Revolutionizing Online Shopping: AI's Virtual Try-On Experience
AI Does magic with UNets, Diffusion, and clothes!


Watch the video!
Have you ever dreamed of trying out the clothes even when you are shopping on Amazon?
This may sound like magic, but it’s actually something becoming more and more possible thanks to AI. As with ChatGPT, MidJourney, and many other AI-powered tools that look like magic and real intelligence, some AIs are trained to take an image of you, and add any piece of clothing to it. I covered a great research approach that was the first doing this virtual Try-on task a few years ago called VOGUE. VOGUE had great results, but it was far from perfect and mostly worked with clothing and people seen in its training data. So it’s not really usable commercially since you want to allow anyone to upload an image of themselves and see the fit of a t-shirt. Fortunately for us, many companies and researchers like Luyang Zhu et al. from Google Research are still working on this task, and it is now better than ever with a new approach called TryOnDiffusion that was just published at the CVPR 2023 conference.

This virtual try-on task is maybe the commercial use of generative AIs that we can most easily understand, but it is also one of the most challenging use cases. You need to understand the world’s physics almost perfectly and respect the person’s body shape and the clothes textures and features to accurately display it and not face a reimbursement or unsatisfied client. Where is the use of such an AI if you still have to return the shirt because it didn’t fit properly and looked different on the site? It has to be almost perfect. TryOnDiffusion still hasn’t reached perfection, but it is the closest AI for a realistic virtual try-on yet. As you’ve seen since the beginning of the video, the results are fantastic, but what’s even cooler is how it works…
But first, if you enjoy AI-related content and would like some help falling asleep at night or something to listen to while commuting, I’d like to recommend my podcast What’s AI by Louis Bouchard. You can find it on any streaming platform like Spotify or Apple podcast or even here on youtube if you subscribe to the channel. I share a new episode every week with an expert in the field to dive into their passion, sharing lots of amazing insights related to AI but also often applied to your life too and any industry. For example, last week, I had the chance to talk to Luis Serrano, my favorite online AI educator, and he shared amazing tips to improve your communication and teaching skills.
