

The short version
Enhancing Photorealism Enhancement transformed GTA V frames toward a real-world appearance using both the rendered image and game-engine buffers such as depth, surface normals, materials, lighting, transparency, and segmentation. The 2021 system encoded those signals, combined them with the image, and trained against real Cityscapes data. The post presents an early live frame-by-frame demonstration, not a current survey of game rendering.
[Watch the video at the end of this article to see more examples!]

GTA5 Gameplay. Richter, Abu AlHaija, Koltun (2021)
What you see here is the gameplay of a very popular video game called GTA 5. It looks super realistic, but it is still obvious that this is a video game. Now, look at this..

GTA5 Gameplay Enhanced. Richter, Abu AlHaija, Koltun (2021)
No, this is not real life. It is still the same GTA5 gameplay that went through a new model using artificial intelligence to enhance its graphics and make it look more like the real world! The researchers from Intel Labs just published this paper called Enhancing Photorealism Enhancement. And if you think that this may be “just another GAN,” taking a picture of the video game as an input and changing it following the style of the natural world, let me change your mind. They worked on this model for two years to make it extremely robust. It can be applied live to the video game and transform every frame to look much more natural. Just imagine the possibilities where you can put a lot less effort into the game graphic, make it super stable and complete, then improve the style using this model. I think this is a massive breakthrough for video games, and this is just the first paper attacking this same task applied specifically to video games! I want to ask you a question that you can already answer or wait until the end of the video to answer: Do you think this is the future of video games?
If you want more time to answer, that’s perfect, let’s get into this technique. In general, this task is called image-to-image translation (see below). You take an image and transform it into another, often using GANs, as I covered numerous times in my previous articles.

Classic image-to-image translation examples.
If you want an overview of how a typical GAN architecture works, I invite you to check out this video below before continuing as I won’t get into the details of how it works here.
As I said earlier, this model is different than basic image-to-image translation as it uses the fact that it is applied to a video game. This is of enormous importance here as video games have much more information than a simple picture, so why make the task more complicated by achieving realistic transformations using only the snapshot as input?

