1-minute video I made covering GANs where I explain how the encoder part typically works.

This latent code, or new image representation, is then sent into three mapper networks that are trained to manipulate the desired attributes of the image while preserving the other features. Each of these networks is in charge of learning how to map a specific level of detail, from coarse to fine, which is decided when extracting the information from the encoder at different depths in the network, as I explained in my GAN video. This way, they can manipulate general or fine features individually. This is where the CLIP model is used to manipulate these mappings. Because of the training, the mappings will learn to move accordingly to the text input as the CLIP model understands the content of the images and encode the text in the same way as the image is encoded. Thus, CLIP can understand the translations made from a text to another, like “a neutral face” to “a surprised face,” and tell the mapping networks how to apply this same transformation to the image mappings. This transformation is the delta vector here that is controlled by CLIP and applies this same relative translations and rotations to the latent code w, as what happened for the text. Then, this modified latent code is sent in the StyleGAN generator to create our transformed image.
StyleCLIP mapping model. Image from Patashnik, Or, et al., (2021), “Styleclip”.
In summary, the CLIP model understands the changes happening in a sentence, like “a neutral face” to “a surprised face,” and they apply the same transformation to the encoded image representation. This new transformed latent code is then sent to the StyleGAN generator to generate the new image.
And Voilà! This is how you can send an image and change it based on a simple sentence with this new model. They also made a google colab and a local GUI to test it for yourself with any image and play with it easily using sliders to control the modifications intuitively.
Of course, the code is available on GitHub as well. The only limitation for this is that you have to train the mapping networks, but they also attacked this issue in their paper. For a deeper understanding of how it works and to see these two other techniques, they introduced to control image generation with CLIP without any training needed. I’d strongly recommend reading their paper. It is worth the time! All the links are in the references below.
Thank you for reading!
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References:
- Patashnik, Or, et al., (2021), “Styleclip: Text-driven manipulation of StyleGAN imagery.”, https://arxiv.org/abs/2103.17249
- Code (use with local GUI or colab notebook): https://github.com/orpatashnik/StyleCLIP
- Demo: https://colab.research.google.com/github/orpatashnik/StyleCLIP/blob/main/notebooks/StyleCLIP_global.ipynb
- OpenAI’s Distill article for CLIP: Gabriel Goh, Nick Cammarata, Chelsea Voss, Shan Carter, Michael Petrov, Ludwig Schubert, Alec Radford, and Chris Olah. Multimodal neurons in artificial neural networks. Distill, https://distill.pub/2021/multimodal-neurons/, 2021.
FAQ
What does StyleCLIP do?
StyleCLIP edits a StyleGAN-generated or encoded face using a natural-language description of the desired change.
How does text control the visual edit?
CLIP provides a direction connecting the requested language with changes in the generator's latent representation.
Can StyleCLIP modify a real photograph?
A real image must first be encoded into StyleGAN's latent space before text-guided manipulation.
Why are some edits easier than others?
The generator can only manipulate concepts represented well in its training data and latent space.
What should a controlled edit preserve?
It should change the named attribute while keeping identity, pose, background, and unrelated features as stable as possible.