It’s also perfectly fine if you are not into podcasts and just want to understand how the TryOnDiffusion model works. Let’s dive into it!
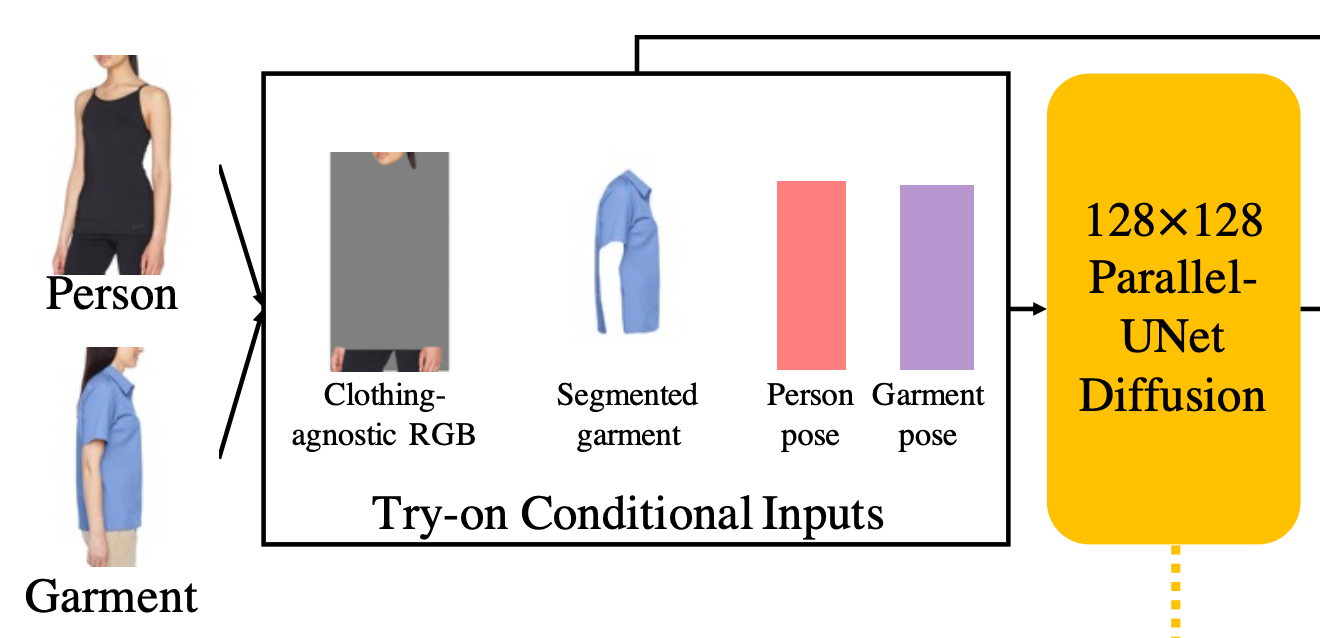
First, we need to know what we have and what we want for this problem. We have a picture of us and a piece of clothing we want to try out virtually. What we want is a realistic, high-quality picture of us with the new piece of clothing, like this.
Then what do we do from there? We need to train a model that can understand both input images and differentiate the clothing from the person. In our case, we want to isolate the clothing and accurately put it on the first image. So before everything, we need a segmentation model that is already trained, like the Segment Anything Model by Meta example. Then we run it on both our person and garment image and extract only the clothing we want from the image. We completely remove it for the person’s image to know what’s to generate, here called the clothing-agnostic image, and we save it for the garment image for generation, referred to as the segmented garment. Now, how do we take this piece of clothing and add it to our new clothing-agnostic image?
Well, with no surprise, it is with a U-Net model, so a model that encodes an image into a lower resolution and then reverts it back to a new image. Here, it is a diffusion-based U-Net, which I introduced in previous videos if you are not familiar with the diffusion process. Quickly, diffusion models work by taking data and adding random noise to it iteratively until it becomes super blurry and unrecognizable. Then, we train a model to revert this process. It’s much more stable and produces better results than GANs, which is why you see them everywhere now. So the model basically takes noise, or images with random pixels, and has learned to apply more noise, but the right ones, to ultimately create a real image. You can see this as learning something like a tennis serve. You’ll just repeat the movement over and over again, starting pretty randomly until you finally hit it inside the field. Then, you continue your practice with more serves that are in but adding strength. It’s all quite random but always based on what you just did, so in the end, it’s not really random. Here, it’s the same iterative process but on images where you progressively converge towards an image as you would converge towards a perfect 150 miles per hour serve! We use a UNet to first encode the information into a smaller and more manageable representation for working and combining information before reconstructing the final image.