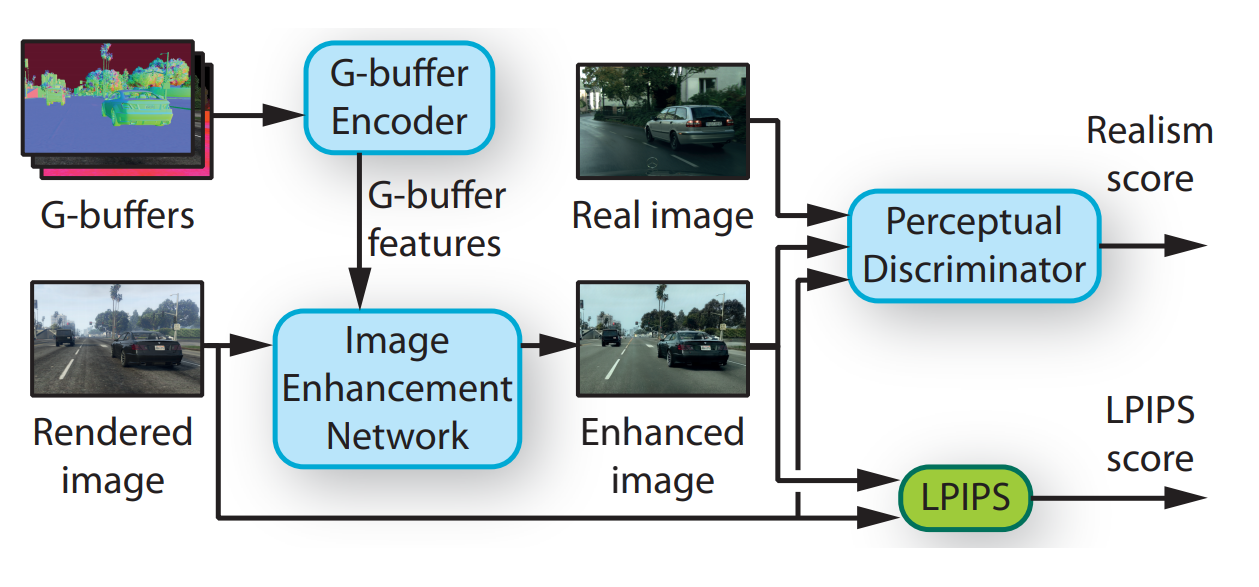
Instead, they use much more information already available for each image of the game like the surface normals, depth information, materials, transparency, lighting, and even a segmentation map which tells you what and where the objects are. I’m sure you can already see how all this additional information can help with this task. All these images are sent to a first network called the G-buffer Encoder (see below).
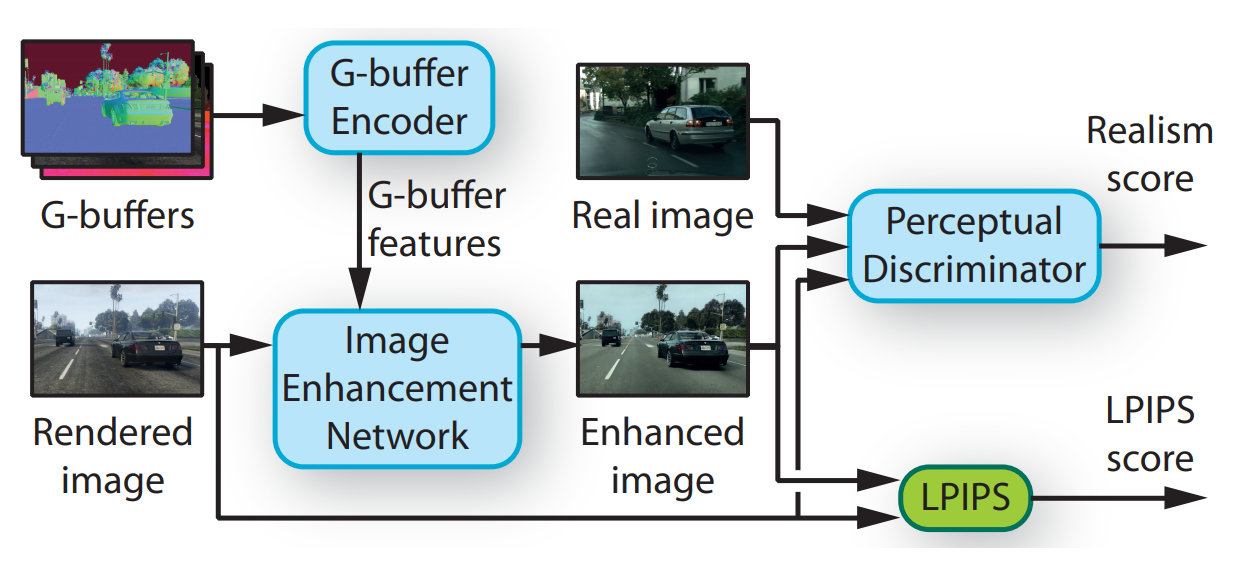
The overall EPE model. Richter, Abu AlHaija, Koltun (2021)
Let’s zoom into this “G-buffer Encoder”:
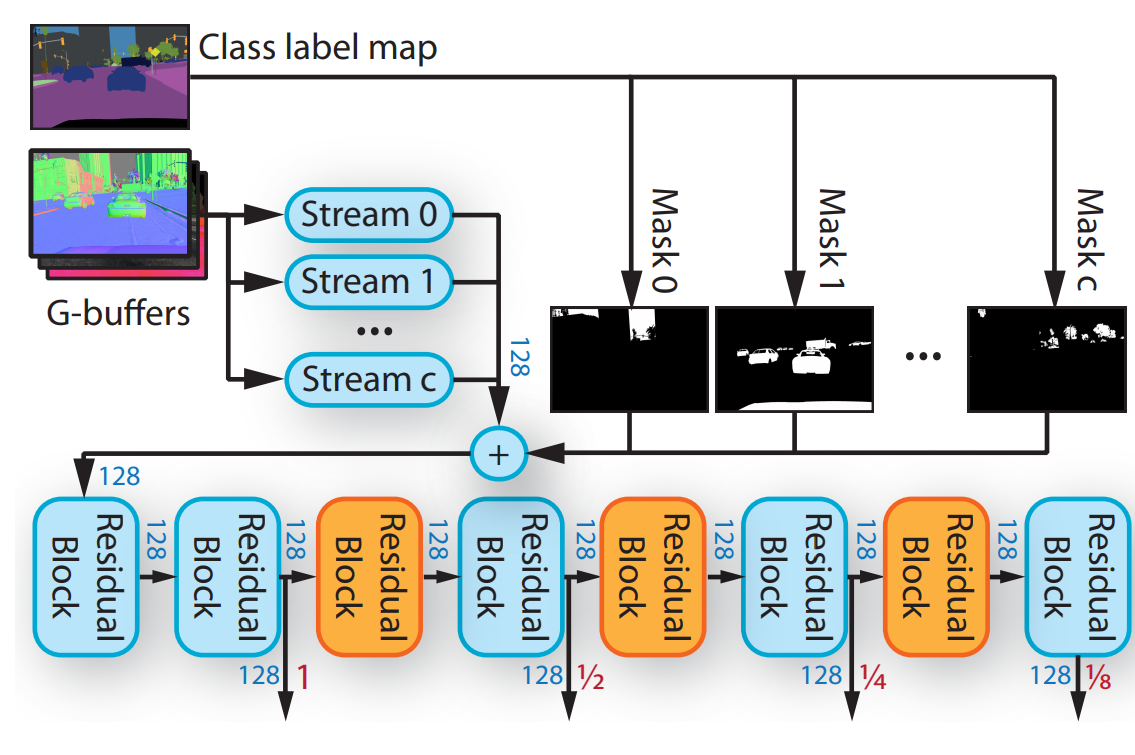
The G-Buffer network. Richter, Abu AlHaija, Koltun (2021)
This G-buffer encoder takes all this information, sends it into a classic convolutional network independently to extract and condense all the valuable information from these different versions of the initial image. This is done using multiple residual blocks, as you can see here, which is basically just a convolutional neural network architecture, and more precisely, a ResNet architecture. The information is extracted at multiple steps, as you can see. This is done to obtain information at different stages of the process. Early information is vital in this task because it gives more information regarding the spatial location and has the smaller details information. In comparison, deeper information is essential to understand the overall image and its style. A combination of both early and deep information is thus very powerful when used correctly!