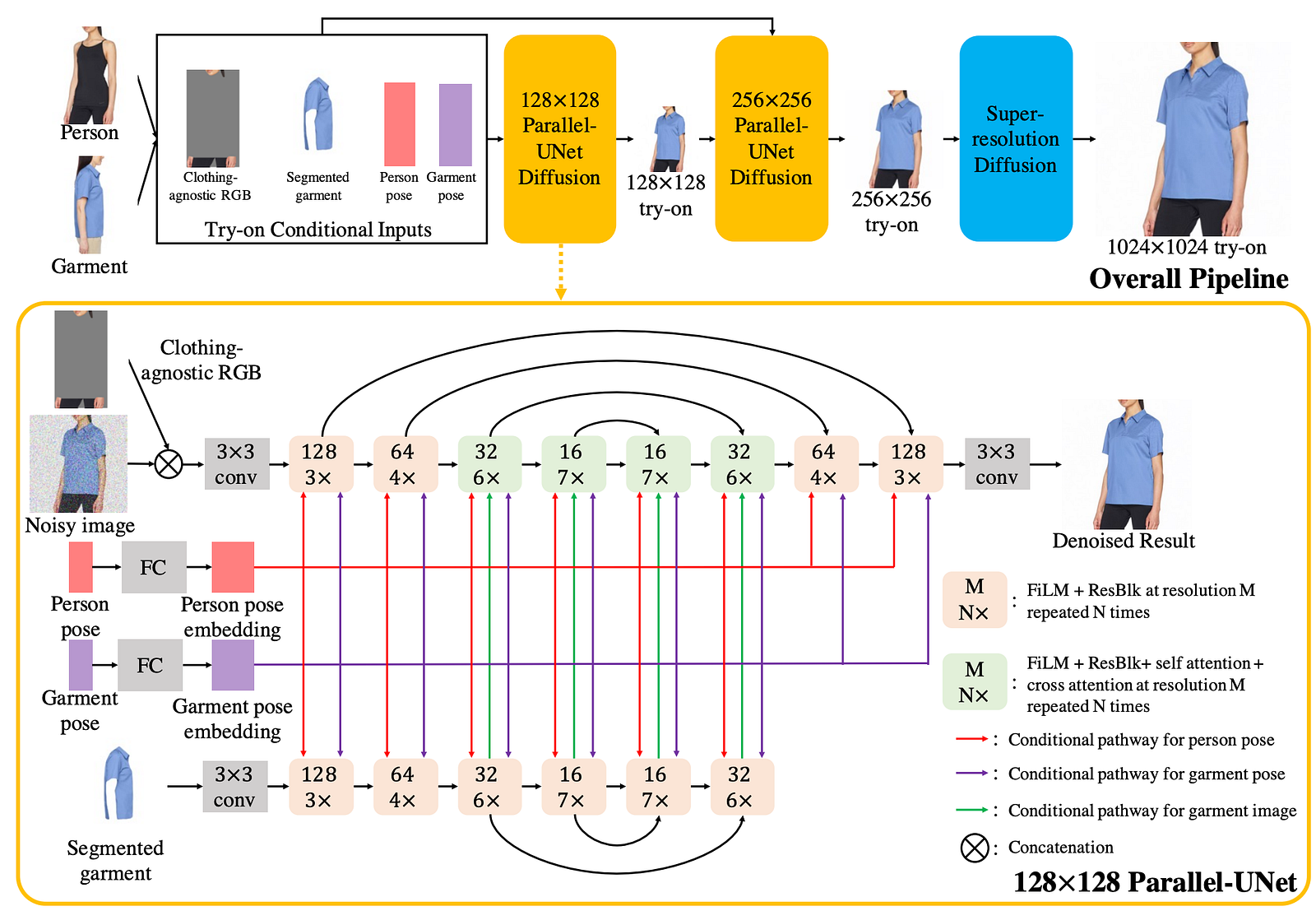
And more precisely, they called it the Parallel-UNet, which is their main contribution of the paper. Here’s where the magic happens. It is composed of two UNets, as the name Parallel-UNet suggests. The first one takes both a noisy initial image and our clothing-agnostic image and encodes them. Then, we use a second UNet only for the segmented garment we have. Finally, we combine both pieces of information and add our poses into the first UNet for reconstructing the final image.

So it will take the encoded version of all our person and garment information and combine them using the attention mechanism, which I also introduced in other videos. It’s an approach that learns to merge information from various inputs with an intelligent, learned weighting system, giving more weight to useful information, and it’s particularly powerful compared to simply adding or concatenating values together. We do this with a long training process teaching the algorithm to disentangle the pose information from the clothing on each image thanks to the four processed versions of our two input images and properly extract the relevant information and combine them realistically.
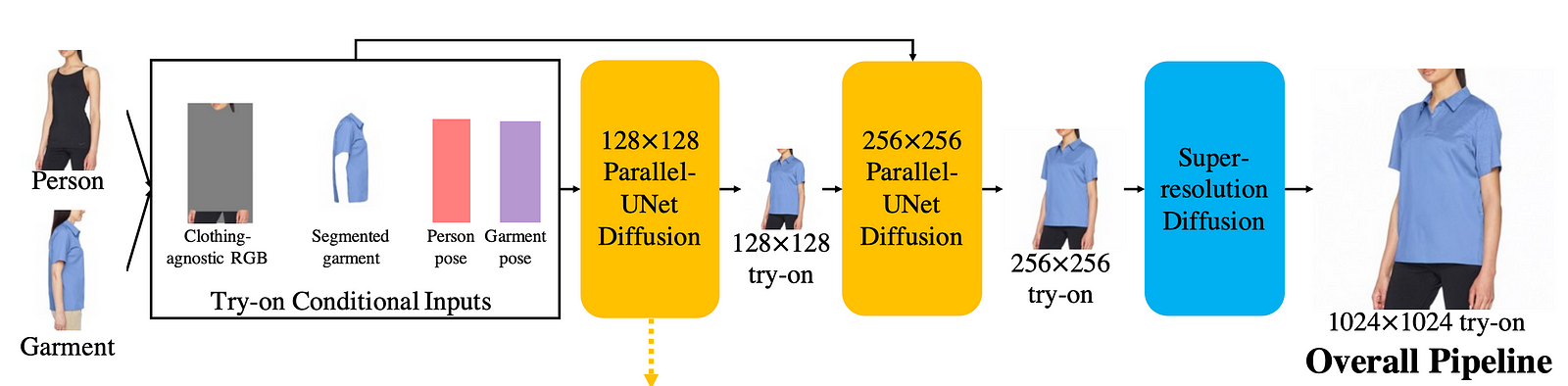
But we are not done here. Even though we have our final results, it is still quite low-quality because of the computation needed to produce a higher-definition image. To get it to a final beautiful image, we send it in a very similar Parallel-UNet model along with all the processed information we already sent the first model and start over, focusing on re-generating the same image with more pixels. We use a similar model but ask for a different goal of not only adding pixels to the image based on what is already there but also extrapolating a bit from the inputs we had, improving the results compared to simply trying to upscale our first try-on version.
It’s now already much better but still quite low quality. Here is where we use a proper upscaler now that we have enough details in our 256x256 image. Here they use another pre-trained model to make the final image of proper high quality. It’s basically the same upscalers used by MidJourney, Imagen, and other generative AIs. I also introduced this kind of diffusion super-resolution model in previous videos if you are curious to know the inner-working of those! And voilà! You now have your final proper high-definition image with a new piece of clothing to see how well it fits you!
The results are definitely not perfect and don’t expect them to work every time with perfect realism for each piece you will try, but they are for sure impressive and closer to reality than all previous approaches! One main limitation is that, as we’ve seen, the approach is dependent on the different pre-trained models used, like our segmenter and upscaler, which can drastically affect the results if they fail in their respective tasks.

Fortunately, just like with the SAM model, those are now extremely powerful, and dissociating them from the main model makes the task much easier. Another limitation comes from the clothing-agnostic image they generate, which will cause some issues when respecting your personal body features like tattoos and muscles that may not be accurately shown and resemble the garment body a bit more. The fit is thus far from perfect, but they did mention the focus was on visualization of the try-on, which we can see is near perfection. I’m pretty excited to see a follow-up from this work with a focus on the fit and person’s body aspects.
Of course, this was just an overview of this great new paper that I recommend reading for more information and a deeper understanding of the approach and to see more results. The link is in the description below. I hope you’ve enjoyed this video, and I will see you next time with another amazing paper!
References
Zhu et al., Google Research, CVPR 2023: TryOnDiffusion, https://arxiv.org/pdf/2306.08276.pdf
More results on the project page and video: https://tryondiffusion.github.io/, https://youtu.be/nMwBVLjRdcc