Then, all this information here, referred to as the G-buffer features (see the full model 2 images above), is sent to another network with the original image from the game called the rendered image. This other model is called the “Image Enhancement Network”, as shown in the full architecture above, let’s zoom into this one as well.
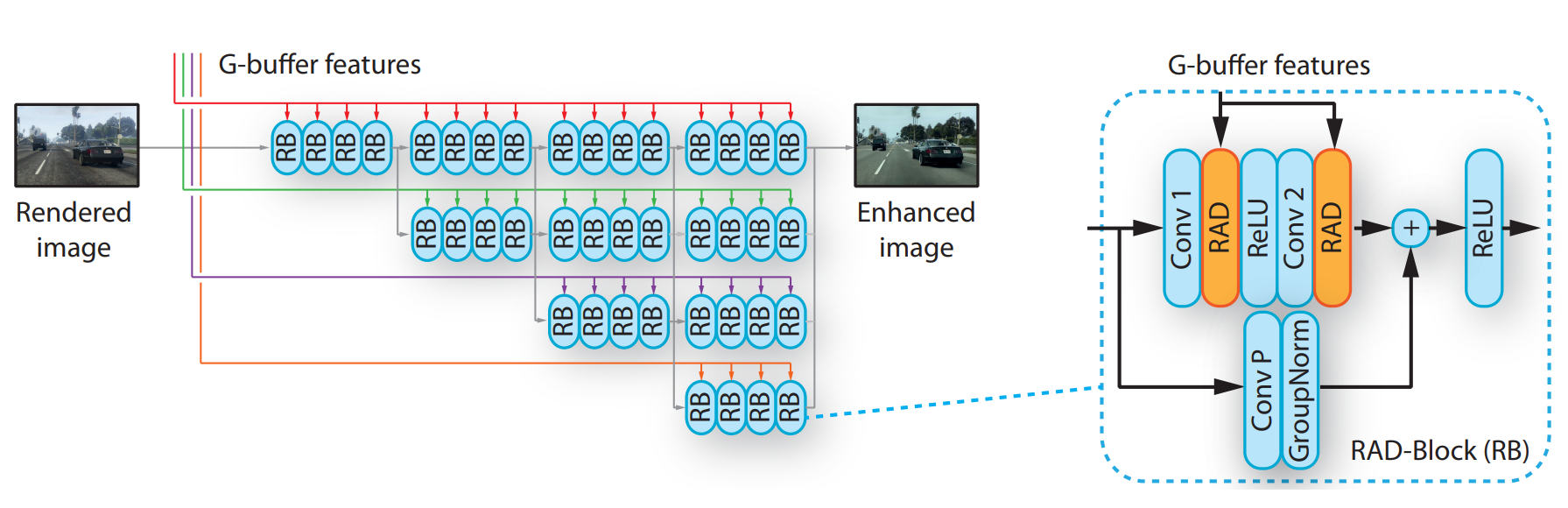
The Image Enhancement network. Richter, Abu AlHaija, Koltun (2021)
You can see the different colors representing the G-buffer information extracted from different scales as we previously saw, with the gray arrow showing the process for the actual image. Here again, you can see this as an enhanced version of the same residual blocks as for the g-buffer encoder repeated multiple times, but with a little tweak to better adapt the G-buffer information before being added to the process. This is done using what they refer to as RAD here, which is again residual blocks, convolutions, and normalization.
The overall EPE model. Richter, Abu AlHaija, Koltun (2021)
As I mentioned, this architecture is a bit more complicated than a simple encoder-decoder architecture like regular GAN. Similarly, the training process is also more elaborated. Here, you can see two metrics, the realism score, and the LPIPS score.

GTA5 vs the Real-life dataset used: Cityscapes. Richter, Abu AlHaija, Koltun (2021)
The realism score is basically the GAN section of the training process. It compares both a similar real-world image to a game image and compares the real image to an enhanced game image. Helping the model to learn how to produce a realistic and enhanced version of the game image sent.

GTA5 Gameplay Enhanced. Richter, Abu AlHaija, Koltun (2021)
Whereas this LPIPS component is a known loss used to retain the structure of the rendered image as much as possible. This is achieved by giving a score based on the difference between the associated pixels of the rendered image versus the enhanced image. Penalizing the network when it generates a new image that spatially differs from the original image. So both these metrics work together to improve the overall results during the training of this algorithm.
Of course, as always, you need a large enough dataset of the real world and of the game as it won’t generate something that the model has never seen before.
And now, do you think this kind of model is the future of video games? Has your opinion changed after seeing this video?
Thank you for reading!
Watch more examples in the video:
Come chat with us in our Discord community: Learn AI Together and share your projects, papers, best courses, find Kaggle teammates, and much more!
If you like my work and want to stay up-to-date with AI, you should definitely follow me on my other social media accounts (LinkedIn, Twitter) and subscribe to my weekly AI newsletter!
To support me:
- The best way to support me is by being a member of this website or subscribe to my channel on YouTube if you like the video format.
- Support my work financially on Patreon
References
Richter, Abu AlHaija, Koltun, (2021), “Enhancing Photorealism Enhancement”, https://isl-org.github.io/PhotorealismEnhancement/
FAQ
What is photorealism enhancement for games?
It transforms rendered game frames toward real-world appearance while using information available from the game engine.
Why use engine buffers instead of only the screenshot?
Depth, object labels, and geometry provide structure that would be difficult to infer from pixels alone.
Can the model run on live gameplay?
The research targets frame-by-frame transformation, although production speed and consistency remain practical constraints.
What training data does the approach require?
It needs enough game imagery and relevant real-world examples to learn the desired appearance mapping.
Will AI automatically make every game photorealistic?
No. Unseen content, temporal artifacts, performance cost, and artistic direction still limit automatic enhancement.